
Kubeflow: Automating Deployment of TensorFlow Models on Kubernetes

DevOps behind machine learning
Machine learning needs an infrastructure to handle all the operations underlying building a model and pushing it into production. For instance, such operations include infrastructure serving, machine resource management, configuration, monitoring, etc. To ensure composability, portability, and scalability of a machine learning model, a data scientist has to go through extra pain of tweaking this and that. Containerization is the way out when you need to automate all the DevOps things and lay your hands on pure machine learning. So, what are the tools to employ?

Barbara Fusinska
In the domain of machine learning, TensorFlow has gained a reputation of a state-of-the-art framework to experiment with models on anything from desktops to clusters of servers to mobile and edge devices. Meanwhile, Kubernetes is a popular choice of those who seek a usable way to automate deployment, scaling, and management of a containerized application.
Why not using the solutions together? This comes as a reasonable answer to those who are proficient in both machine learning and container orchestration. However, there are data scientists who just want to do their job without a need to think about the infrastructure.
At the recent TensorFlow meetup in London, Barbara Fusinska from Google demoed the Kubeflow project—designed to automate the deployment of TensorFlow-based models on Kubernetes.
How it works
Open-sourced on December 21, 2017, Kubeflow aims at relieving constraints of infusing machine learning into production-grade solutions with multiple modules and components. These components may be both vendor and hand-rolled, and Kubeflow is to ensure they faultlessly interact. To enable sufficient connectivity and convenient management across a fleet of components is not a trivial task even across moderate setups. As Barbara noted, being a data scientist, she would rather not wasting time on tweaking infrastructure when it could be automated.
“All the components that data scientists have to think about and hate to think about. We would love to have a tool to say I want to play with this model, I want to create this model, I want to publish it, and I want something to pipe it.” —Barbara Fusinska, Google
Kubeflow is designed to address the challenges of deploying TensorFlow on Kubernetes. At the moment, the tool allows for:
- Using JupyterHub to build and manage interactive Jupyter notebooks
- Enabling TensorFlow Training Controller that can be configured to use either CPUs or GPUs, as well as can be dynamically customized to the size of a cluster with a single setting
- Using the TensorFlow Serving container to export trained TensorFlow models to Kubernetes
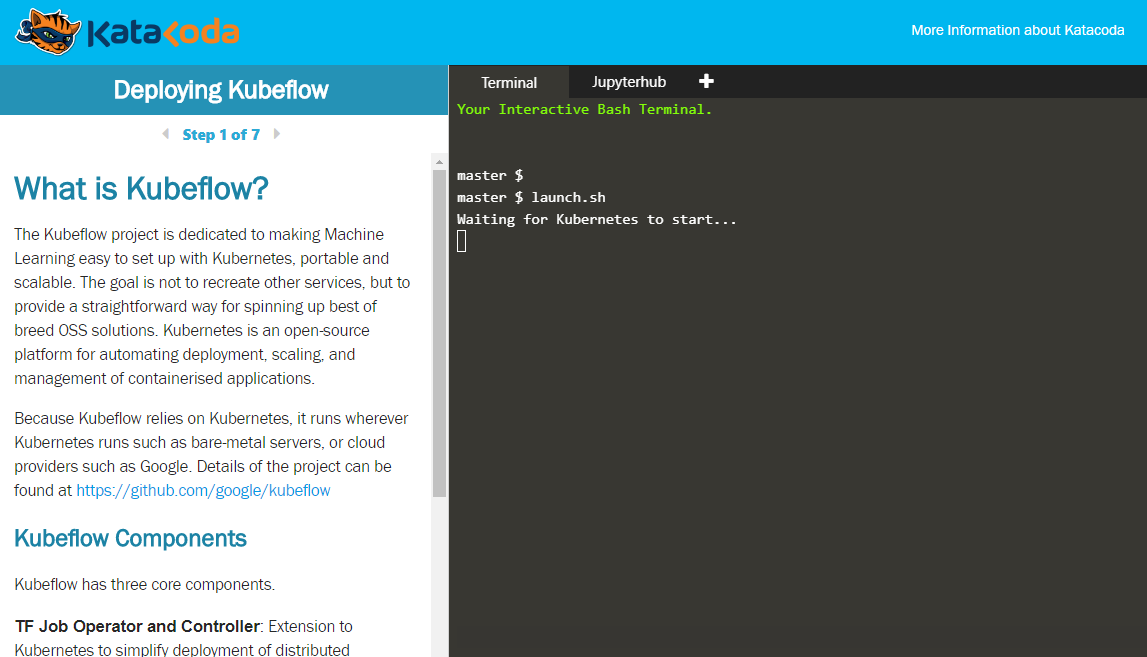 Deploying Kubeflow to a Kubernetes cluster in Katacoda’s interactive environment (Image credit)
Deploying Kubeflow to a Kubernetes cluster in Katacoda’s interactive environment (Image credit)Kubeflow uses ksonnet—a command line tool that eases management of complex deployments consisting of multiple components. With ksonnet, it is possible to generate Kubernetes manifests from parameterized templates. This way, Kubernetes manifests can be customized up to your needs. For instance, one may generate manifests for TensorFlow Serving with a user supplied URI for the model.
Kubeflow also employs Argo—an open-source container-native workflow engine for Kubernetes. Argo allows for checking out workflow information about Kubeflow’s end-to-end examples.
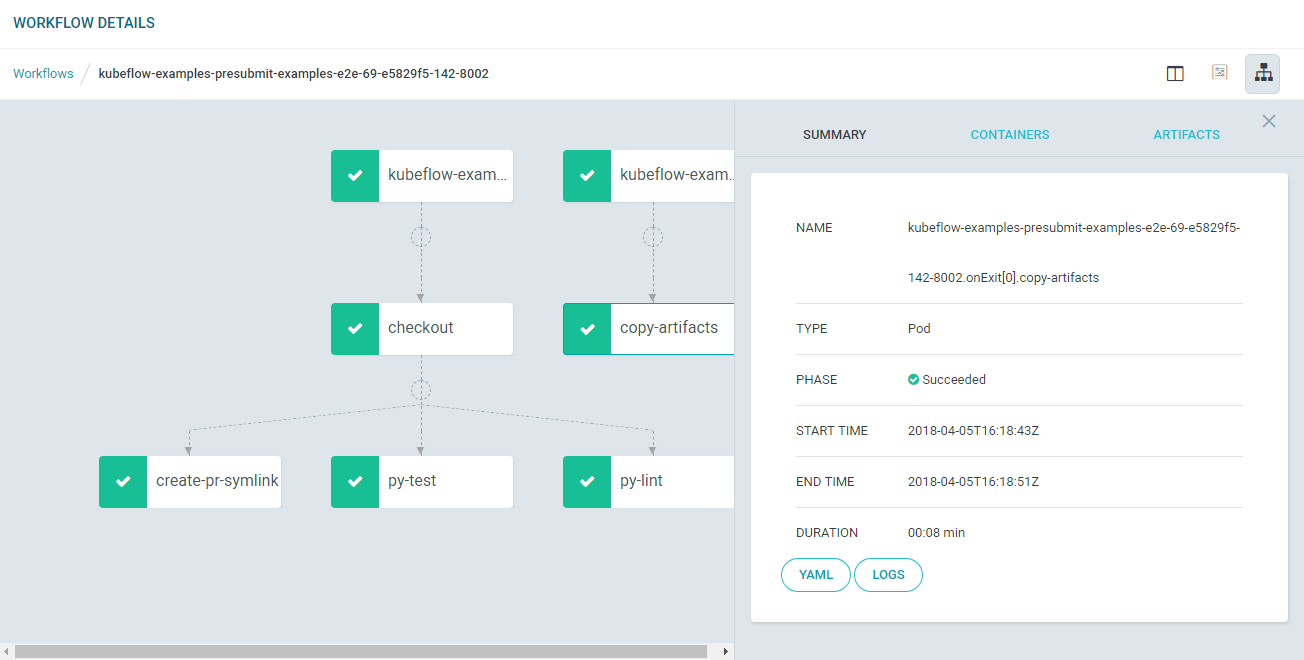 Details of Kubeflow’s end-to-end examples workflows using Argo (Image credit)
Details of Kubeflow’s end-to-end examples workflows using Argo (Image credit)With Kubeflow, you are able to train and serve TensorFlow models in the environment of choice, be it a local, on-premises, or a cloud one. There is also a possibility to combine TensorFlow with other processes. For instance, using TensorFlow agents that will run simulations to generate data for training reinforcement learning models.
Currently, Kubeflow makes use of tf-operator (v1alpha1) for running TensorFlow jobs on Kubernetes. After the community suggested a number of improvements to this API, it was decided to upgrade to the v1alpha2 version, and the work is in progress now.
What it means for a data scientist?
Barbara shared an example of a machine learning workflow from a data scientist perspective. Her very example can be broadly divided into three stages. Within the first stage, you choose an algorithm, tune hyperparameters, and adjust the architecture. At the second stage, you build a model, run production code, and exploit hardware. The third stage comes with model serving and consumption.
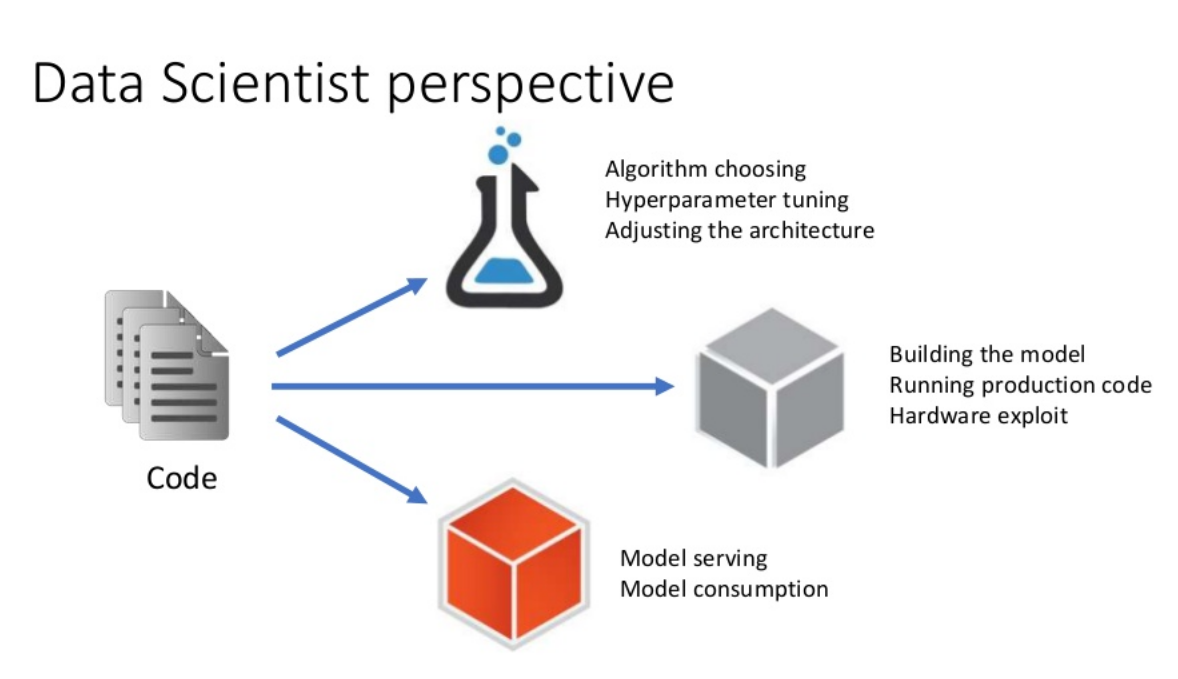 An example of a machine learning workflow from a data scientist perspective (Image credit)
An example of a machine learning workflow from a data scientist perspective (Image credit)Kubeflow can be used at all the three stages, automating operations a data scientist would rather not deal with.
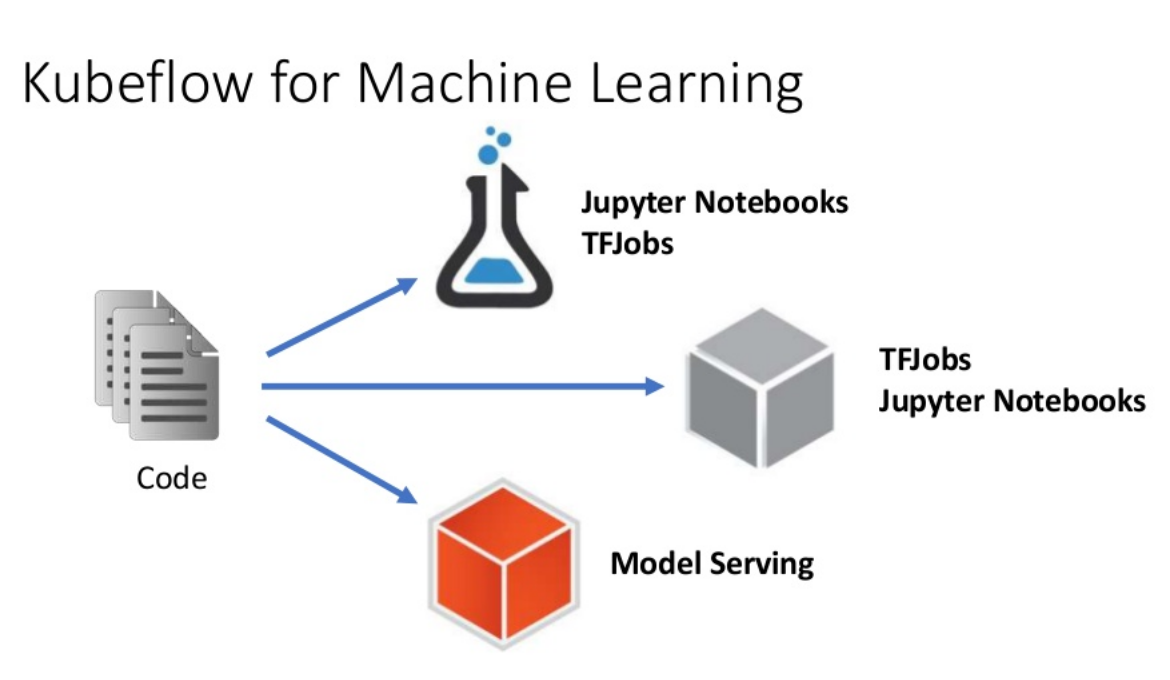 A machine learning workflow with Kubeflow (Image credit)
A machine learning workflow with Kubeflow (Image credit)With Kubeflow, one uses Jupyter notebooks and TensorFlow jobs for experimentation at the first stage and further on for building models, while using TensorFlow Serving for model serving. To show how it works in real life, Barbara provided a demo of Kubeflow in action.
If you want to try out Kubeflow, use this interactive environment, which simulates a two-node Kubernetes cluster. In addition, you may examine this tutorial that provides an end-to-end Kubeflow example using a sequence-to-sequence model. You may also check out Kubeflow’s GitHub repo and the tool’s user guide.
The Kubeflow’s team will deliver a talk on the project’s evolution at the upcoming KubeCon + CloudNativeCon Europe 2018.
Anyone interested in Kubeflow is encouraged to subscribe to the project’s mailing list or join Kubeflow’s Slack channel.
Want details? Watch the video!
In this video, Ben Hall of Katacoda demonstrates how to deploy the GitHub issue summarization with Kubeflow.
Related slides
These slides by Ben Hall highlight the approach to deploying the GitHub issue summarization with Kubeflow.
Further reading
- Ins and Outs of Integrating TensorFlow with Existing Infrastructure
- TensorFlow in the Cloud: Accelerating Resources with Elastic GPUs
- TensorFlow Cheat Sheet
About the expert
Barbara Fusinska is a Machine Learning Strategic Cloud Engineer at Google with strong software development background. While working with a variety of different companies, she gained experience in building diverse software systems. This experience brought Barbara’s focus to the field of data science and big data. She believes in the importance of data and metrics when growing a successful business. Alongside collaborating around data architectures, Barbara still enjoys programming activities. She is also a frequent speaker at conferences of different scale.





