
Building a Mission-Critical Architecture for Healthcare with Cloud Foundry

Other recaps: Day 1 | Day 2 | Day 3 | BOSH Day | Top 100 Quotes
On the second day of the Cloud Foundry Summit 2016, Sergey Sverchkov (Software Architect, Altoros) talked on bringing Cloud Foundry and IoT into healthcare. Entitled, “Taking the Cloud to Extremes: Scaled-Down, Highly Available, and Mission-Critical Architecture,” his presentation featured a high-load, HA system based on Cloud Foundry and microservices.
Business requirements
Sergey started with the business requirements that would need to be met in order to successfully create such a solution catering to healthcare. These include:
- Thousands of devices, hundreds of customers
- Connecting devices and users located at customer sites
- Collecting, processing, and visualizing device data
“The cloud solution should reduce time to deliver, upgrade, and support healthcare applications for clients.” —Sergey Sverchkov, Software Architect, Altoros

Sergey Sverchkov, Software Architect, Altoros
- The solution should be available as a private regional cloud:
- May be operated by a third-party
- Addressing specific region regulations
- Serving clients and providing region proximity
- A “scaled-down” version for on-site deployments:
- Cost-effective
- Easy remote maintenance
- Backup data to the regional cloud
- Consider implementation restrictions (e.g., limited resources for on-site deployment)
- Review and approval by government agencies:
- Open source technologies and products
- Unified architecture for regional and local clouds
Since the solution is going to be implemented across different geographical regions, he emphasized the importance of “addressing specific regulations for each region.”
According the Sergey, the scaled-down version will be a good option for “customers who are sensitive to data locality. [They] can install the solution and keep all the data inside their data center.”
Here, Sergey points out the importance of having the architecture for the regional cloud and the scaled-down version to have similar or identical architectures. He notes that “when you have this type of implementation for different scales of deployment, it reduces the time to deliver the solution to the market.”
“Open components also make it possible to easily extend the functionality of the platform and the products that are used in the solution.” —Sergey Sverchkov, Altoros
High availability and security above all
Of all the requirements Sergey mentioned, two stood out the most: high availability and security. In the healthcare industry, having your data and devices unavailable or compromised for even a limited amount of time is simply not at option.

With the solution being designed for healthcare use, having high availability is of utmost importance. “[This] means that all apps and services, as well as hardware and the infrastructure platform must be available all the time,” says Sergey.
Data security is also paramount in healthcare. In most cases, customers can connect to the cloud through secure VPN tunnels but for smaller customers, the cloud can provide connectivity without a firewall.
Infrastructure: OpenStack vs. VMware
Having to build a private cloud, Sergey mentioned choosing between OpenStack and VMware.
- VMware vSphere is about virtualization:
- ESXi is the only supported hypervisor.
- vCenter is used for management.
With VMware, Sergey points out that “vSphere is about virtualization and management of virtual resources. All VMware products are licensed and proprietary.”
- OpenStack is about cloud:
- Storage, network, and compute services
- Security groups and access control
- Projects and quotas
- Supports KVM, ESXi, and QEMU
Given the two choices, OpenStack was chosen.

“OpenStack is open source and includes components that allow for building storage, network, and compute services in the cloud.” —Sergey Sverchkov, Software Architect, Altoros
Another factor that favored OpenStack over VMware was cost. As a rough estimation, the cost of having five nodes using OpenStack would be around 25% cheaper compared to using VMware.
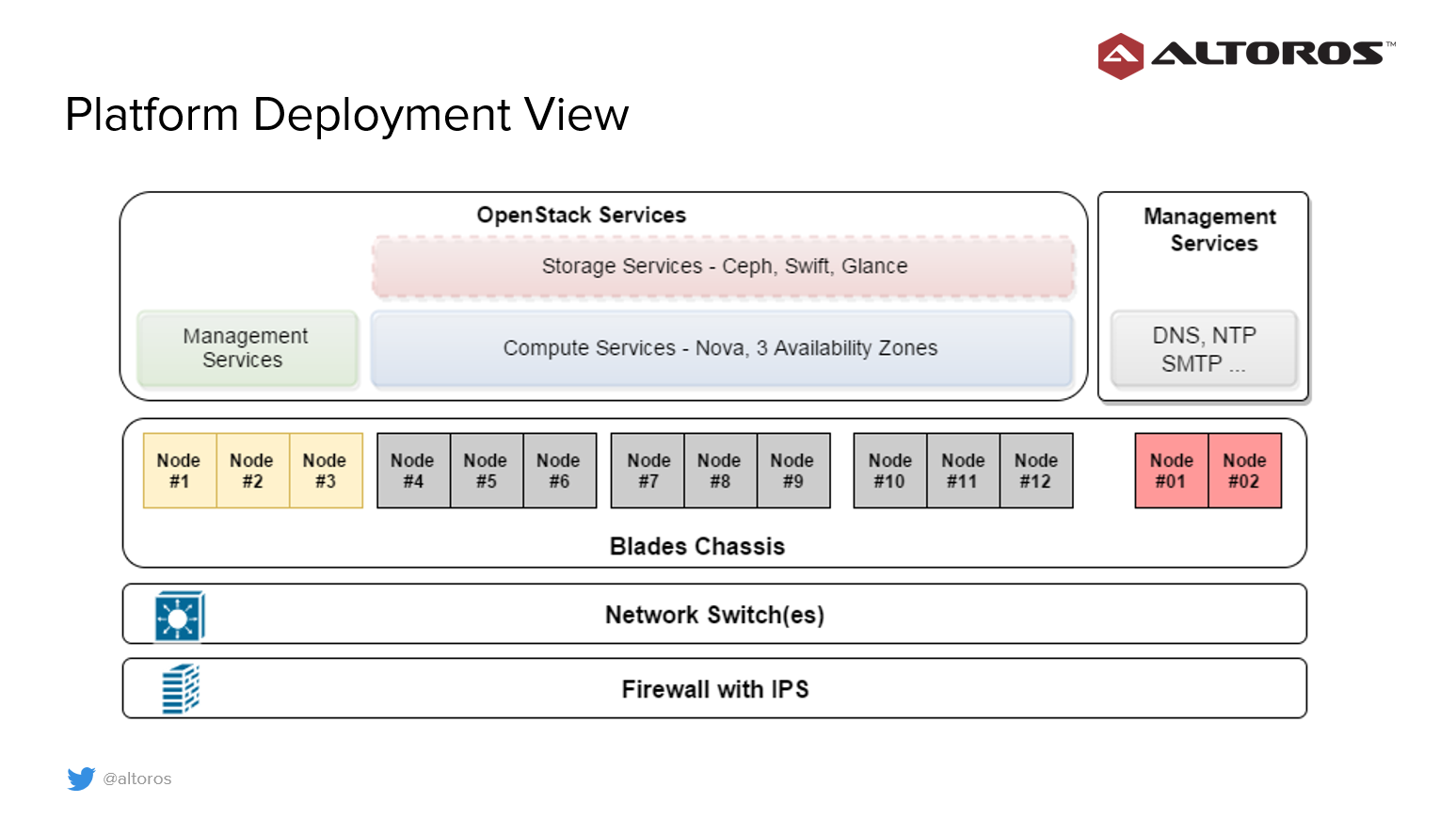

Sergey brings up some key considerations during the OpenStack deployment:
- Create identical availability zones for compute and storage devices
- Configure OpenStack Ceph for persistent volumes and ephemeral disks to enable support for live VM migration
- Free up enough capacity of around one physical node in every availability zones
- Increase default limits for security groups, security rules and volumes
- Evaluate CPU overcommit ratio
“Recommended CPU overcommit for OpenStack is from 1.5 to 2, but 4 works for us” | Sergei Sverchkov of @Altoros, #CloudFoundry Summit
— Mzh (@uzzable) May 24, 2016
Cloud Foundry as the platform
According to Sergey, the solution was based on the microservices architecture and as such, needed an application platform that would manage that system effectively—enter Cloud Foundry. Here’s some of the reasons why Cloud Foundry was chosen:
- Easy to implement the microservices architecture
- Runtime automation
- Organizations, users, spaces, and security groups
- Health checks, load balancing, and scaling
- Choice of infrastructure: AWS, OpenStack, and VMware
“[Cloud Foundry] automates up to 90% of all routing work related to application life-cycle management,” said Sergey. “It is a complete platform that supports traditional application runtime automation and also Docker containers.”
“With Cloud Foundry, new features and apps can be released a lot faster.”
—Sergey Sverchkov, Software Architect, Altoros
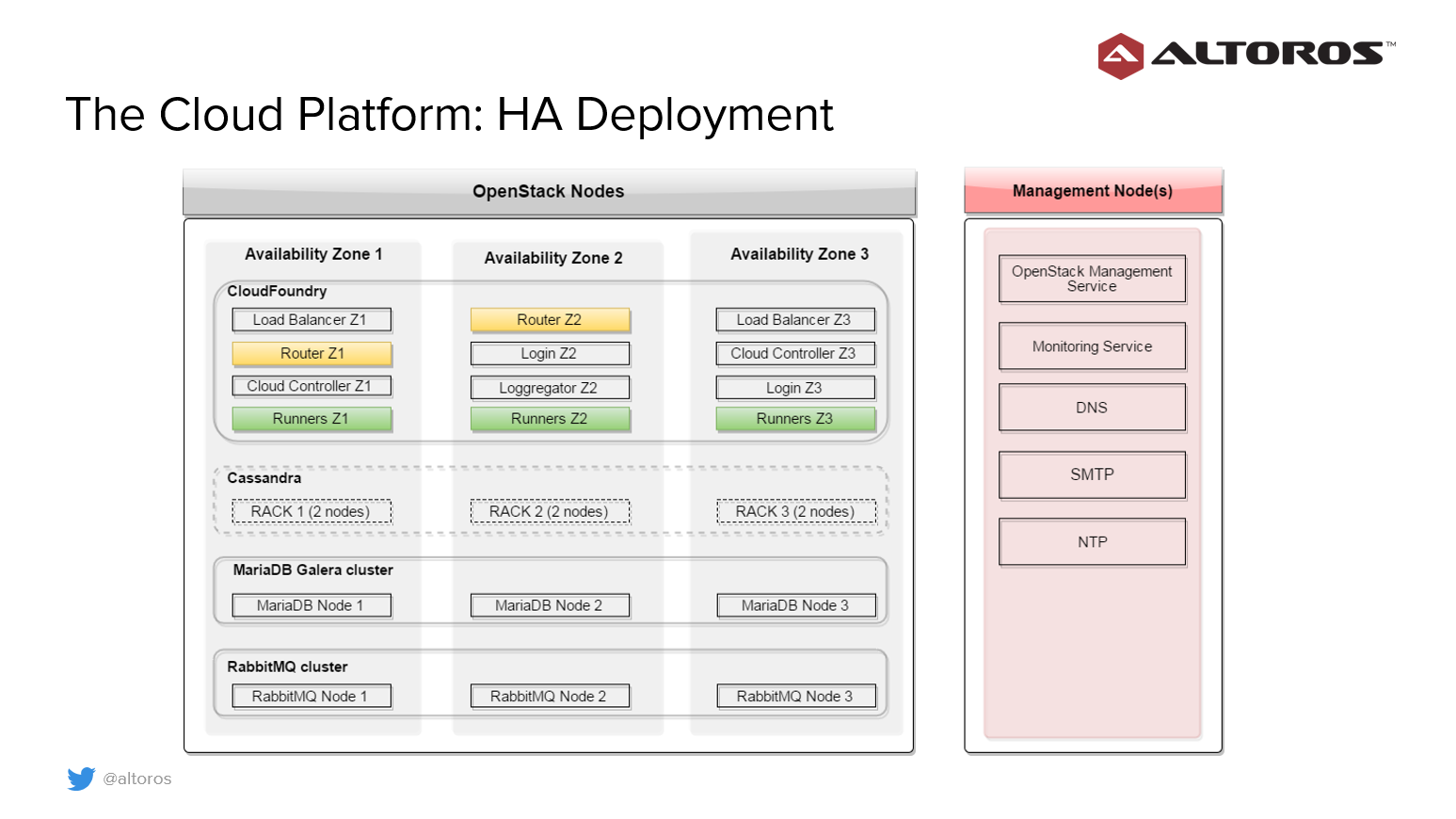
Sergey points out that there are three availability zones that are actually three groups of physical nodes in chassis. Redundancy is ensured on the service level by distributing services across these availability zones.
We deploy CF runners to 3 availability zones to distribute apps evenly to all HW nodes | Sergei Sverchkov of @Altoros, #CloudFoundry Summit
— Mzh (@uzzable) May 24, 2016
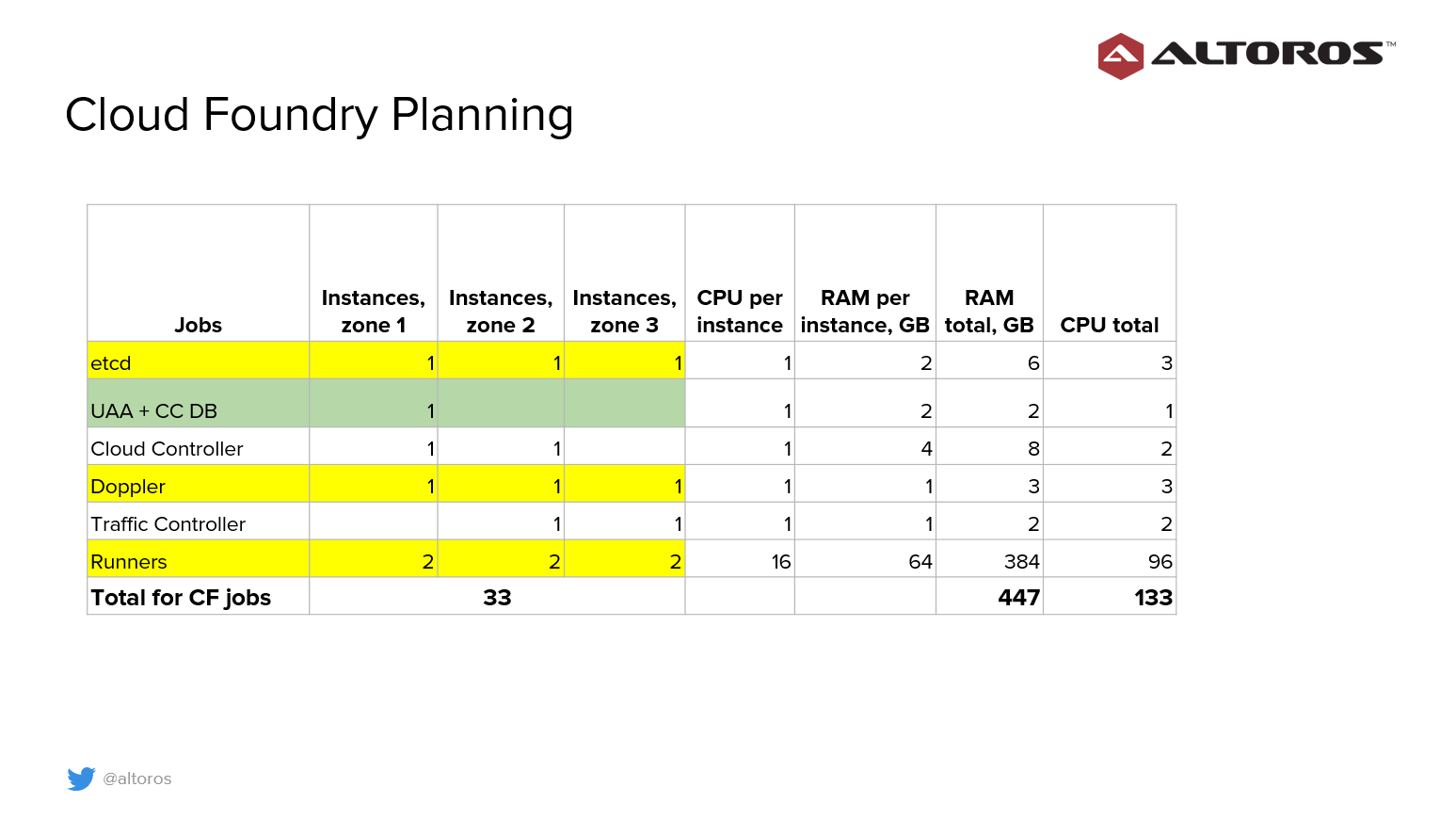
Other services included
Sergey elaborated on the other elements present in the stack.
- Cassandra. Scalable, redundant, and master-less data store.
- MariaDB Galera. Relational database cluster for structured data with low velocity.
- RabbitMQ. Provides queuing and messaging for different applications.
- Elasticsearch, Logstash, Kibana (ELK). Provides application logs aggregation and indexing.
Cassandra storage
Sergey details how Cassandra operated within OpenStack Ceph with replication with data blocks distributed among all storage nodes.
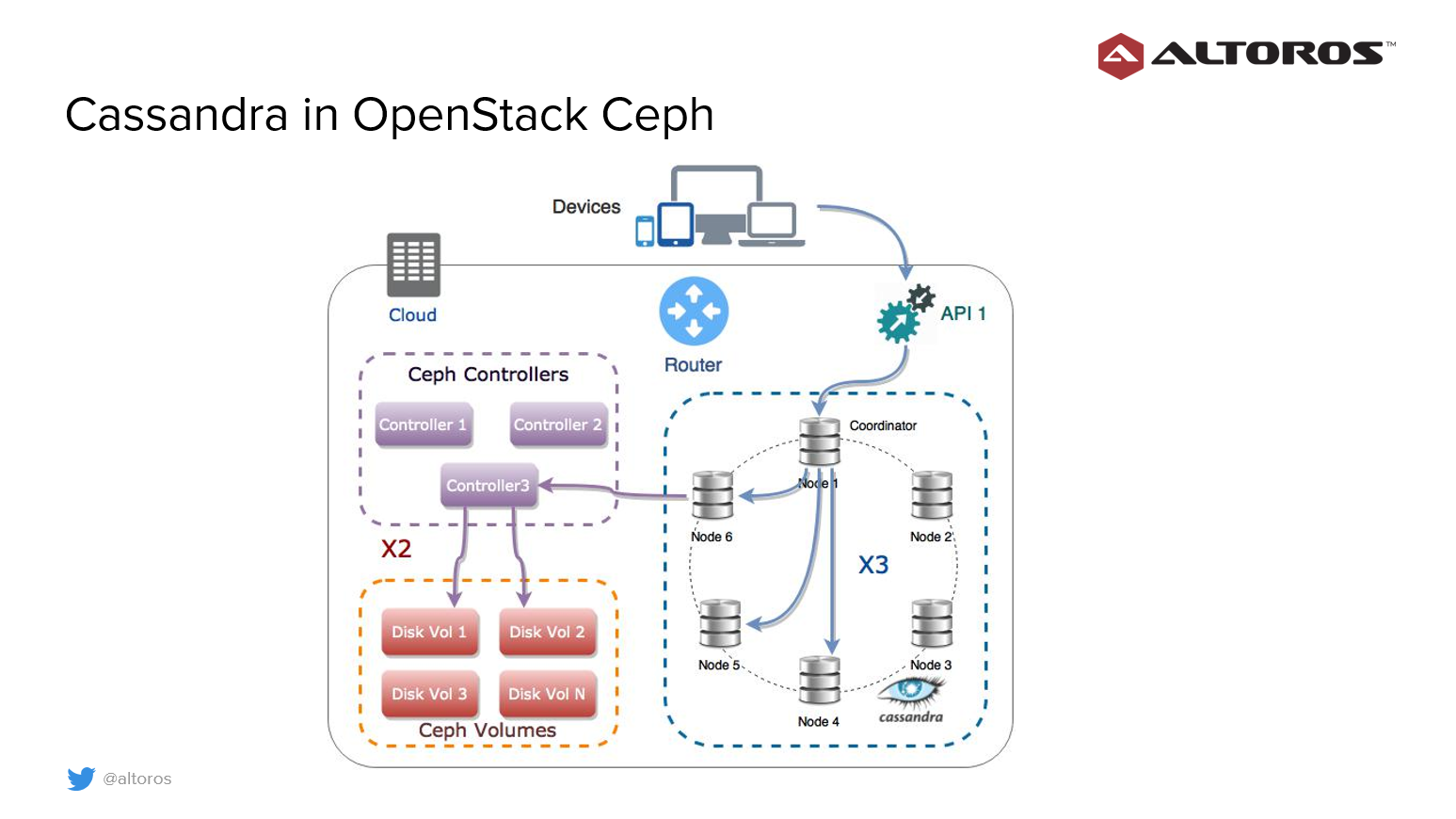
In that scenario, Sergey explains a single data read request triggers several network operations.
- The application calls the Cassandra coordinator note.
- The Cassandra coordinator contacts the Cassandra data node that stores the requested data row.
- The compute node talks to the OpenStack Ceph controller.
- The Ceph controller reads data blocks from the OpenStck storage nodes.
Why use Cassandra in OpenStack Ceph?
Sergey listed some pros and cons of using Cassandra in OpenStack Ceph.
- Pros:
- Automation. All cloud services are in OpenStack.
- Ceph is distributed and replicated storage.
- Low cost compared to hardware SAN.
“With Ceph, all cloud services are in OpenStack. This simplifies deployment automation and management, because services can be deployed and managed for example by BOSH” —Sergey Sverchkov, Software Architect, Altoros
- Cons:
- The replication factor is equal to 6. (Cassandra’s recomended replication factor is 3, multiplied to an additional factor of 2—due to two Ceph storages.)
- Cassandra performance is impacted by network performance.
“Cassandra performance depends directly on network performance. So, it is recommended to use a 10-Gb or faster network for connecting OpenStack storage nodes.” —Sergey Sverchkov, Software Architect, Altoros
Cassandra performance benchmark
Cassandra was benchmarked in OpenStack to gauge its capacity to meet requirements. These were the configurations used on Cassandra Stress-Test Tool on a cluster of six nodes:
- OpenStack configuration:
- 1-Gb network
- One CPU per node (E5-2630 v3 2.40 GHz)
- 2.0 TB SATA 6.0 Gb/s 7200 RPM for Ceph
- Cassandra configuration:
- Node: eight vCPUs, 32 GB of RAM
- Six nodes in three availability zones; two nodes per availability zone
- A simple strategy with a replication factor of 3
- Cassandra stress-test tool
Testing was conducted with one table with an approximate duration of 300 seconds.
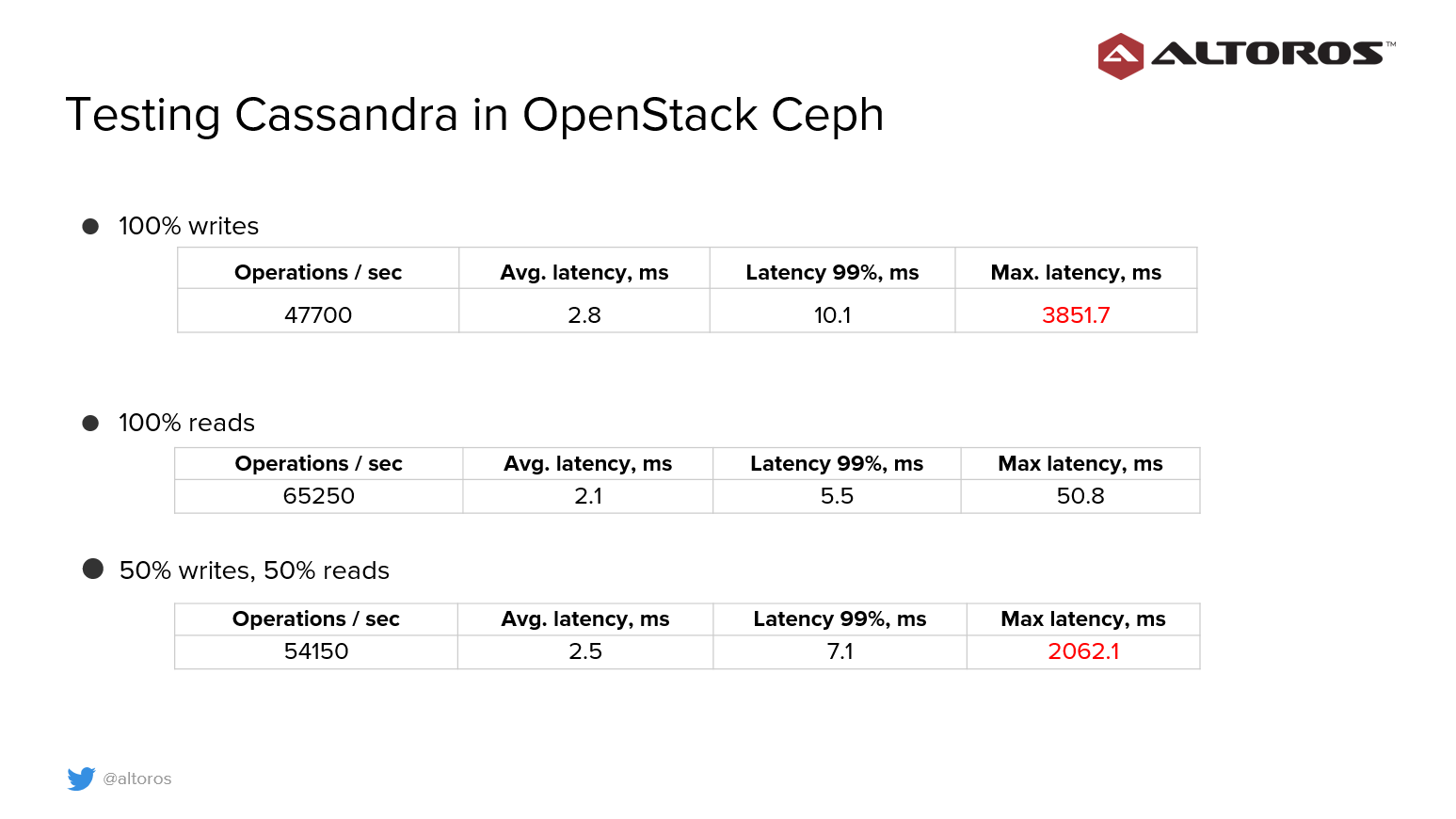
Satisfied with the results, Sergey offered additional recommendations to improve on Cassandra storage.
- Cluster and node sizing:
- Effective data size per node: 3–5 TB
- Tables in all keyspaces: 500–1000
- 30–50% of free space for the compaction process
- DataStax storage recommendations:
- Use local SSD drives in the JBOD mode
Sergei Sverchkov of @Altoros recommends to keep 30-50% free space on Cassandra node for compaction process on #CloudFoundry Summit
— Mzh (@uzzable) May 24, 2016
Some contributions of Altoros to Cloud Foundry
Here are the tools created during the project:
- Cloud Foundry Cassandra Service Broker (GitHub repo)
- Improvements to the ELK BOSH release and CF integration:
- RabbitMQ input, Cassandra output for Logstash
- Logstash filters
Learn more from the session’s recording.
Want details? Watch the full video!
For more information, view these slides used during the presentation.
All CF Summit recaps:
- CloudCamp Attracts 150 Attendees on the Eve of the Cloud Foundry Summit
- Cloud Foundry Summit 2016, Day 1: Ecosystem Is Growing
- Cloud Foundry Summit 2016, Day 2: Ops Are Large and in Charge
- Cloud Foundry Summit 2016, Day 3: Blockchain and Govs Enter the Scene
- BOSH Day Concludes Cloud Foundry Summit 2016
- Top 100 Quotes from the Cloud Foundry Summit 2016
- Digital Transformation Using Cloud Foundry—What Works and What Doesn’t
About the expert






