Introduction to Neural Networks and Metaframeworks with TensorFlow

Deep learning gaining its momentum
Google CEO Sundar Pichai has called machine Learning (ML) “a core transformative way by which we are rethinking everything we are doing.” In this spirit, Google open-sourced its TensorFlow “machine intelligence” technology in November 2015.

Dipendra Jha
With the technology gaining its momentum in 2016, Dipendra Jha led a webinar to take almost 300 attendees through a detailed overview of training neural networks. In addition, he introduced the audience to TF-Slim, a metaframework, which uses far less code than similar tools.
Dipendra noted that ML discussions often involve its two siblings, deep learning (DL) and artificial intelligence (AI). He also pointed out that AI-related projects at Google have risen from very few in 2012 to almost 2,700 today.
Learning patterns with neural networks
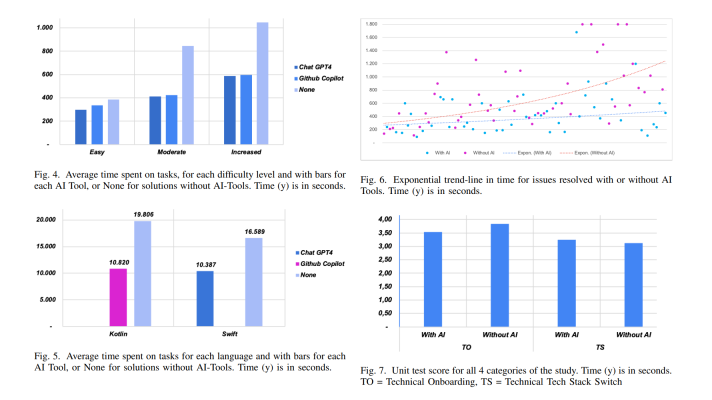
With ML and specifically with TensorFlow, the concept of neural networks also comes into play. According to Dependra, deep neural networks can sometimes recognize images more efficiently than a human. The slide below shows a graphic of a neuron, as well as a very small network. Training neural network of any size means:
- sample a batch of data
- forward the sample through the network to get predictions
- “backprop” any errors (see backpropagation)
- update the weighting of inputs and then repeat
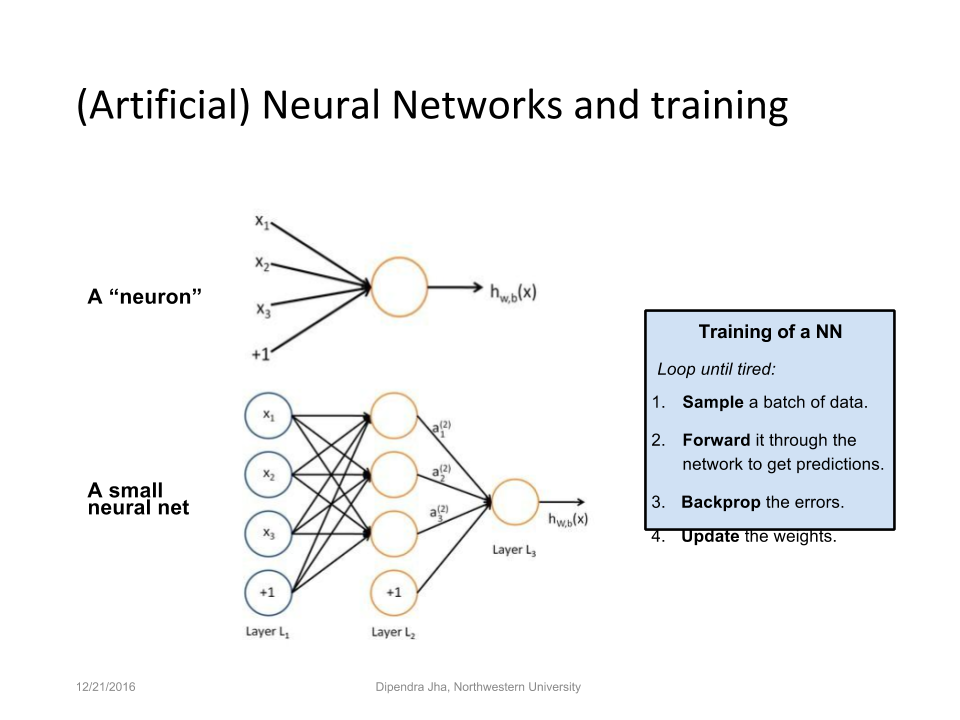
Employing neural networks can create systems that are “exceptionally effective at learning patterns,” according to Dipendra.
“Neural networks utilize learning algorithms that derive meaning out of data by using a hierarchy of multiple layers that mimic the neural networks of our brain.” —Dipendra Jha
“(Thus,) if you provide the system tons of information, it begins to understand it and respond in useful ways,” he added. A deep neural network will have a hierarchy of layers, in which each layer transforms input data into a more abstract concept, such as an “edge,” or “nose,” or “face.” Then an output layer combines those concepts to make predictions.
Dipendra also demonstrated what the system had eventually learnt.

Convolutional neural networks
Extending this thought a bit, he discussed convolutional neural networks (CNNs), in which he said a series of computational layers emulate the visual processing system of visual cortex, with each layer taking in and then outputting a three-dimensional volume (i.e., a series) of numbers:
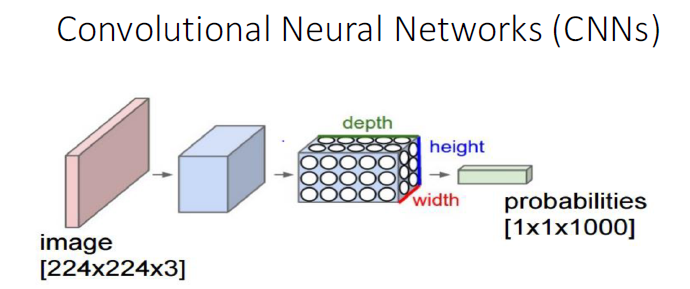
Key aspects of CNNs:
- Input. 4D tensor of shape (mini-batch size, number of input feature maps, image heights, and image width)
- Weights. 4D tensor of shape (number of feature maps at layer
m, number of feature maps at layerm-1, filter height, and filter width) - Max Pooling. Outputs maximum value for each overlapping subregion
- Depth. Number of filters we would like to use
- Padding. Pad the input volume with zeroes around the border
- Stride. Number of pixels with wich we slide the filter
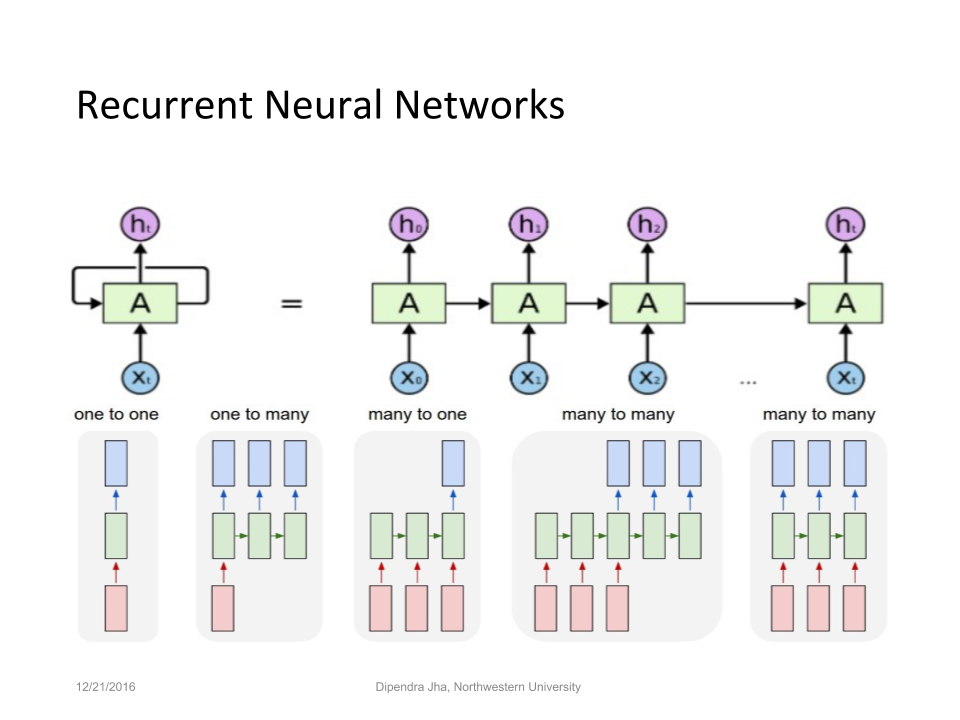
Recurrent neural networks
Add to this the idea of feedback loops and you can create recurrent neural networks (RNNs), which can then be employed using TensorFlow for applications that recognize handwriting, faces, and speech. RNNs can be built to apply to familiar types of interactions.
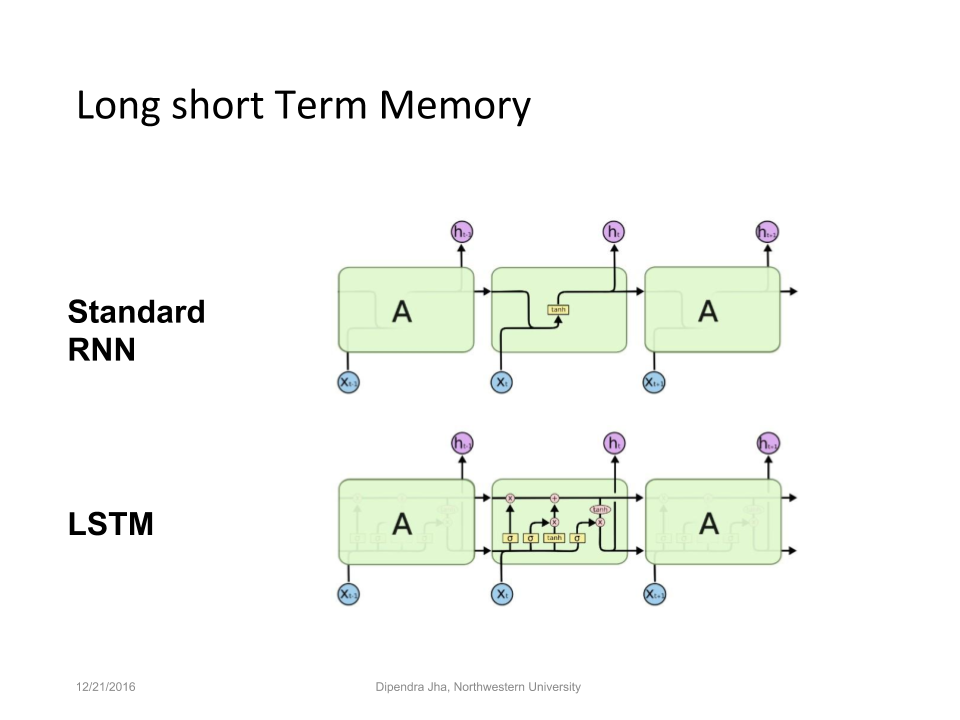
What is more, there are long short-term memory networks, with more cells than that of a standard RNN and capacity to prosess more input.
Four TensorFlow object types
Dipendra then explained how TensorFlow can be used to create four types of objects that differ it from other frameworks:
- Sessions. A session encapsulates the environment in which objects are evaluated.
- Computational graphs. A construction phase in building a TensorFlow app involves assembling graphs, along with a phase to execute ops in the graph.
- Variables. Hold and update parameters are included as TensorFlow variables.
- Placeholders. These are dummy nodes that provide data entry points to the computational graphs.
He also provided sample code for each of the objects created.

Metaframeworks for TensorFlow
In the final part of his webinar, Dipendra enumerated several metaframeworks for TensorFlow:
The latter is described as a “lightweight library for defining, training, and evaluating complex models.” He said it’s easy enough to use, through a simple import command, is supported by Google, and offers a “simple and compact way to define model architectures.” Furthermore, with TF-Slim your code gets significantly shorter.

In the end, Dipendra said that “deep learning is not magic,” but the result of a long-term focused effort at Google that is now being complemented by a vibrant open-source community.
Want details?
Dipendra concluded the webinar by providing copious other code and some demos. Find the Python notebooks for MNIST image classification—using the LeNet architecture with TensorFlow and TF-Slim—at this GitHub repo.
You can check out a video recording of the webinar.
Related slides
Further reading
- Under-the-Hood Mechanisms of Neural Networks with TensorFlow
- Analyzing Text and Generating Content with Neural Networks and TensorFlow
- Using Convolutional Neural Networks and TensorFlow for Image Classification
- Text Prediction with TensorFlow and Long Short-Term Memory—in Six Steps
About the expert

Dipendra Jha is a PhD candidate in Computer Science at Northwestern University. He is exploring the field of deep learning and machine learning using high-performance computing systems in the CUCIS lab. His current research focuses on building deep learning models with dynamic architectures using parallelization on CPU and GPU. In addition, Dipendra is working on creating scalable machine learning models that can be applied to computer vision, natural language processing, social media analytics, and materials science.