What It Takes to Build and Train Neural Networks for Autonomous Vehicles

Why building a safe autonomous car is a challenge
In 2015, the National Highway Traffic Safety Administration revealed a staggering statistic—94% of vehicle accidents were caused by human error. This has become another driver for using artificial intelligence in the development of safe autonomous vehicles.
Under the hood of self-driving vehicles are neural networks, which high accuracy is critical as otherwise it may result in dire consequences. Building and training neural networks to achieve the desired accuracy is anything but a simple task.
First, neural networks have to be trained on a representative data set. In its turn, a data set must comprise a sufficient amount of any possible driving, weather, and simulation patterns. As one may guess, this means petabytes of data—and it yet has to be collected. Here comes the trouble of developing an extensive data set as no one will do it for you or share priceless information for free. Surely, there are some data collections available publicly, however, they may not be enough or may not cater for your needs.
Another question is how much data makes the game worth playing?
Aside from data troubles, the complexity of the neural networks themselves is back on the agenda. To train on huge data sets, learn from them, and be aware of the gained experience, neural networks need to have a sufficient number of parameters. A compromise for complying with this requirement is a sophisticated network architecture.
On top of these all, one needs comprehensive computational powers to enable training. Additional engineering challenge pops up when you scale the size of a data set by a factor of n, the computational powers need to be scaled by a factor of n².
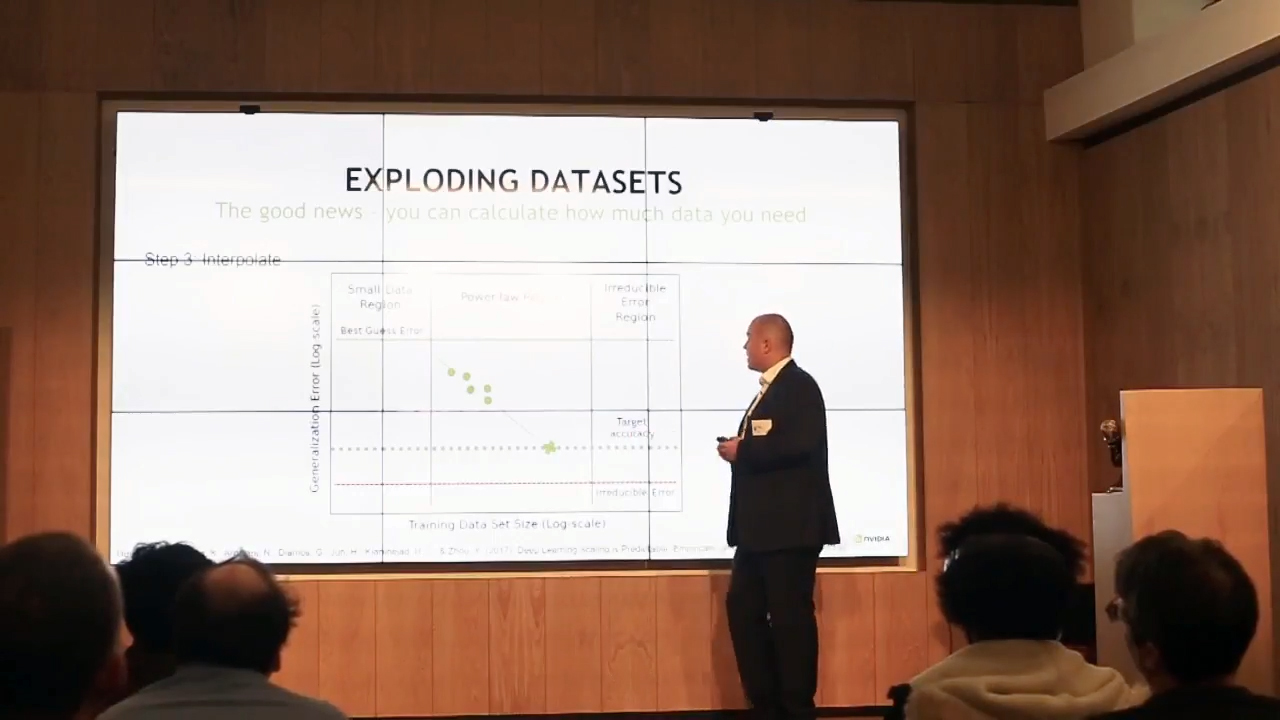
At a recent TensorFlow meetup in London, Adam Grzywaczewski of NVIDIA delved into the challenges of building and training neural networks for self-driving vehicles and outlined the approaches to tackle the issues.
 Adam Grzywaczewski at the TensorFlow meetup in London (Image credit)
Adam Grzywaczewski at the TensorFlow meetup in London (Image credit)“For the first time in human history, we have a tool that—given enough data—can achieve an arbitrary accuracy to solve almost any problem. It makes complex problems easy, and it makes impossible problems just expensive.” —Adam Grzywaczewski, NVIDIA
Extensive computing powers needed
In creating a machine learning model, it is important to first know how much data is needed. This amount can be estimated by the following three steps:
- set a minimum viable accuracy
- conduct experiments with varying data sets
- interpolate how much data is needed to achieve target accuracy
 The size of a data set has a direct impact on the accuracy (Image credit)
The size of a data set has a direct impact on the accuracy (Image credit)This increase in performance scales logarithmically, so while you may not need a comprehensive data set to achieve 80–90% accuracy, you will definitely require a large data set to reach near perfect accuracy. This is the primary reason why automotive manufacturers are investing heavily in the race to develop safe and secure self-driving vehicles.
“99.99% accuracy is expensive, but it is important in some cases. We want self-driving cars to be robust and not harm people.” —Adam Grzywaczewski, NVIDIA
Once the amount of data needed is known, the infrastructure and time needed to process the necessary data sets can be estimated. Adam theorized a scenario where NVIDIA’s DGX-1 systems are used to process the data collected from 100 vehicles.
In this scenario, each vehicle in the fleet has multiple sensors to collect data. Under the assumption that each vehicle will generate 1+ TB of data per hour and will do so for 8 hours a day during a 260-day work year, the raw data collected from the entire fleet will amount to 204.8 petabytes. Once preprocessed, the total data may be reduced to 104 terabytes.
Using the DGX-1 as a constant, the difference in training time using different machine learning models can be seen. In this case, using a single DGX-1 system, training time would take 166 days, 113 days, and 21 days on the Inception V3, ResNet 50, and AlexNet models, respectively.
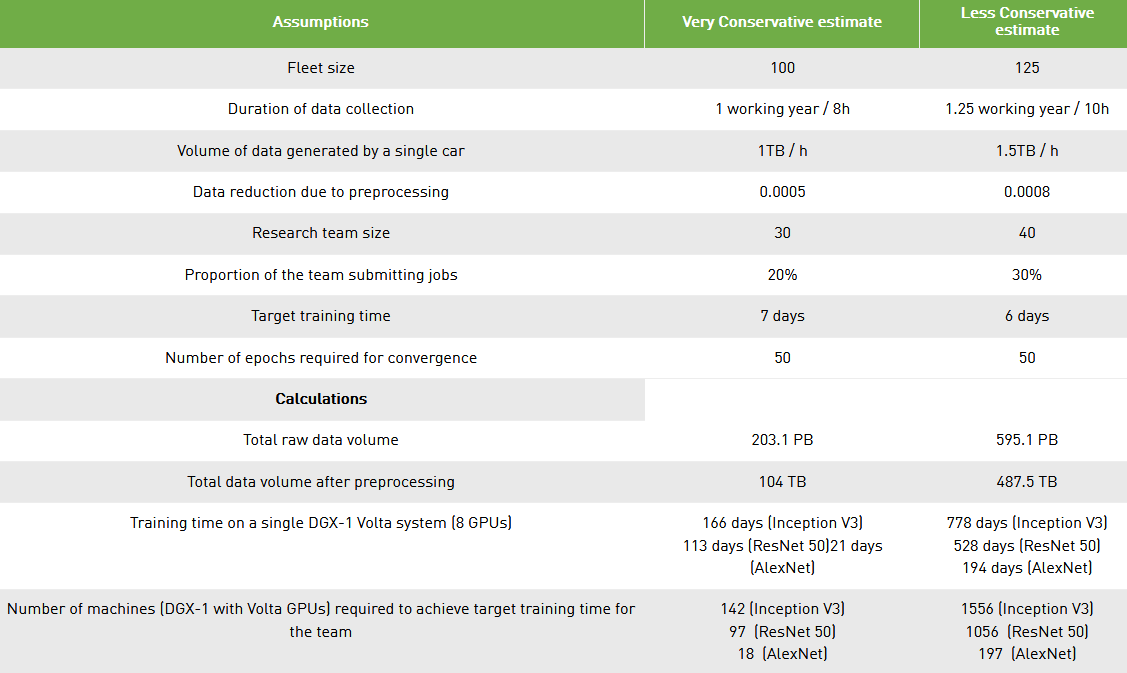 A single GPU isn’t enough to reach the target training time (Image credit)
A single GPU isn’t enough to reach the target training time (Image credit)It is important to note here that simply adding another DGX-1 system does not reduce training time by 50%. Computing power simply does not scale linearly with the number of the processors involved. In the exemplified scenario, shortening the training time to the seven-day target would require 142 systems for Inception V3, 97 for ResNet 50, and 18 for AlexNet.
Gather the right tools
After establishing a baseline, the next step involves procuring hardware, software, algorithms, and people. Of these four, hardware is the most trivial as there are multiple vendors on the market. Even so, there are some important points to follow:
- The CPUs and memory should be able to keep up with GPUs to minimize GPU idle time.
- One should ensure enough storage space to continuously feed data into GPUs.
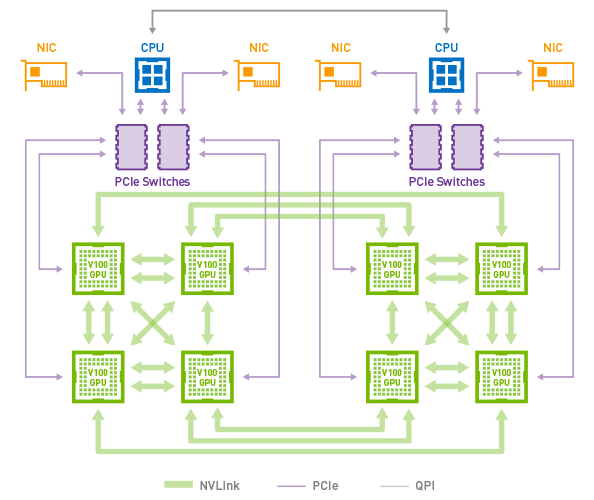 The NVLink topology of DGX-1 with Volta GPUs (Image credit)
The NVLink topology of DGX-1 with Volta GPUs (Image credit)Next is choosing which software and algorithm to deploy. While any deep learning framework deployed will be able to process data, different frameworks will have varying rates of improvement. To minimize the need for maintenance and optimization, Adam suggested trying out a couple of tools:
- Deep learning containers to simplify the deployment of GPU-based applications. These frameworks are updated on a monthly basis.
- Horovod, which is a distributed deep learning training framework for TensorFlow. It was developed by Uber under a research on self-driving solutions and was then open-sourced.
“It makes a difference how you build your deep learning frameworks. It also makes a difference how you build your optimization process. Doing it incorrectly leads to a dramatic degradation in performance.” —Adam Grzywaczewski, NVIDIA
Finally, in any deployment, you need people who are passionate about the project. You can also check out Adam’s blog post with further investigation into the topic.
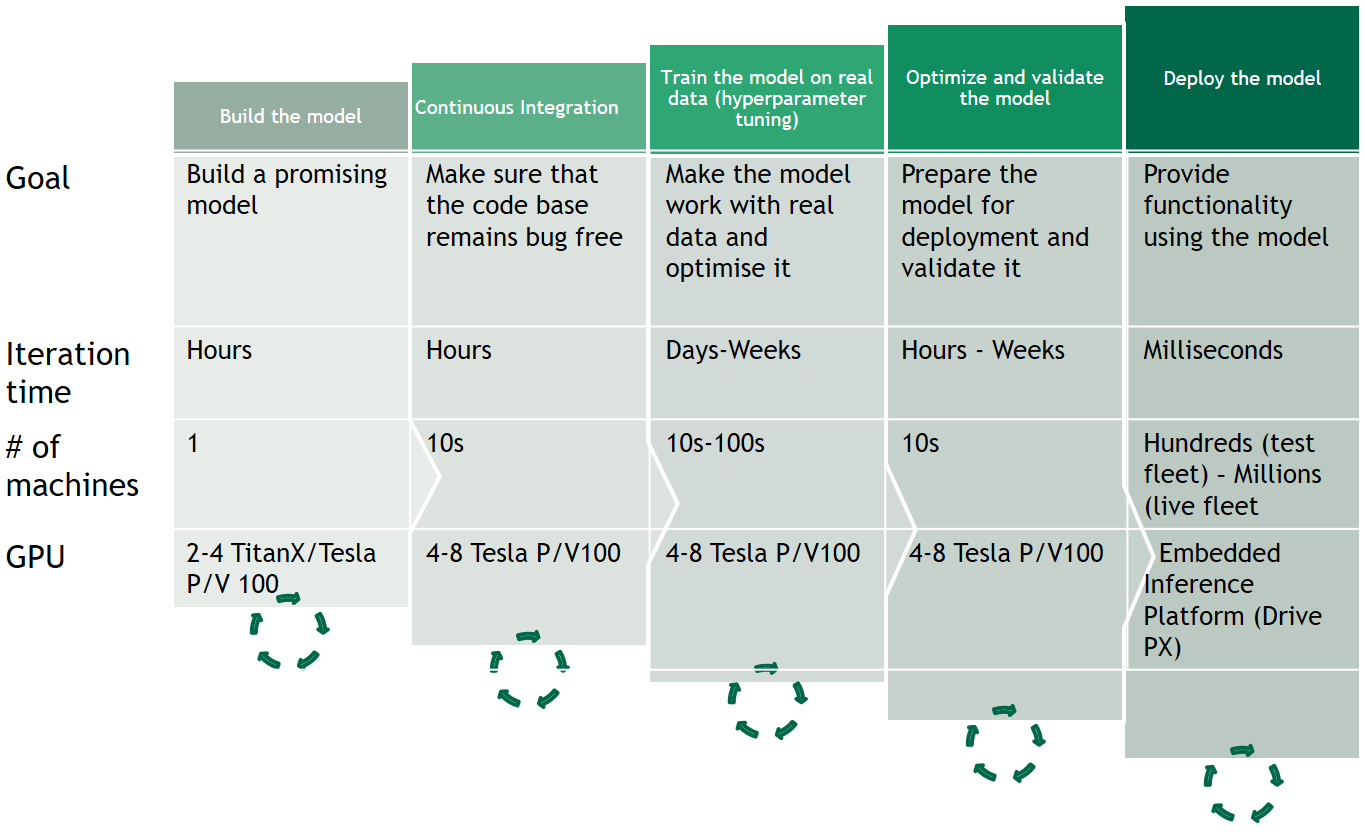 The scaling of an artificial intelligence model at different stages of development and tests (Image credit)
The scaling of an artificial intelligence model at different stages of development and tests (Image credit)
The race to safe autonomous driving
Despite the difficulties involved in the development of autonomous vehicles, several organizations are funneling vast amounts of resources to create a truly safe model. Waymo, the Google’s subsidiary focused on autonomous driving, began development in 2009. For the last nine years, the company has been collecting data from its self-driving cars located in 20 different cities in the United States.
Waymo has now amassed over 7 million miles worth of self-driven data in addition to over 2.7 billion miles of simulated driving data gathered in 2017. Despite all this, over 25,000 autonomous miles are driven and collected every week to continuously improve its driverless vehicles.
 A Waymo autonomous vehicle sees 360° up to three football fields away (Image credit)
A Waymo autonomous vehicle sees 360° up to three football fields away (Image credit)Apple and Volkswagen are teaming up to create self-driving shuttles for their workers. Apple has been testing its fleet of 62 autonomous cars in California since April 2017. Honda is also relying on artificial intelligence to improve car safety. Yet, another example is Mercedes-Benz / Daimler, who set the goal to deliver emission-free, self-driving, and connected vehicles by 2020.
Heavily driven by the automotive industry, artificial intelligence is evolving, with more and more tools and platforms appearing each year. At the same time, the question of safety stays relevant. To achieve it, car manufactures will need even more computational resources than they are using today.
Want details? Watch the video!
Table of contents
|
Further reading
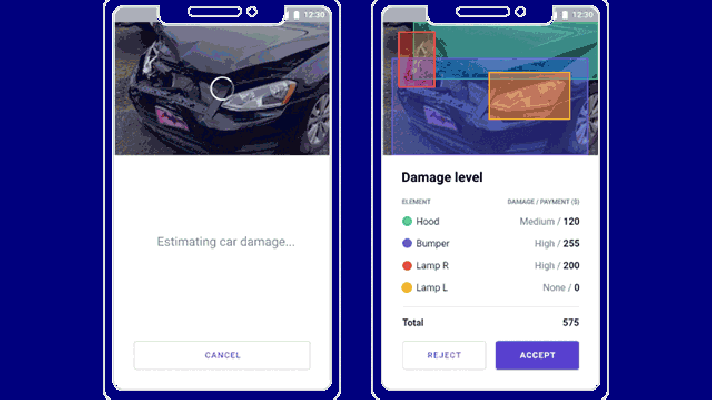
- Automotive Insurance with TensorFlow: Estimating Damage / Repair Costs
- Using Machine Learning and TensorFlow to Recognize Traffic Signs
- Performance of Distributed TensorFlow: A Multi-Node and Multi-GPU Configuration
About the expert