
Shell Builds 10,000 AI Models on Kubernetes in Less than a Day
Expanding to green and renewable energy
In 2015 at the United Nations Climate Change Conference, 195 countries signed the Paris Accords, an agreement to reduce greenhouse gas emissions worldwide. The accord’s long-term goal is to limit the rise of global temperature below 2 degrees Celsius above preindustrial levels and eventually reach net-zero global emissions by the second half of the 21st century. With global power consumption expected to double in 2050, many organizations have started the transition to becoming net-zero emission businesses.
Known for being an oil giant, Shell in recent years has expanded its focus from fossil fuel to green and renewable sources of energy, such as wind and solar power. According to Alex Iankoulski, Technical Leader, ML Orchestration at Shell, the company aims to provide a reliable supply of electricity to 100 million people in developing countries by 2030 through its Renewable and Energy Solutions initiative (formerly New Energies).

Alex Iankoulski
“Shell is investing in lower carbon technologies, including renewables such as wind and solar, mobility options, such as electric vehicle charging and hydrogen charging, and an interconnected power grid. Shell is investing up to $2 billion a year in its New Energies business, which focuses on developing cleaner energy solutions.”
—Alex Iankoulski, Shell
To effectively operate its Renewable and Energy Solutions, which includes distributing electrical power to customers, Shell needed a smart, fast, and agile control system. More importantly, the system had to be able to leverage artificial intelligence (AI) in order to efficiently manage computational and storage resources.
Shell relied on Arrikto’s MLOps platform to utilize Kubeflow, an open-source project that aims to make machine learning (ML) workflows on Kubernetes portable and scalable. Additionally, building on top of Kubernetes will enable Shell to quickly spin up and down environments with the help of containers. “The combination of Kubernetes and machine learning is actually a match made in heaven,” explained Jimmy Guerrero, VP Community and Marketing at Arrikto.

Jimmy Guerrero
“First, containers allow us to create tests and experiment with machine learning models on our laptops. We know very well that we can take those same models to production using containers. The idea here isn’t new—we want to write once, reproduce, and run it everywhere. Second, a machine learning workflow on a laptop may be written entirely in one language, let’s say Python, but when we take those models into production, we’re probably going to want to interact with a variety of difference services and applications. These are going to be things like data management, security, front-end visualizations, etc., and here we’re going to probably want to go with a microservices-based architecture. Here again, Kubernetes is going to be a slam dunk for us.”
—Jimmy Guerrero, Arrikto
However, deploying AI at a large scale is not without its problems. According to Alex, there were multiple technical challenges associated with building the foundation for Shell’s Renewable and Energy Solutions.
- Infrastructure needed to be cloud-native and cloud-agnostic. In this manner, code does not have to be rewritten, if the platform has to run on a different cloud or across multiple clouds at the same time.
- Deployments had to be reproducible, auditable, and reversible, enabling developers to check what is running in the company’s systems and how it got there.
- Scaling was to cover the entire spectrum from micro to hyper. Software should run well on a single laptop and in a large cloud.
- Tooling should be web-based and self-servicing, enabling Ops teams to focus on automation rather than repetitive manual tasks.
- Compute resources must be allocated dynamically. Workloads running on compute resources should be resilient and reproducible.
- Storage had to be fast and cost-efficient to enable the decoupling of storage and compute resources.
- Data was to be secured at all times, yet available to authorized users. It should also be versioned, so changes can be tracked and reverted as necessary. Security must be end-to-end enterprise-grade.
- Orchestration must be transparent and not disruptive to users.
Running on Kubernetes
Shell deployed the infrastructure for its Renewable and Energy Solutions on Amazon Elastic Kubernetes Service (EKS). The Kubernetes API was the common language used to orchestrate workloads regardless of the cloud.

Vangelis Koukis
By implementing a GitOps approach, the team can deploy on top of different Kubernetes clusters in a reproducible manner, noted Vangelis Koukis, CTO and cofounder at Arrikto.
“Everything starts from a Git repository. We have opted to stay away from the
kfctltool, so we can deploy in the simplest Kubernetes-native way of applying manifests. Hence, we support seamless upgrades with rollbacks.”
—Vangelis Koukis, Arrikto
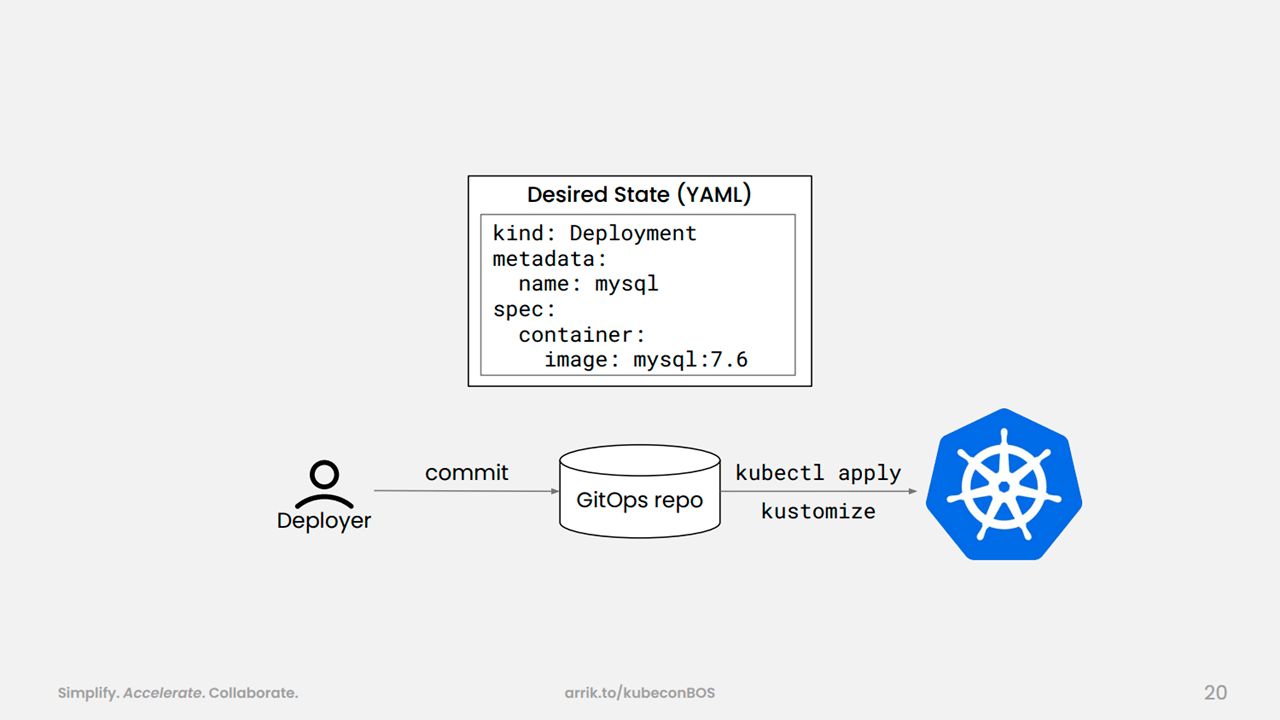 Deploying through GitOps (Image credit)
Deploying through GitOps (Image credit)GitOps treats infrastructure as code, where the state of the infrastructure corresponds to a commit in the repository.
With tools like MicroK8s, light workloads can run on a single laptop. For heavier workloads, Amazon EKS automatically scales seamlessly based on the demand.
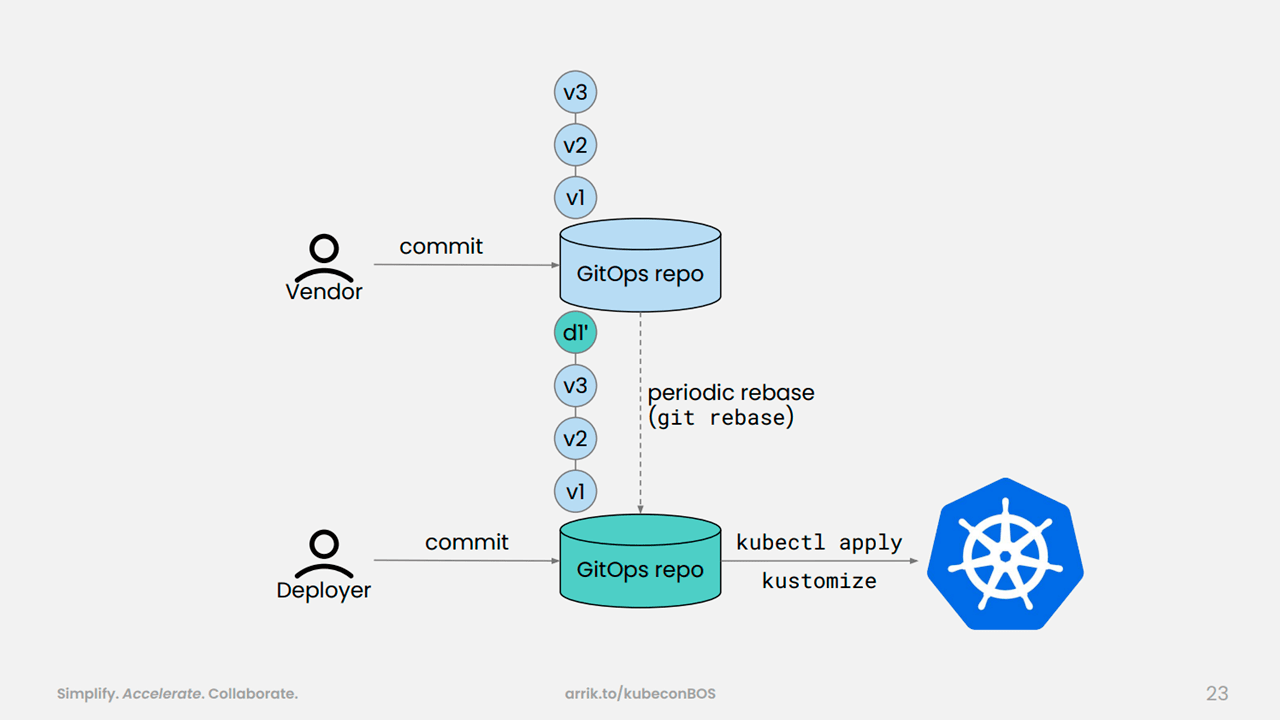 Upgrades using GitOps (Image credit)
Upgrades using GitOps (Image credit)By following a DevOps model, tooling was shifted left, enabling developers to run their own Visual Studio Code Servers, manage code in Git repositories, and eventually run workloads on Kubeflow.
To make compute resources resilient and reproducible, the team utilized containers based on Docker images inside Kubernetes pods.
Data management and security
By moving storage from Amazon Elastic File System (EFS) to local and mounted file systems with Rok, Arrikto’s data management platform, the team can take thousands of point-in-time snapshots, providing end-to-end reproducibility for workloads.
“Think of a time machine. Let’s say we snapshot once every 10 minutes for the notebook servers. You can go back in time and reproduce the data for all the experiments you run. A snapshot could also happen at each step of a pipeline, so you can know exactly what series of events led to the creation of a specific model. You can then investigate any biases.” —Vangelis Koukis, Arrikto
Using Rok, the team can manage storage in multiple clusters in different regions. Each cluster acts as a local independent object store, explained Vangelis. Rok Registry enables the creation of private and public groups with fine-grained access controls.
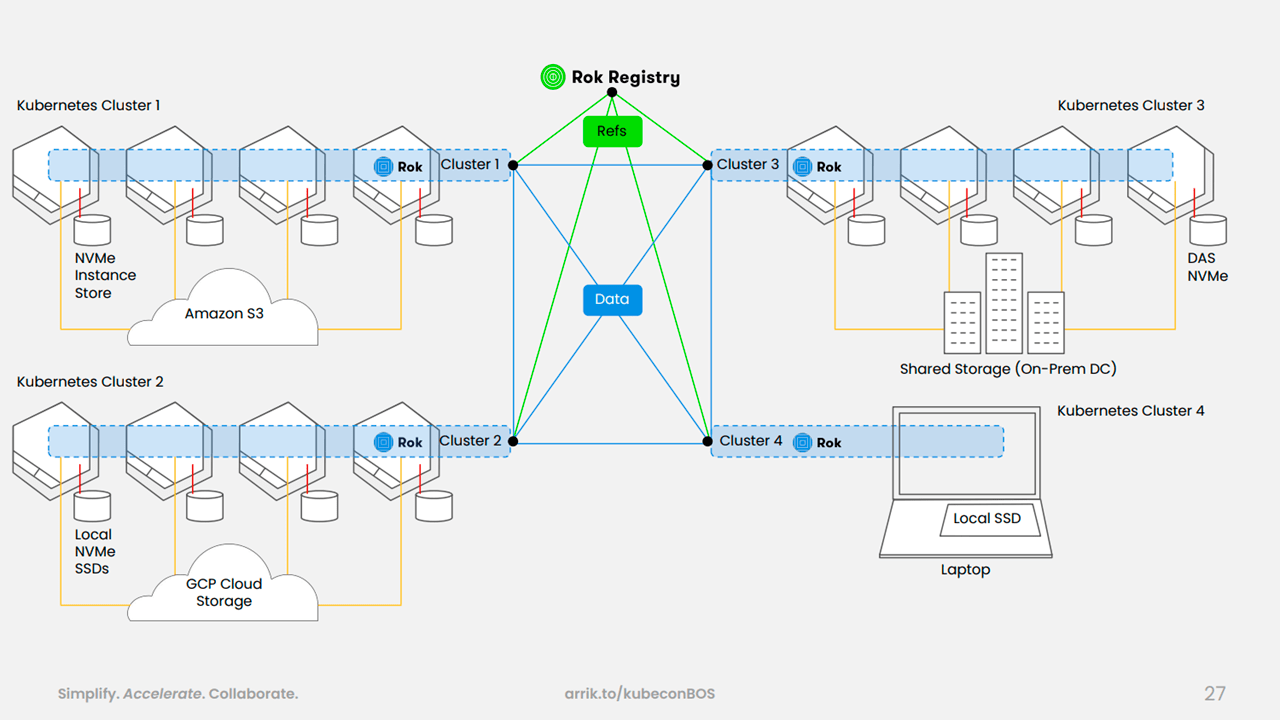 Sharing data sets and environments with Rok (Image credit)
Sharing data sets and environments with Rok (Image credit)In terms of performance, a standard m5d.4xlarge instance using Non-Volatile Memory Express (NVMe) solid-state drives (SSDs) has over 10x read input/output operations per second (IOPS) and 400x write IOPS compared to a 100 GB Amazon EFS instance.
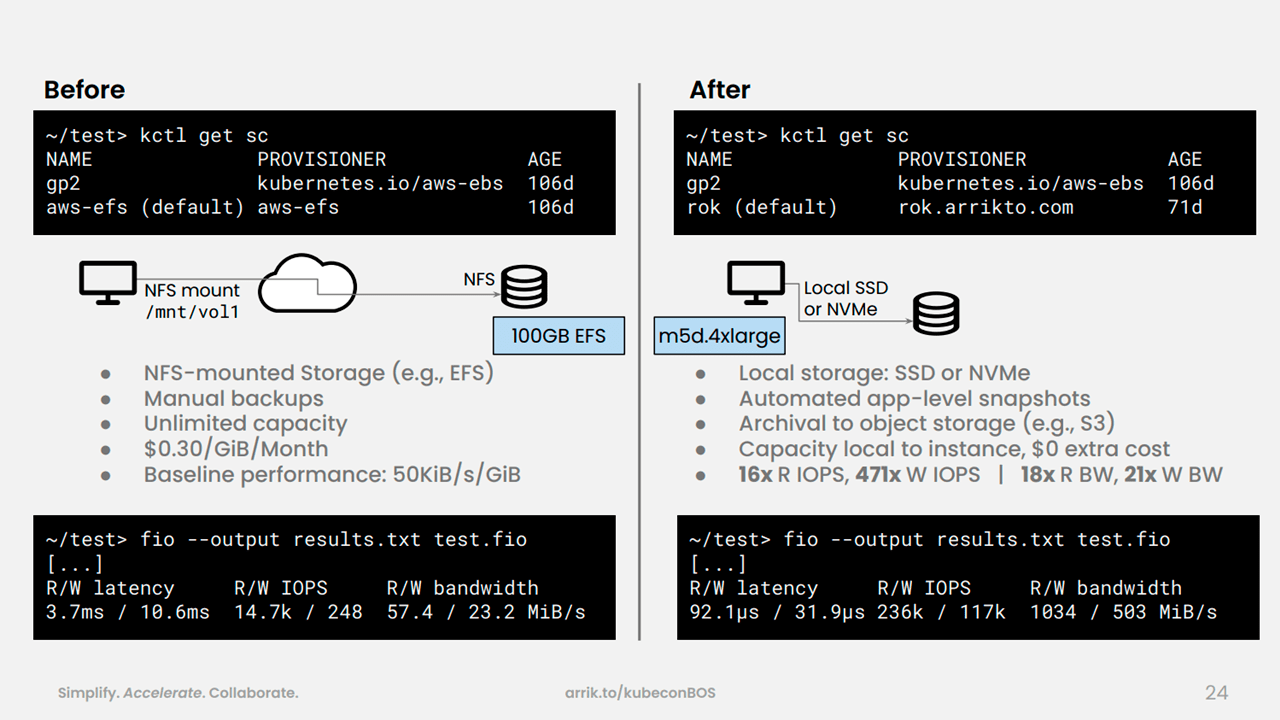 Local storage is faster (Image credit)
Local storage is faster (Image credit)As for security, the team implemented single sign-on (SSO), single logout (SLO), centralized authentication, namespace-based isolation, and shared namespaces.
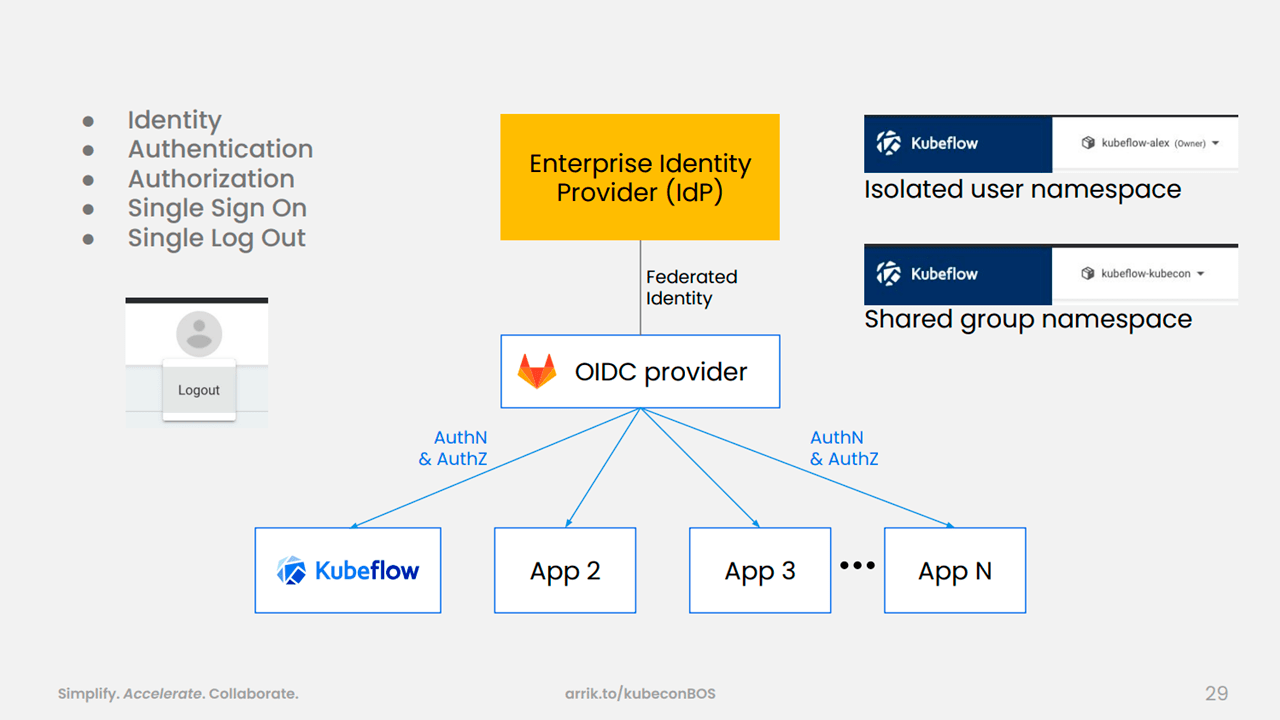 End-to-end security with SSO/SLO (Image credit)
End-to-end security with SSO/SLO (Image credit)Additionally, using the OpenID Connect (OIDC) AuthService, the team extended Kubeflow to become an OIDC client. OIDC AuthService integrates closely with Istio and Envoy proxies.
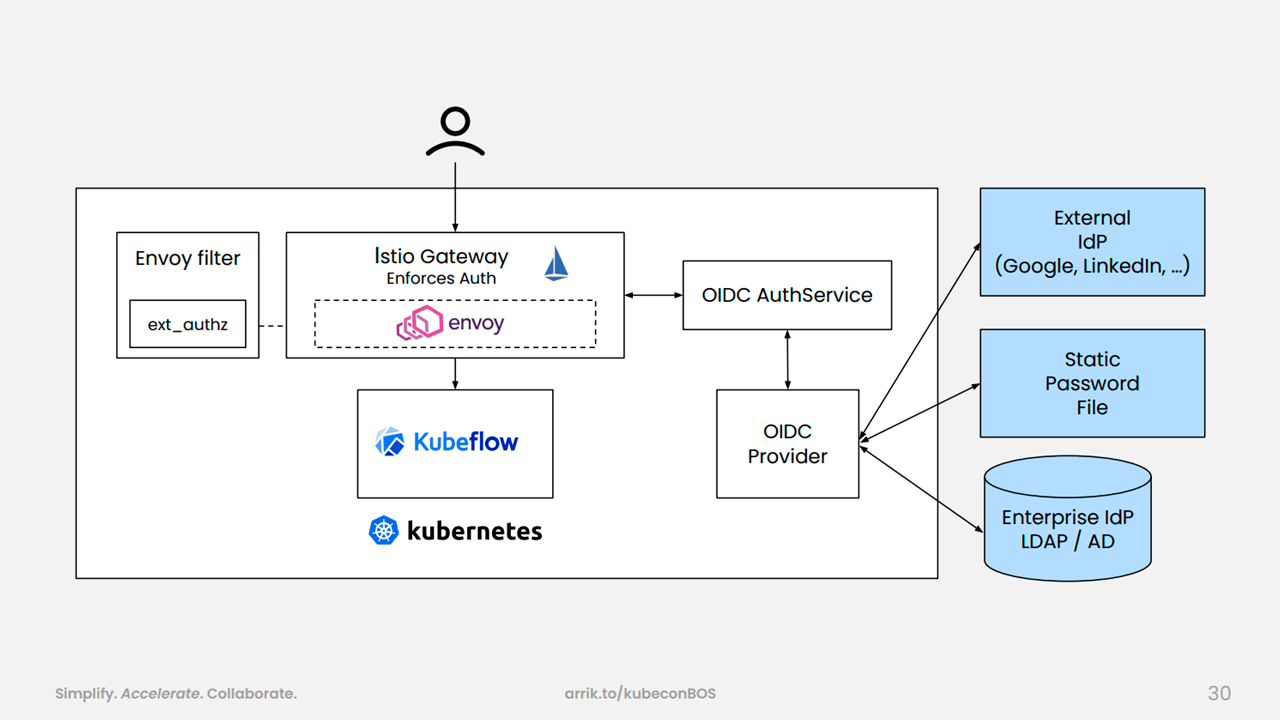 Enforcing Kubeflow security (Image credit)
Enforcing Kubeflow security (Image credit)
Faster modeling with Kubeflow
With Kubeflow, the team can quickly build models and use the data to help optimize operations related to the Shell’s Renewable and Energy Solutions. According to Masoud Mirmomeni, Lead Data Scientist at Shell, Kubeflow gave the company three major advantages.

Masoud Mirmomeni
First, Kubeflow provides a self-service model, enabling data scientists to get computational power and storage, as well as use preconfigured ML toolkits in secured cloud environments.
“Now, we can bring all of those things and do the machine learning projects easily from minute zero. If you wanted to do this in the old-fashioned way, it would take weeks or even months. Now, we can do it in a couple of minutes.”
—Masoud Mirmomeni, Shell
Second, with the help of the Kubeflow Automated pipeLines Engine (KALE), data scientists can simply pass their code to operations teams. This reduces the time it takes to push ML code into production.
Third, since Shell is using Kubernetes, computational and storage resources are easily shared. For instance, computational power used by notebook servers are monitored and when the resources become idle, they are released and become available for other workloads.
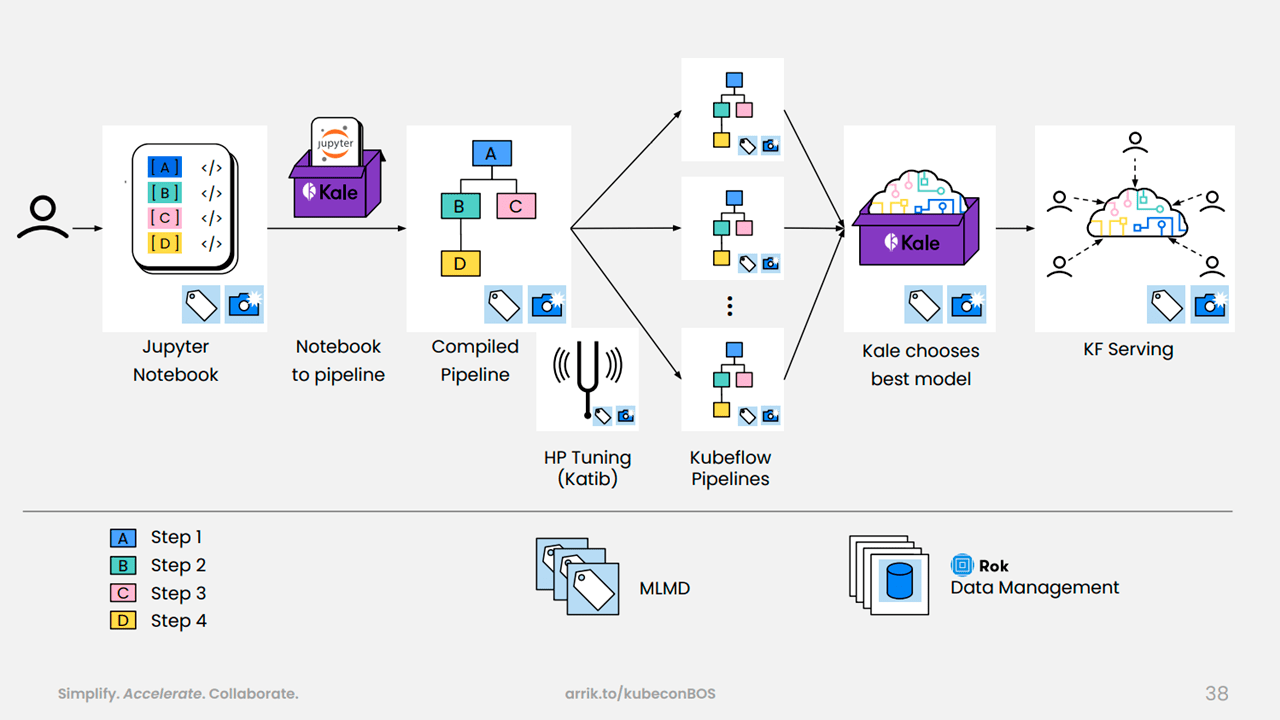 An example of a machine learning workflow at Shell (Image credit)
An example of a machine learning workflow at Shell (Image credit)“Kubeflow is going to create very efficient platforms for data scientists and machine learning engineers to collaborate, share ideas, and learn from their own projects and experiences. It’s also going to reduce the cost of model building by managing the computational and storage resources efficiently.” —Masoud Mirmomeni, Shell
With Kubeflow, Shell has significantly reduced the time it takes for data scientists and ML engineers to build models. Previously, the time required to build 10,000 models would involve two weeks of coding and four weeks of execution. Now, the team can write the code in less than four hours and build all the models within two hours.
Want details? Watch the videos!
Masoud Mirmomeni of Shell and Jimmy Guerrero of Arrikto talk about how Kubeflow helps data scientists at Shell.
Alex Iankoulski of Shell and Vangelis Koukis of Arrikto explain how the foundation for Shell’s Renewable and Energy Solutions was built.
Further reading
- Denso Delivers an IoT Prototype per Week with Kubernetes
- Lyft Runs 300,000+ Containers in a Multicluster Kubernetes Environment
- Kubeflow: Automating Deployment of TensorFlow Models on Kubernetes
About the experts

Alex Iankoulski is Technical Leader, ML Orchestration at Shell, where he works to bridge the gap between prototype and product using Kubernetes and Kubeflow. He is a full-stack software and infrastructure architect who “likes to stay hands-on.” Alex is a Docker Captain who has been helping to accelerate the pace of innovation by applying the container technologies to solve engineering, data science, AI, and ML problems.

Masoud Mirmomeni is Lead Data Scientist at Shell, where he is involved in the company’s initiative to build renewable and green energy solutions. As a data scientist, Masoud uses data exploration, model building, statistical analysis, etc., to help Shell streamline its day-to-day operations. Prior to Shell, he served as a Data Scientist at Change Healthcare, Ancestry, and eBay.

Vangelis Koukis is CTO and cofounder at Arrikto. He holds a PhD in computer science and has a long history of working in storage, data management, and cloud computing. Vangelis leads a team of engineers working hard to bridge the world of low-latency, high-performance local storage with eventually consistent, massively scalable object stores, and decentralized synchronization.





