TensorFlow in the Cloud: Accelerating Resources with Elastic GPUs

Issues across training scenarios
Combined with GPUs, TensorFlow poses a powerful instrument for deep learning. However, it may still be difficult to switch between CPUs and GPUs—both in a local environment and in the cloud. One of the sessions at TensorBeat 2017 explored the ways to address the associated challenges and to maximize the usage of computational powers with Elastic GPUs.
Why would one even need to switch between CPU and GPU? The obvious reason to employ GPUs for machine learning is to accelerate the process of model training. Still, everything comes at a price, according to Subbu Rama of Bitfusion.

Subbu outlined the pitfalls that occur when initiating different scenarios of training a TensorFlow-based model on a GPU.
For instance, managing dependencies can be quite laboursome even with a single GPU implementation. When moving from CPU to GPU, “it can be hugely beneficial to explicitly put data tasks on CPU and number crunching (gradient calculations) on GPUs with tf.device(),” as Subbu noted.
In case of multiple GPUs, one also has to write additional code to define device placement with tf.device(). And more code-writing is needed to calculate gradients on each GPU and an average gradient for the update.
What about distributed TensorFlow? Assume you utilize one parameter server, a number of worker servers, and a shared file system. The code changes to introduce are as follows:
- Define a parameter server and worker ones
- Implement
tf.MonitoredSession() - Either set up a cluster manager or individually kick off each job on each worker and parameter server
The TensorFlow on Spark scenario with one parameter server and a number of worker servers requires data to be placed in HDFS. In this case, one needs to rename a few variables of a distributed implementation. For example, (tf.train.Server() becomes TFNode.start_cluster_server(). In addition, one has to clearly understand multiple utils for reading/writing to HDFS.
How to accelerate?
A typical life cycle of a deep learning-based app involves development in a local environment, training a model on servers, and deployment in the cloud. In the context of a growing team and expanding resources, Subbu highlights “the huge untapped opportunity,” which resides in “the acceleration of the existing CPU resources and broader enterprise teams and initiatives.”
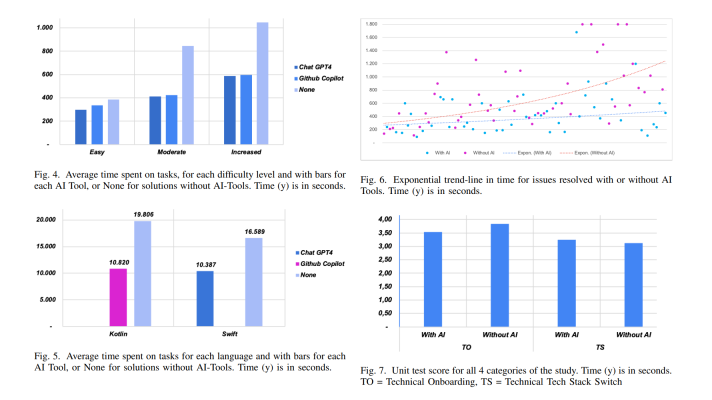
Cost-efficient on-demand GPU acceleration of the existing CPU resources may happen through adding Elastic GPUs to a data center or a cloud.
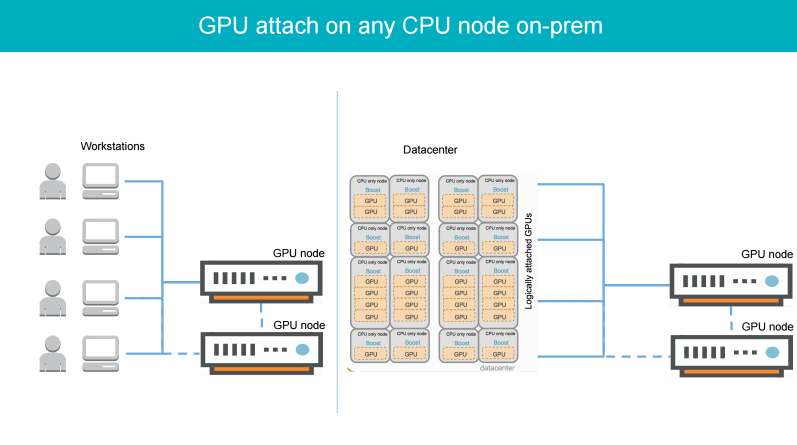
This way, development may start on CPU machines with notebooks, code editors, or any other tools of choice. Then, one can attach an Elastic GPU from within a data center, later on scale out to multiple ones with no code changes needed, or utilize a local GPU with attached Elastic GPUs from the data centers.
The approach offers accelerated computations with smart scheduling and auto-allocation across multiple concurrent workloads and users. As a bonus, Subbu noted, the underlying infrastructure “doesn’t have to be a money pit” through smart scaling.
Subbu then outlined how to simplify adding Elastic GPUs in the cloud or on-premises with Flex—Bitfusion’s AI platform.
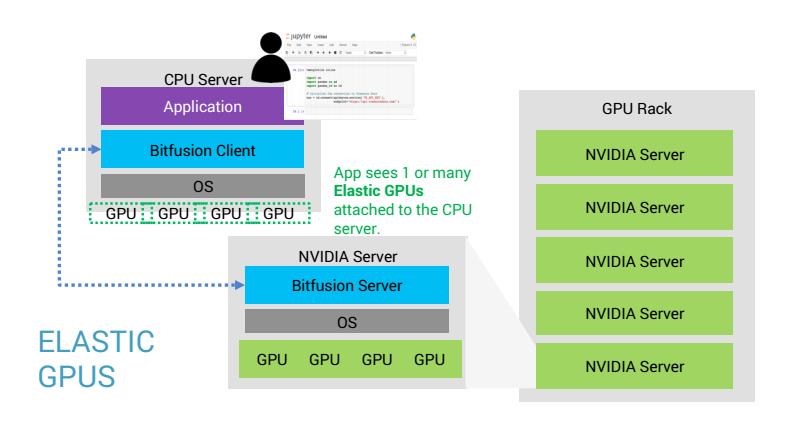
The whole AI infrastructure can be operated in 5 steps:
- Get started with pre-built deep learning containers or create your own. Start initial development locally or on shared CPUs with interactive workspaces.
- Attach one or more GPUs on-demand for accelerated training of a model.
- Perform batch scheduling for maximum resource efficiency and parallel training of a model for enhanced speed.
- Expose finalized models for production inference.
- Manage cluster resources, containers, and users.

According to Bitfusion, this combined solution may enable up to “10x faster development, greater efficiency, and unlimited scalability.”
To demonstrate how this happens in practice, Tim Gasper, a Bitfusion’s fellow, provided a brief demo during the session.
Want details? Watch the video!
Related slides
Further reading
- Mastering Game Development with Deep Reinforcement Learning and GPUs
- The Diversity of TensorFlow: Wrappers, GPUs, Generative Adversarial Networks, etc.
- Performance of Distributed TensorFlow: A Multi-Node and Multi-GPU Configuration
About the experts
Subbu Rama is a co-founder and CEO at Bitfusion, a company providing tools to make AI app development and infrastructure management faster and easier. Previously, he worked in various roles at Intel, leading engineering efforts spanning across design, automation, validation, and post-silicon. Subbu worked on Intel’s first Integrated Graphics CPU, as well as on first low-power CPU Atom and its SOC, high-performance micro-servers using low-power mobile phone processors, and Xeon servers.
Tim Gasper is a product manager at Bitfusion. With 9+ years in product management and marketing, he is experienced in building SaaS and enterprise software platforms utilizing big data, IoT, analytics, and cloud orchestration. Tim held key positions at Rackspace, CSC, and Infochimps (acquired by CSC in 2013). He also co-founded Keepstream, which was later acquired by Infochimps in 2011.