
Lyft Runs 300,000+ Containers in a Multicluster Kubernetes Environment
Scaling too fast
Lyft is one of the largest ridesharing companies in the US, operating in all 50 states, as well as in Toronto, Ottawa, and Vancouver. Headquartered in San Francisco, the company reported a total revenue of $2.3 billion in 2020.
A few years after its founding in 2012, Lyft had already outgrown most of its infrastructure. “The company grew very quickly,” explained Vicki Cheung, Engineering Manager at Lyft, during an interview with Software Engineering Daily. “They were outgrowing both in scale and in the number of engineers that were using the system.”
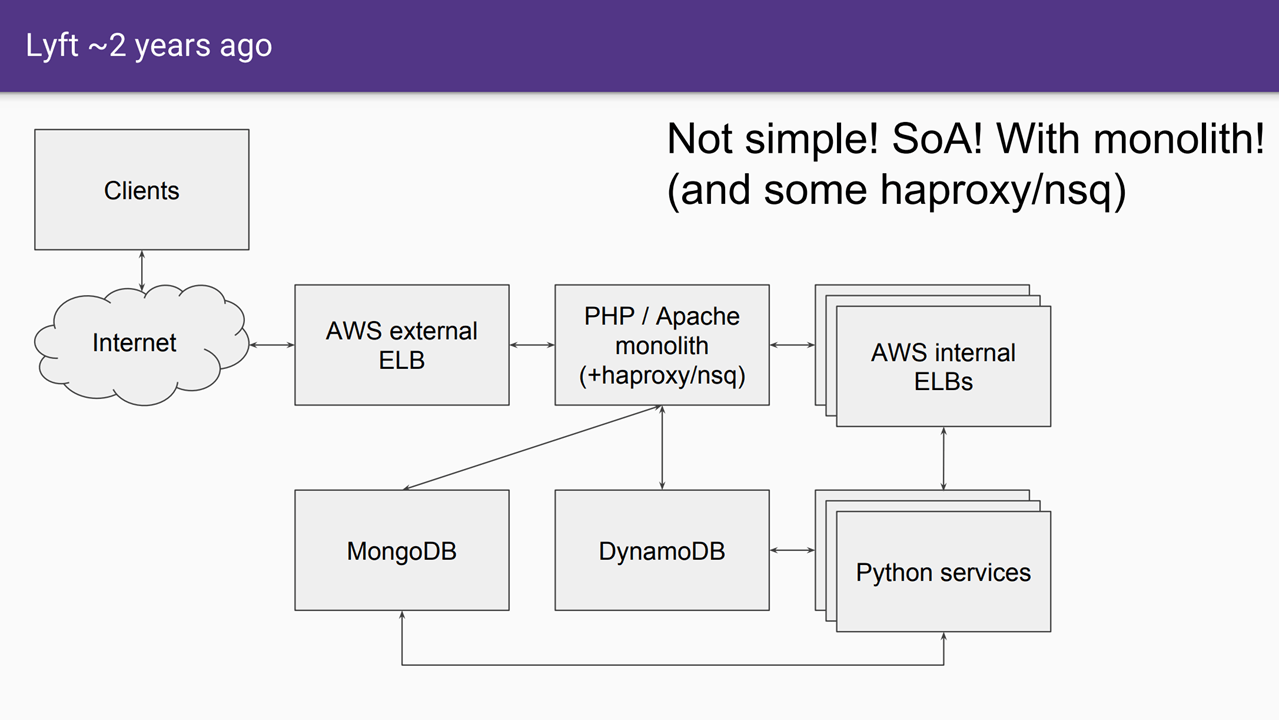 Lyft’s monolithic architecture back in 2015 (Image credit)
Lyft’s monolithic architecture back in 2015 (Image credit)
Vicki Cheung
“Like a typical startup story, Lyft was scrappy in the beginning and just built whatever was needed to ship the product. It just organically grew from there. There was never a time to overhaul the systems.”
—Vicki Cheung, Lyft
Another issue that became prominent as the startup expanded was the need to separate the infrastructure and application layers. Product engineers still need to think about infrastructure code when they should be focused on their apps as explained by Lita Cho and Jose Nino, Senior Software Engineers at Lyft, during KubeCon North America 2018.

Lita Cho
“We want product engineers to think just about their apps and minimize the infrastructure work they need to do, reducing the cognitive load.”
—Lita Cho, Lyft
To address both concerns, the company began migrating to Kubernetes in 2018.
Creating a hybrid environment
Initially, Lyft was using virtual machines on Amazon Web Services (AWS). To manage its network, the company created Envoy, a distributed proxy for services and applications.
In order to migrate to Kubernetes without any downtime, the company set two goals:
- The new infrastructure had to be transparent for product engineers.
- The new infrastructure had to be reliable, allowing incremental rollouts and rollbacks in case of errors.
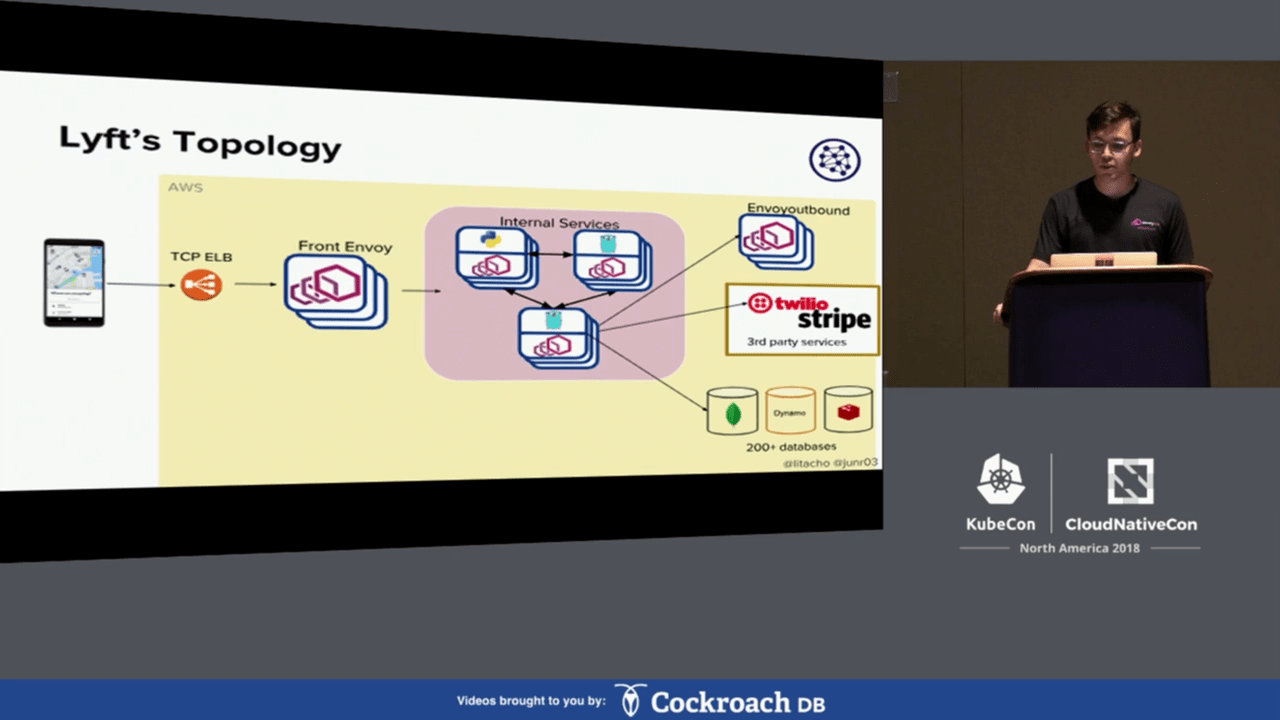 Architecture at Lyft prior to migration (Image credit)
Architecture at Lyft prior to migration (Image credit)
Jose Nino
“We want to build a system that makes it easy for product engineers to operate the network regardless of what may be behind the scenes. We want to make this new infrastructure accessible to use, while at the same time maintaining Lyft’s real-time system reliable.”
—Jose Nino, Lyft
During the migration, Envoy played a crucial role, serving as a sidecar to every service. This abstracted the network and enabled resources, wherever they may be located, to be routed to the service making the request. Specifically, Envoy xDS, which consist of discovery services and APIs, can dynamically configure the data plane from a centralized server.
“The xDS APIs can configure the data plane from a central xDS control plane, separating the concerns between configuration and the processing requests.” —Jose Nino, Lyft
To better understand this abstraction, Envoy xDS control plane pulls data from Lyft’s legacy discovery service and uses Kubernetes watch APIs to retrieve IP addresses of pods. All this data is then converted and configured into the Envoy sidecars. This creates a hybrid environment, where Kubernetes services can interact with legacy services.
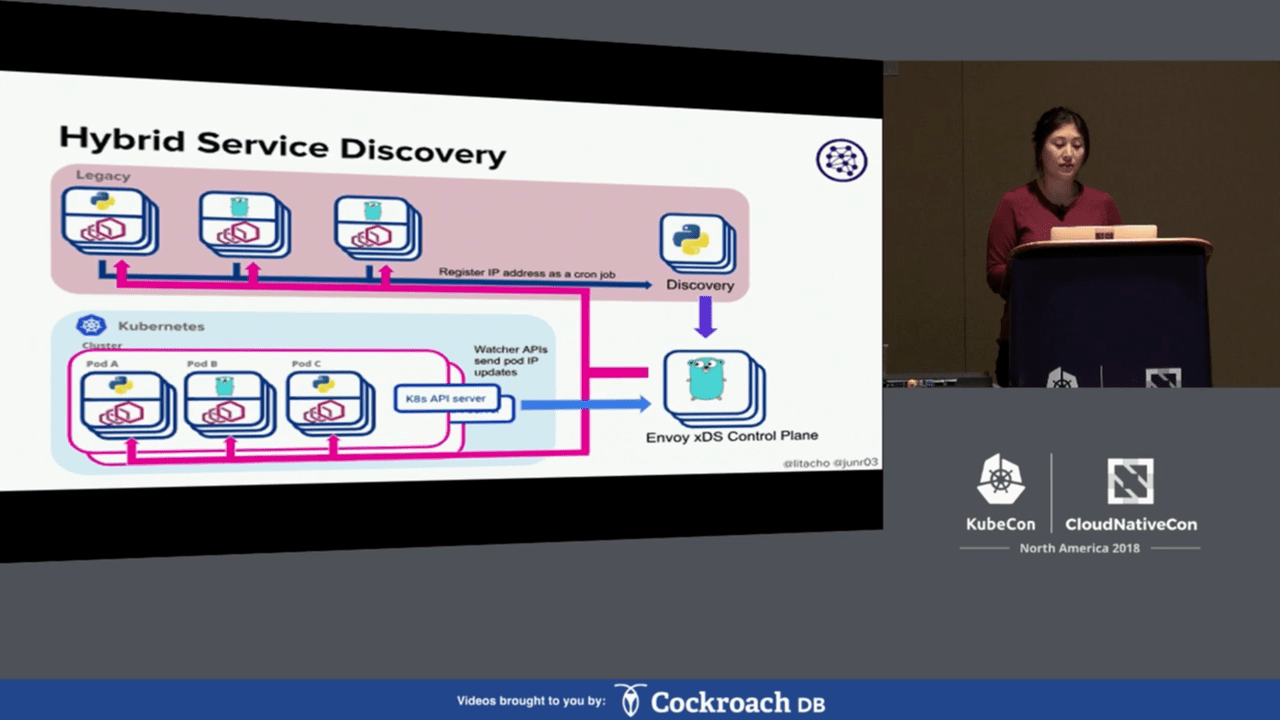 Envoy routes traffic for Kubernetes and the legacy stack (Image credit)
Envoy routes traffic for Kubernetes and the legacy stack (Image credit)“Because we are able to send out all those IP addresses with the Envoy sidecars, they now form a mesh. There’s now no difference between legacy and Kubernetes. Services can be split between the two, and we can still serve traffic to each other.” —Lita Cho, Lyft
Migration roadmap and results

Paul Fischer
While Lyft began migrating its workloads to Kubernetes in 2018, the company was already investigating the container orchestration system in 2017 noted Paul Fisher and Ashley Kasim, Staff Software Engineers at Lyft, during KubeCon Europe 2020. They realized the need for a networking platform that could operate both the legacy stack and Kubernetes. This led to the creation of cni-ipvlan-vpc-k8s, Lyft’s virtual private cloud (VPC) container networking interface (CNI) stack, which was later open sourced.
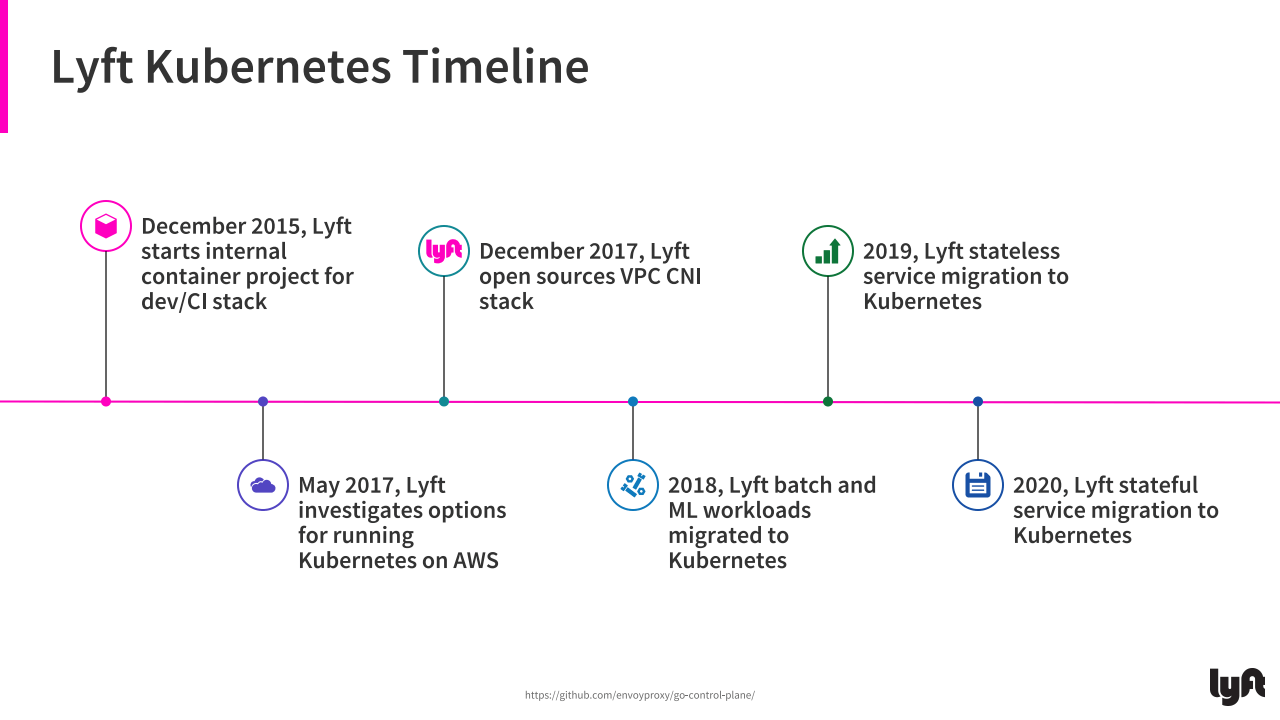 Lyft’s migration timeline (Image credit)
Lyft’s migration timeline (Image credit)In 2018, Lyft batch and machine learning workloads were migrated to Kubernetes. Next were the company’s stateless services in 2019 and stateful services in 2020.
Currently, Lyft has multiple clusters for its different services. The company has a cluster with over 5,000 pods running machine learning workloads. Flyte, a distributed processing platform for machine learning and data workflows, which was also open sourced in 2019, runs on another cluster with more than 10,000 pods.
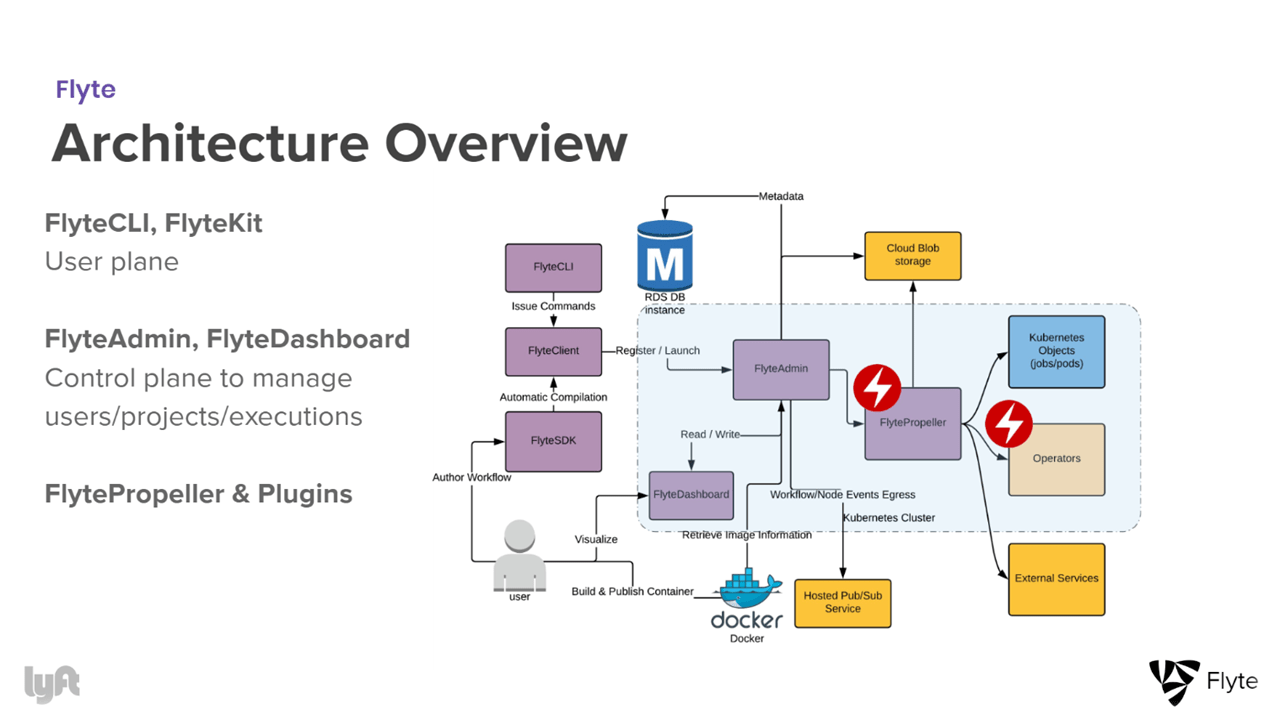 Flyte’s high-level architecture (Image credit)
Flyte’s high-level architecture (Image credit)Lyft’s largest cluster is dedicated to its ridesharing service. This consists of over 600 stateless microservices and about 300,000 containers running on a single Envoy mesh. The cluster has around 30,000 pods that automatically scale up or down.
 Lyft’s Kubernetes stack (Image credit)
Lyft’s Kubernetes stack (Image credit)“The reason we can have this multicluster environment that works is that we are keeping it as simple as possible. There are no overlay networks and NAT. There’s very limited use of ingress. We don’t use kube-proxy. Pods can communicate with pods in other clusters, and Envoy binds it all together.”
—Paul Fisher, Lyft
Managing multiple clusters
Lyft uses EnvoyManager, a custom control plane, to operate its multicluster environment. According to Ashley, EnvoyManager is mounted on top of go-control-plane, and it uses Kubernetes informers and Lyft’s in-house discovery implementation to monitor pods and bridge the mesh across clusters.
Lyft service pods run on an Envoy sidecar container. The sidecars then use DNS to locate EnvoyManager, which is run locally on the cluster as a headless service. The services run pods on end clusters that are redundant, making them resilient to outages.
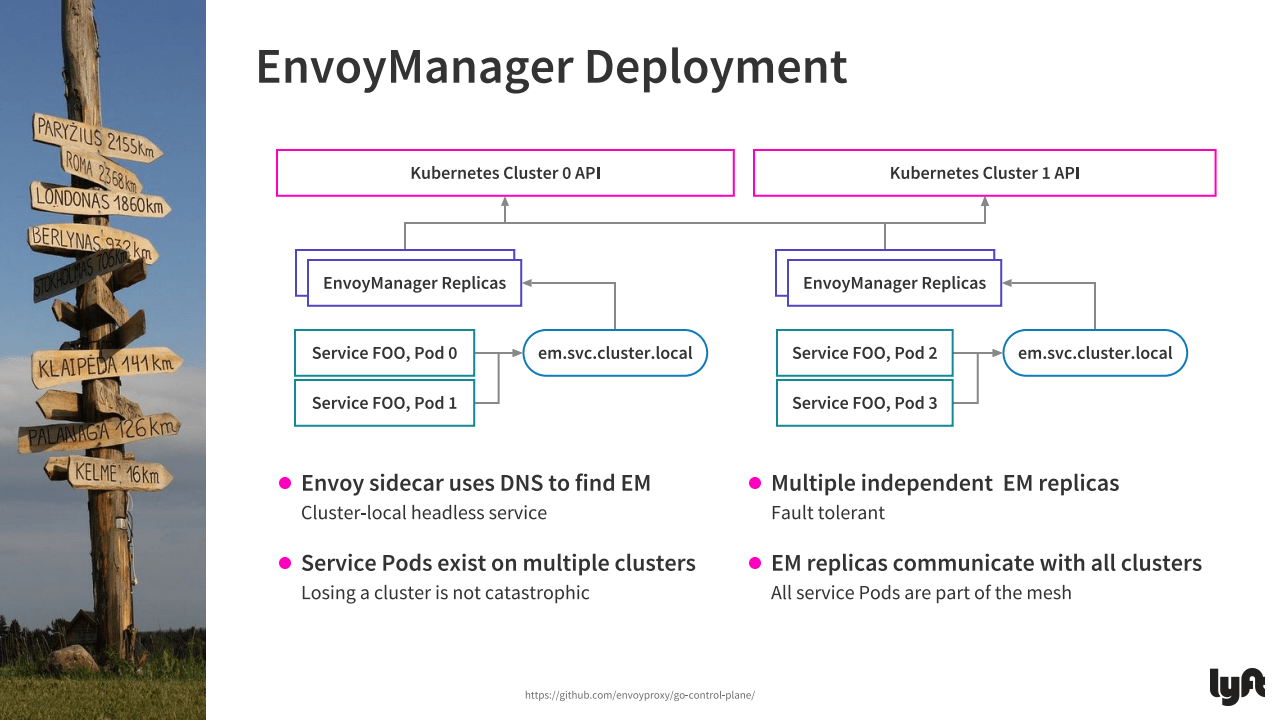 Multiple clusters communicating via EnvoyManager (Image credit)
Multiple clusters communicating via EnvoyManager (Image credit)EnvoyManager is fault-tolerant as its multiple independent replicas are deployed across end clusters. This also ensures scaling depending on the load.

Ashley Kasim
“Each EnvoyManager talks to API servers of Kubernetes clusters. This means that each EnvoyManager has a complete picture of the whole state of the network, even though each Kubernetes cluster remains completely independent.”
—Ashley Kasim, Lyft
Lyft is currently working on improving EnvoyManager. With the beta introduction of EndpointSlices in Kubernetes v1.17, the company is investigating a scalable implementation for tracking a large number of networking points. Lyft’s engineering team is also considering switching from a pod informer to an endpoint informer to resolve a few control plane issues.
Want details? Watch the videos!
In this video, Lita Cho and Jose Nino explain how Lyft utilizes Envoy to split traffic between the legacy and Kubernetes infrastructures.
In this next video, Paul Fisher and Ashley Kasim discuss how Lyft manages its multicluster Kubernetes deployment.
Further reading
- The Ways to Streamline Apps and Ops on Azure Kubernetes Service
- Maturity of App Deployments on Kubernetes: From Manual to Automated Ops
- Considerations for Running Stateful Apps on Kubernetes
About the experts

Vicki Cheung is a cofounder and CTO at Stealth. Previously, she was Engineering Manager at Lyft, where she helped drive the company-wide Kubernetes migration. Vicki managed the team responsible for the compute fleet of Lyft’s workloads. Prior to Lyft, she was Head of Infrastructure and Founding Engineer at OpenAI, where Vicki and her team built out a Kubernetes-based deep learning infrastructure. Additionally, she spent time on managing, recruiting, designing engineering interviews, as well as leading diversity and inclusion efforts.

Jose Nino is Staff Software Engineer at Lyft. He has worked on the networking team for 2+ years building out the infrastructure that enabled the company to scale technically and socially, as it developed and rolled out an Envoy-based service-oriented architecture. Jose was instrumental in building control plane technologies and resilience improvements that allowed Lyft to grow to a 2,000+ engineer organization with 500+ microservices.

Lita Cho is a cofounder and CTO at Moment Technologies. Previously, she was Staff Software Engineer at Lyft, where Lita worked on the networking team, building out the service mesh to handle both Kubernetes and legacy systems. She also maintained the tracing infrastructure at Lyft. Before that, Lita worked on building out the API infrastructure using Protocol Buffers, creating systems that would generate code and bring type safety to Lyft’s polyglot microservice architecture.

Paul Fisher is Staff Software Engineer at Lyft, where he works on all things infrastructure-related from monitoring software to the service provisioning stack. He’s currently leading the Lyft migration to Kubernetes. Paul tends toward work that lies at the intersection of systems programming and scale. He has previously spoken at Monitorama and has worked on systems at Twitter, UC Berkeley, Red Hat, and the Free Software Foundation.

Ashley Kasim is Staff Software Engineer at Lyft. She is part of the compute infrastructure team at the company. Ashley is currently working on building out a resilient Kubernetes infrastructure that enables Lyft to run at scale.




