
Why Estimating Car Damage with Machine Learning Is Hard

The claims process taking too long
According to Verisk, a data analytics company, auto insurers in the U.S. lose $29 billion annually due to errors and omitted information. Though the sources of this claim leakage vary, inaccurate estimation of vehicle damage after an accident is one of them. Therefore, it becomes crucial to improve the accuracy of payout calculations in order to reduce this waste.
However, the process of assessing damage is both effort- and time-consuming with multiple parties involved. While an insurer is obviously responsible for covering the repair cost, the estimation itself is usually done by a body shop. The whole procedure involves experts from both sides, which often results in weeks or months spent on each case.
Apart from being a time sink, manual inspection is also highly prone to human error, which can lead to inaccurate or unfair payouts.
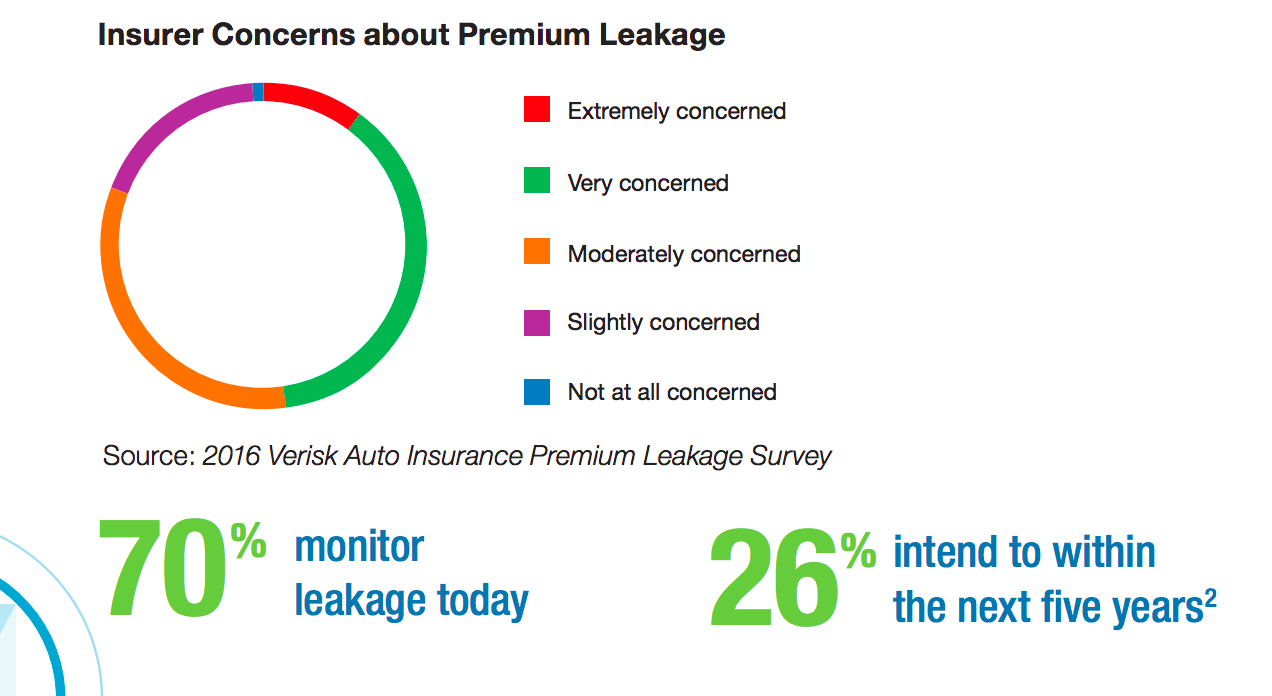 Premium leakage as a major concern for insurers (Image credit)
Premium leakage as a major concern for insurers (Image credit)Machine learning is already being employed across multiple industries to automate the processes that are slowed down by manual, repetitive steps. With advanced algorithms, techniques, and frameworks under the hood, AI tools can accelerate the process of recognizing damaged vehicle parts, assessing damage, making predictions about what kind of repair is needed, and estimating how much it may cost. However, what does it take to implement such a solution?
Obstacles in the way
While building a solution capable of addressing the enlisted needs, developers may encounter certain issues. These are some of the challenges the Altoros team faced when building an AI solution for car damage assessment:
1. Finding a proper data set
Training machine learning models requires a sufficient data set of relevant images. The more varied the images are, the better the model will be able to classify images appropriately.
In the context of car damage assessment, obtaining a substantial amount of images is a challenge, since there is no public database for images depicting damaged vehicles. While it may be possible to come up with a raw data set through web scraping, working with car insurance companies—which already have numerous images of broken car parts—may also be a feasible option. So, a company needs to evaluate the most optimal way in terms of ROI or time by deciding whether to buy the data set, get it from an industry partner, or to build/collect it from scratch.
Even having obtained a collection of images, one should ensure the pictures satisfy the demands for size, quality, etc.
2. Preprocessing
Preprocessing image data sets is a crucial step in speeding up and obtaining better training results for models. This activity may span a variety of tasks: applying filters, removing noise, enhancing contrast, downsampling images, etc. With proper preprocessing, photos that are too blurry, too dark, or too bright can also be utilized. This way, photos where a car is not initially detected or looks ambiguous can be adjusted to work.
For instance, this can be done with OpenCV, one of the most used machine learning libraries for image preprocessing. It has over 2,500 optimized algorithms for identifying objects and putting pictures together to create a high-resolution image of an entire scene.
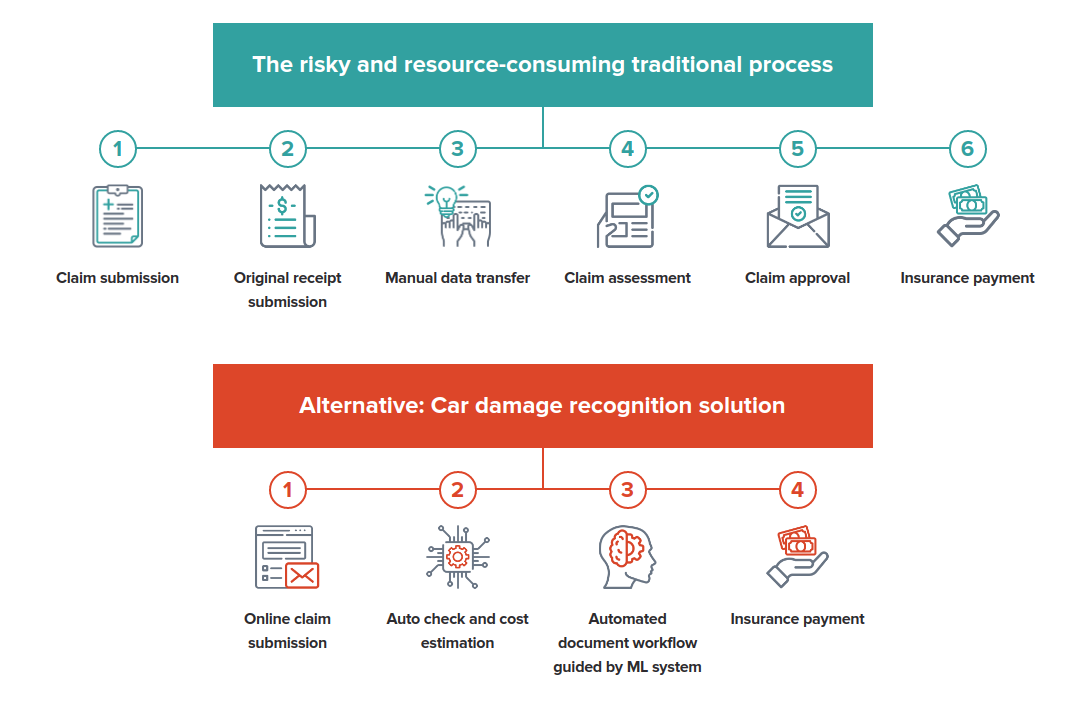 Automation vastly speeds up car damage assessment (Image credit)
Automation vastly speeds up car damage assessment (Image credit)
3. Building a model
After you have a quality data set at hand, there are still some considerations when building a machine learning model.
- Creating and training a model takes time. The main goals here can be associated with a) detecting a vehicle and b) distinguishing between its exterior parts in the photo. Aiming for descent accuracy, numerous corrections may be needed: e.g., more input data, improved algorithms, etc. Eventually, the process may take weeks or even more, taking into account all the necessary adjustments.
- As a result, computing powers for the model to process images at an acceptable rate may become costly—thousands of dollars worth.
- Finally, finding means to unbiasedly estimate vehicle damage can also be tricky.
How to handle these? To detect a vehicle in the photo, a pretrained TensorFlow-based collection of models can be utilized. In particular, the faster_rcnn_nas neural network helped us to address a variety of specific detection tasks—for instance, to understand how much space a car takes in the picture.
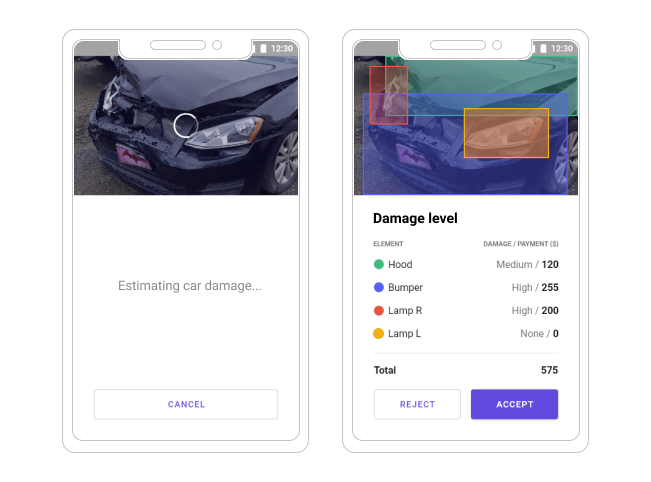 Evaluating a damage with the AI solution from Altoros
Evaluating a damage with the AI solution from AltorosThe ssd_resnet_50_fpn_coco neural network can be responsible for detecting particular exterior parts.
 Estimating the damage of individual exterior parts (Image credit)
Estimating the damage of individual exterior parts (Image credit)For estimating the damage extent, our team initially applied binary classification and then ran the data set through machine learning algorithms built upon the MobileNetV2 neural network. At the end of the day, the solution achieved 90% of precision in both detecting the damaged car parts and assessing the loss incurred.
“We built a mobile app that enables a user to take pictures of a car right at the accident scene. The mobile app guides the user on how to take high-quality pictures and then sends the pictures to our back end, which runs on the Intel architecture. We fed sets of pictures into a single deep learning model and then trained the overall model for this set of inputs.”
—Vladimir Starostenkov, Machine Learning Architect, Altoros
4. Optimizing performance and costs
As insurance companies have to deal with damage assessment on a daily basis, the working solution also needs to demonstrate resonating performance, so it won’t take weeks to seal the deal. Ideally, a car driver should be able to get an approximate damage estimate right away.
To maximize performance, an engineer can rely on the capacities of GPU or parallel computing to the fullest. The importance of hardware characteristics cannot be neglected, as well.
For instance, initially, our AI solution utilized open-source TensorFlow, the Python programming language, and some other machine learning libraries. We also implemented two core pipelines:
- a machine learning pipeline responsible for training, evaluating, and building ML models
- an analytical pipeline responsible for employing the created ML models in production
Both pipelines ran on commodity hardware with GPU and achieved great performance. However, there was an issue with processing images of high resolution (2,500×3,000 pixels and 300 dpi) at reasonable response time. This happened due to relatively small memory volumes of traditional GPU devices, such as NVIDIA Tesla—up to 32 GB only.
To increase the speed of image-per-second processing and precision of damage estimation, the analytical pipeline was moved to the Intel Xeon Skylake platform with 96 vCPUs in Google Cloud Platform. The Intel Xeon Skylake platform is highly parallelized, and each of its execution units is capable of working at huge volumes (up to 1 TB) of unified access memory. This allows for dealing with multiple high-resolution images simultaneously. Collaborating with Intel, Altoros managed to increase the solution’s processing capacity by 2x.
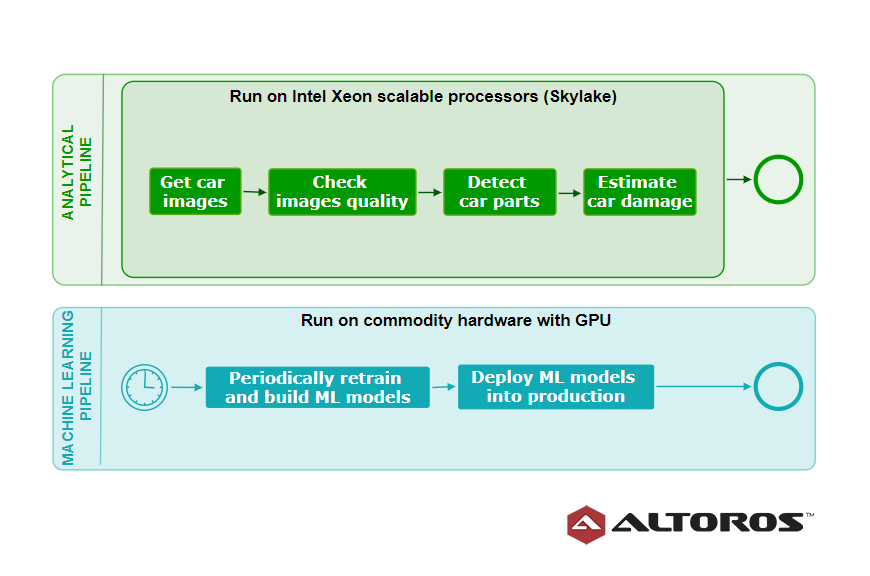 A high-level view of pipelines at the training and inference stages
A high-level view of pipelines at the training and inference stagesIn our case, the idea was to parallelize the analytical pipeline running artificial intelligence algorithms and machine learning models responsible for identifying different car parts. Now, the improved pipeline relies on Intel’s distributions of Python and OpenVINO toolkit. Using Intel’s Math Kernel Library and Advanced Vector Extensions, both Python and OpenVINO enable a single instruction to be executed across multiple data.
The TensorFlow models can be easily converted into the OpenVINO models, which support asynchronous inference operation. Employing the Intel Xeon Skylake platform, the OpenVINO-based models are able to simultaneously process multiple images and recognize car parts per image in less than a second.
5. Privacy
When processing photos for damage estimation and sharing between parties, it is critical to ensure that the privacy of car owners remains intact. In most cases, it is possible to encounter images containing vehicle license plates, which may be used to identify individual car owners. This may cause privacy concerns, especially in European regions where the General Data Protection Regulation (GDPR) is enforced.
To avoid complications, it is worth following certain guidelines.
- Vehicle owners need to be aware about data collection, the reasons for data processing, and how long their data is being retained.
- Data cannot be kept indefinitely and should be deleted upon the owner’s request.
If your solution involves integration with third parties, such as medical institutions, insurance companies, etc., data should be shared in a secure way—requiring consent, as well. Not to mention the creation of a safe data storage, encryption, or even using blockchain, if needed.
The bottom line and lessons learned
While machine learning helps to automate car damage assessment, the time and resource investment is significant. Without proper infrastructure and equipment in place, your project may not meet its goals. So, what are the recommendations and lessons learned?
- Building up extensive and diversified data sets requires collaboration of multiple parties: drivers submitting quality photos of their cars, insurance companies sharing the available data (with a consent of the insured), and integration with body shops involved in the repair process.
- For accurate image recognition, the data set should feature high-resolution photos, which are not blurry, light-struck, or taken from an inappropriate angle. The associated recommendation here is to provide drivers with tips and hints via a mobile app on how to take a picture of a sufficient quality. If the quality of photos is inappropriate, you could deliver notifications to users urging them to take another photo.
- Furthermore, each car part may look different when shot at various angles. This way, you need to encourage users to take as many photos as possible to get the full picture.
- As mentioned earlier, proper infrastructure is key to success.
This way, it is possible to create 3D models capable of generating realistic photos and using them to train classificators to achieve almost 100% precision. After that, such a solution can be integrated into the day-to-day routine of insurance companies, car rental services, and body shops. Through automation of manual processes, these organizations can significantly reduce time and effort spent on human inspection, cutting operational costs on preliminary damage assessment.
To learn more about automating car damage assessment, try it firsthand, check out the videos below, or listen to this podcast.
Want details? Watch the videos!
Further reading
- Analyzing Satellite Imagery with TensorFlow to Automate Insurance Underwriting
- Zurich Insurance Group Incorporates RPA to Achieve $1B of Savings
- What It Takes to Build and Train Neural Networks for Autonomous Vehicles
with assistance from Carlo Gutierrez, Vladimir Starostenkov, and Sergei Sintsov.




