Multi-Cluster Deployment Options for Apache Kafka: Pros and Cons

Enabling multi-cluster deployments in Apache Kafka
Comprehensive enterprise-grade software systems should meet a number of requirements, such as linear scalability, efficiency, integrity, low time to consistency, high level of security, high availability, fault tolerance, etc.
![]()
Apache Kafka is a distributed messaging system, which allows for achieving almost all the above-listed requirements out of the box. However, this proves true only for a single cluster. By default, Apache Kafka doesn’t have data center awareness, so it’s rather challenging to deploy it in multiple data centers. Meanwhile, such a type of deployment is crucial as it significantly improves fault tolerance and availability.
Below, we explore three potential multi-cluster deployment models—a stretched cluster, an active-active cluster, and an active-passive cluster—in Apache Kafka, as well as detail and reason the option our team sees as an optimal one.
A stretched cluster
A stretched cluster is a single logical cluster comprising several physical ones. Replicas are evenly distributed between physical clusters using the rack awareness feature of Apache Kafka, while client applications are unaware of multiple clusters. The perks of such a model are as follows:
- Strong consistency due to the synchronous data replication between clusters.
- Cluster resources are utilized to the full extent.
- In case of a single cluster failure, other ones continue to operate with no downtime.
- Unawareness of multiple clusters for client applications.
Still, there are some cons to bear in mind:
- This model features high latency due to synchronous replication between clusters. So, it’s recommended to use such deployment only for clusters with high network bandwidth. For cloud deployments, it’s recommended to use the model for availability zones, not regions.
- Within the stretched cluster model, minimum three clusters are required. Apache Kafka uses Zookeeper for storing cluster metadata, such as Access Control Lists and topics configuration. Zookeeper uses majority voting to modify its state. To achieve majority, minimum N/2+1 nodes are required. So, it’s not possible to deploy Zookeeper in two clusters, because the majority can’t be achieved in case of the entire cluster failure.
An active-active cluster
The active-active model implies there are two clusters with bidirectional mirroring between them. Data is asynchronously mirrored in both directions between the clusters. Client applications are aware of several clusters and can be ready to switch to other cluster in case of a single cluster failure. Client requests are processed by both clusters. The advantages of this model are:
- Resources are fully utilized in both clusters.
- Zero downtime in case of a single cluster failure.
- Network bandwidth between clusters doesn’t affect performance.
The drawbacks of using such a model:
- Eventual consistency due to asynchronous mirroring between clusters
- Complexity of bidirectional mirroring between clusters
- Possible data loss in case of a cluster failure due to asynchronous mirroring
- Awareness of multiple clusters for client applications
An active-passive cluster
The active-passive model suggests there are two clusters with unidirectional mirroring between them. Data is asynchronously mirrored from an active to a passive cluster. Client applications are aware of several clusters and must be ready to switch to a passive cluster once an active one fails. Client requests are processed only by an active cluster. This approach is worth trying out for the following reasons:
- Simplicity of unidirectional mirroring between clusters.
- Network bandwidth between clusters doesn’t affect performance of an active cluster.
Though, there is a number of issues brought along:
- Eventual consistency due to asynchronous mirroring between clusters.
- Downtime in case of an active cluster failure.
- The resources of a passive cluster aren’t utilized to the full.
- Possible data loss in case of an active cluster failure due to asynchronous mirroring.
- Awareness of multiple clusters for client applications.
The stretch cluster seems an optimal solution if strong consistency, zero downtime, and the simplicity of client applications are preferred over performance. However, this model is not suitable for multiple distant data centers. Furthermore, not all the on-premises environments have three data centers and availability zones. The active-active model outplays the active-passive one due to zero downtime in case a single data center fails. Therefore, we would like to have a closer look at the active-active option.
Why considering an active-active cluster model?
This type of a deployment should comprise two homogenous Kafka clusters in different data centers/availability zones. The connectivity between Kafka brokers is not carried out directly across multiple clusters. They are connected through an asynchronous replication (mirroring). The bidirectional mirroring between brokers will be established using MirrorMaker, which uses a Kafka consumer to read messages from the source cluster and republishes them to the target cluster via an embedded Kafka producer. Client applications receive persistence acknowledgment after data is replicated to local brokers only.
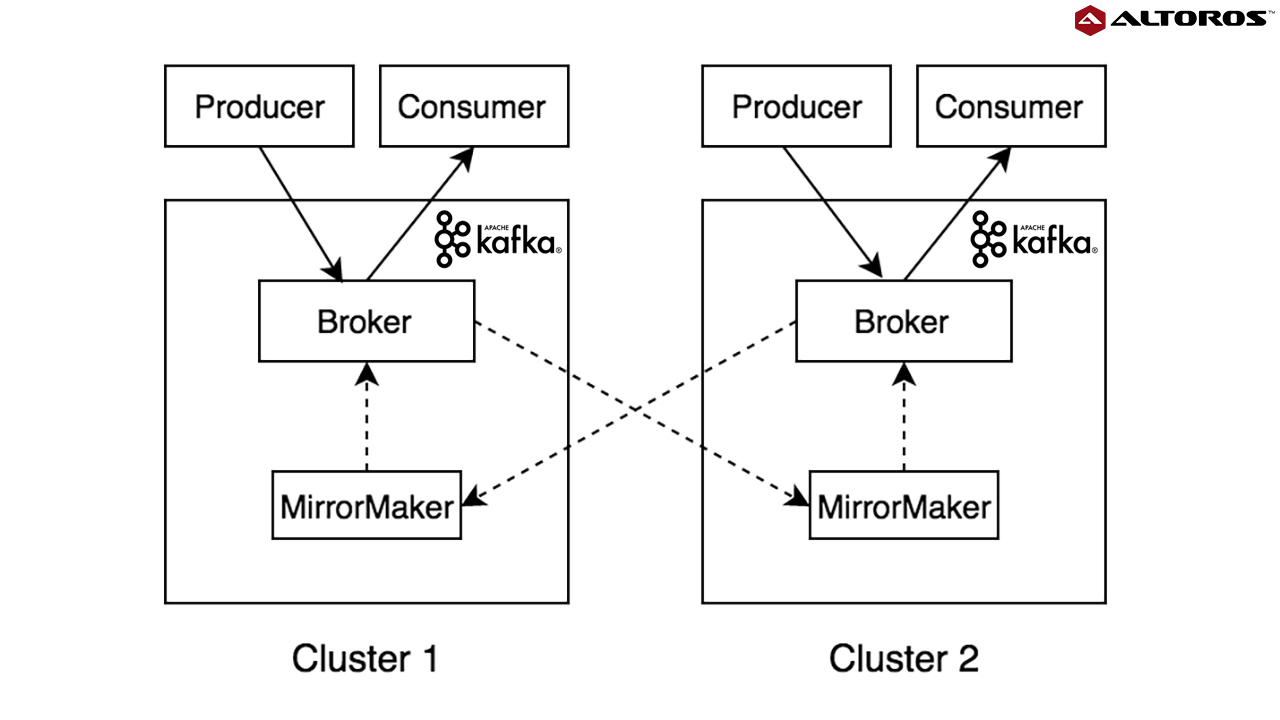 Bidirectional mirroring of the Kafka topic between two clusters
Bidirectional mirroring of the Kafka topic between two clustersUnder this model, client applications don’t have to wait until the mirroring completes between multiple clusters. Distinct Kafka producers and consumers operate with a single cluster only. However, data from both clusters will be available for further consumption in each cluster due to the mirroring process.
In order to prevent cyclic repetition of data during bidirectional mirroring, the same logical topic should be named in a different way for each cluster. The best option is using the cluster name as a prefix for the topic name. In case we have a logical topic called topic, then it should be named C1.topic in one cluster, and C2.topiс in the other. Producers will write their messages to the corresponding topics according to their cluster location. MirrorMakers will replicate the corresponding topics to the other cluster. Consumers will be able to read data either from the corresponding topic or from both topics that contain data from clusters.
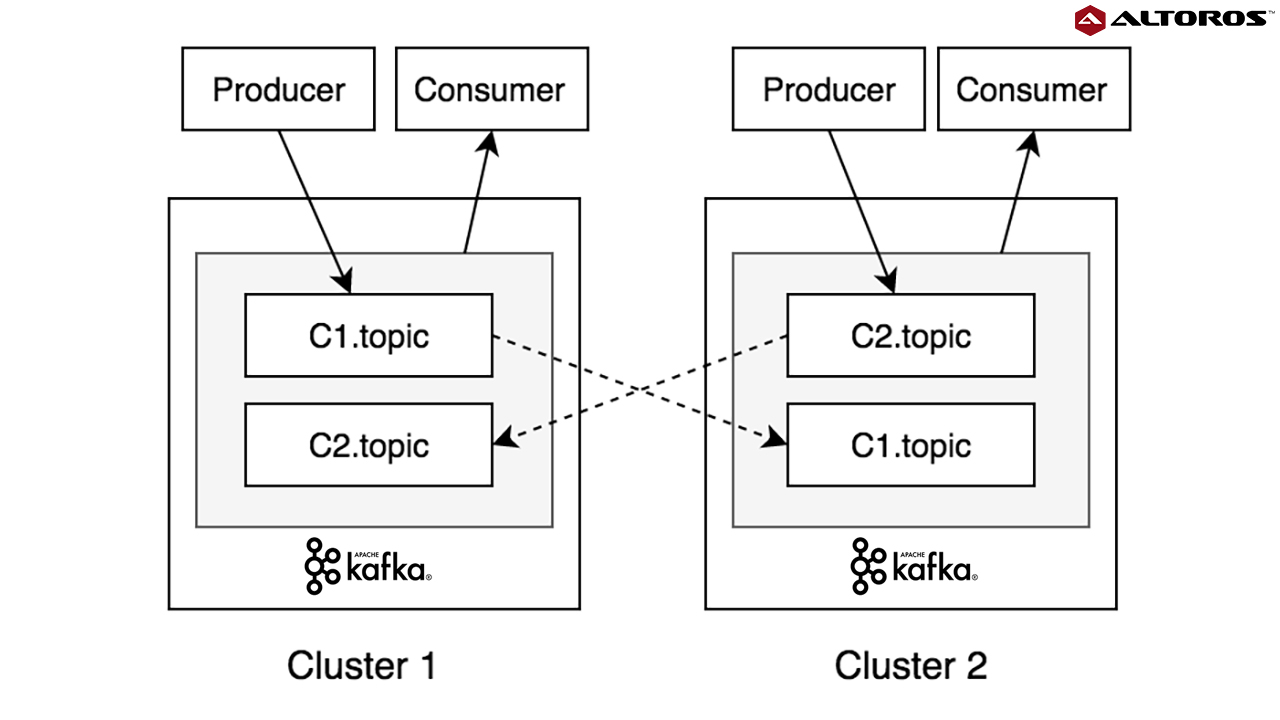 An eventual consistent active-active multi-cluster Kafka deployment
An eventual consistent active-active multi-cluster Kafka deploymentIn case of a disaster event in a single cluster, the other one continues to operate properly with no downtime, providing high availability. Data between clusters is eventually consistent, which means that the data written to a cluster won’t be immediately available for reading in the other one. In case of a single cluster failure, some acknowledged ‘write messages’ in it may not be accessible in the other cluster due to the asynchronous nature of mirroring.
Summing it up
Out of the three examined options, we tend to choose the active-active deployment based on real-life experience with several customers. However, the final choice type of strongly depends on business requirements of a particular company, so all the three deployment options may be considered regarding the priorities set for the project.
Further reading
- Using Spark Streaming, Apache Kafka, and Object Storage for Stream Processing on Bluemix
- Processing Data on IBM Bluemix: Streaming Analytics, Apache Spark, and BigInsights
About the author