
Considerations for Running Stateful Apps on Kubernetes

The challenges with stateful apps
Stateful applications pose certain difficulties when deployed in a cloud. They may be hard to scale in a distributed, virtualized environment. In addition, limiting data stores to specific locations is not that easy in an environment where virtual machines themselves are stateless. As a result, stateful apps may become unstable in the cloud.
At the recent Kubernetes meetup, Bogdan Matican of YugaByte provided considerations on how to ensure running stateful apps on Kubernetes deployments, taking care of performance, data resilience, service integration, Day 2 operations, etc.
 Bogdan Matican of YugaByte
Bogdan Matican of YugaByteAccording to Bogdan, the very essence of a stateful application is embodied in the following aspects:
- Ordered operations, which are encapsulated in the sequencing required to deploy an app. It means you first run one set of operations that bring up the metadata tier, and then you run the second set of operations that bring up you actual data tier.
- Stable network IDs instead of IPs, which you can’t rely upon when it comes to brining up pods.
- Persistent volumes for the pods to have access to the data even across restarts or if the data is moved from one node to another.
To address the issues related to implementing these aspects, containerization may come as a pill to the trouble. Luckily, Kubernetes has some tools for that, making the process easier.
Involving StatefulSets on Kubernetes
One of the major reasons for choosing Kubernetes for the purpose is unified orchestration for both stateful and stateless apps. This means one can enjoy the same set of compute, storage, and network primitives across web and API servers, message queue, cache, database, and file stores. The other reason is consistent and declarative provisioning across all environments (testing, staging, production, etc.).

“If you are using Kubernetes, you, probably, speak YAML for a living and deploy applications to Kubernetes the same way you do to your local minikube or your pre-production environment. You are essentially using the same type of primitives to get your application deployed in any type of an environment.” —Bogdan Matican, YugaByte
To ensure all of the above mentioned, one can make use of StatefulSets in Kubernetes, which are workload API objects used to manage stateful applications. StatefulSets operate the same way as a controller: once you define the desired state in a StatefulSet object, its controller initiates the required updates to get there from the current state.
There are three major components underlying a StatefulSet:
- A Headless Service, which is used to control the network domain.
- The StatefulSet itself, which has a spec that indicates the number of replicas in the container to be launched in unique pods.
- The volumeClaimTemplates, which provides stable storage using PersistentVolumes provisioned by a PersistentVolume Provisioner.
So, StatefulSets make it possible to achieve:
- Ordered operations with ordinal index. It means that for a StatefulSet with
nreplicas, each pod in the StatefulSet will be assigned an integer ordinal, from0up throughn-1, which is unique over the Set. - Stable and unique network ID/name across restarts. This means that re-spawning a pod will not make the cluster treat it as a new member.
- Persistent storage linked to the ordinal index/name. This helps to attach the same persistent disk to a pod even if it gets rescheduled to a new node.
- Mandatory headless service (no single IP) for integrations. This way, you don’t need a load balancer, smart clients are aware of all the pods and connect to any of them.
“If one of your pods dies, you want to be able to reattach the exact same data back to exactly the same pod, because, realistically, if I used to be serving this batch of users, I want to be serving the same batch of users if I know that I am referring to the same data.” —Bogdan Matican, YugaByte
“You can directly send requests to the underlying pods if your clients are smart enough to know exactly where a certain piece of data lives, then this is a particularly useful aspect to bypass a load balancer.” —Bogdan Matican, YugaByte
Bogdan exemplified the usage of StatefulSets on YugaByte DB, a transactional database for cloud-native solutions, and you can find the source code behind the deployment in this GitHub repo.
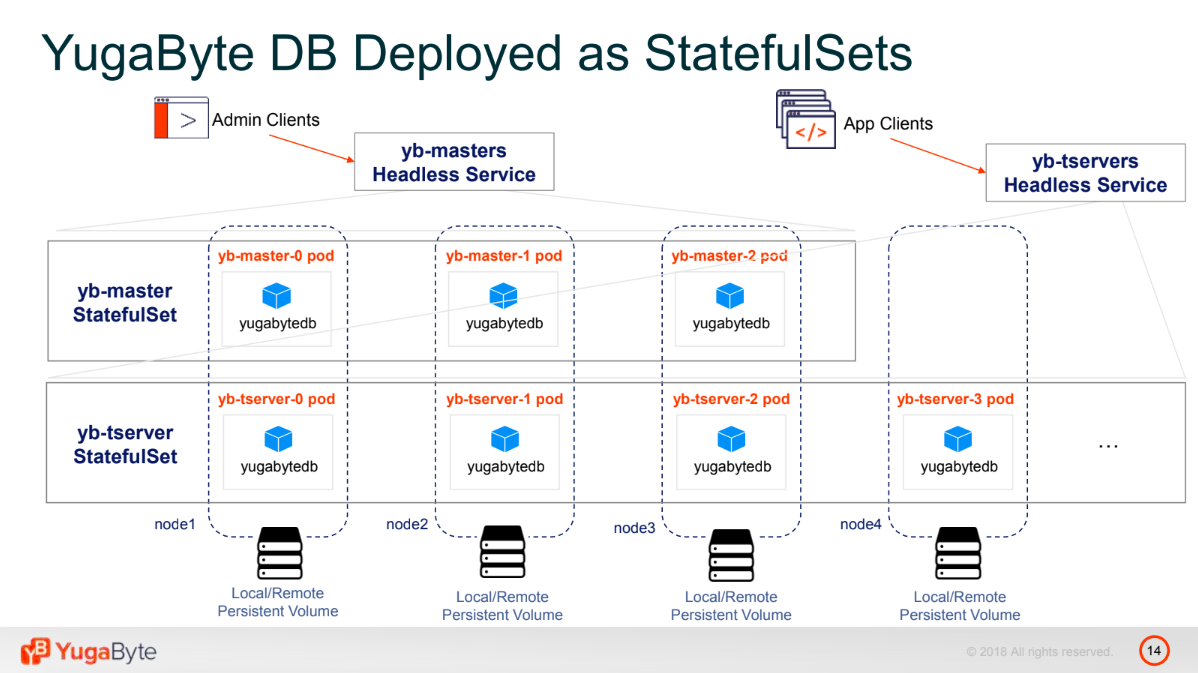 YugaByte DB deployed as StatefulSets (Image credit)
YugaByte DB deployed as StatefulSets (Image credit)StatefulSets became available as alpha in July 2016, beta followed in December 2016, and the stable version is available since December 2017, so they are still quite fresh.
Considerations for developers
There is also a couple of things to bear in mind while running stateful applications on Kubernetes. Firstly, one wants to achieve high performance, which heavily depends on the underlying storage you choose. Typically, there are two choices available: local and remote storage.
With local option, you get lower latency and higher throughput. For latency-sensitive apps, one may use SSDs. This type is recommended for workloads that do their own replication. Under local storage, pre-provisioning happens outside of Kubernetes.
“Local storage comes with a local node, it is super fast, because you don’t get extra networking involved, you don’t get customized RPC layer that you have actually to go through. However, it also happens to be expensive, because it’s local SSDs. And, furthermore, it’s ephemeral, if your node goes down, you’ve lost all your data.” —Bogdan Matican
A remote option provides you with higher latency and lower throughput. It is recommended for workloads that don’t perform any replication on their own. In addition, one is able to provision dynamically right inside Kubernetes. Remote storage can also be employed alongside local storage for cost-efficient tiering.
“On the flip side, you’ve got remote storage like a typical EBS on Amazon. This is already a remote endpoint, so you get through a network hub, it’s also replicated at that layer, which means you go through extra performance hit of doing replication at that layer, however it’s cheaper. And it’s already available as a primitive in Kubernetes, and it stays there. If you lose your application node, your data is still around in the distributed ecosystem.”
—Bogdan Matican, YugaByte
In terms of data resilience, one can make use of pod anti-affinity. This feature in Kubernetes implies that pods of the same type should not be scheduled on the same node, so that in case of a node failure, you won’t lose your data.

“What happens if you provision really beafy nodes? Let’s say, you provision three nodes with the intention to run your pods on different machines. But the requirements you set for your pods are so low that Kubernetes will be able to schedule three pods on the same node. When it does so, if you lose that node, you lose your entire data. Realistically, what you want to do is to be able to ensure your application tier can specify to the Kubernetes scheduler that it wants to ensure certain types of pods are not scheduled together at the same time. This is where the concept of anti-affinity comes in.” —Bogdan Matican, YugaByte
When it comes to multi-zone pod scheduling, you have to tolerate zone failures for Kubernetes slave nodes, whereas in case in of regional pod scheduling, you tolerate zone failures for both slave and master nodes. A multi-region pod scheduling requires federation of clusters.
Talking about integration with app services, let’s take a look at a sample architecture, involving the usage of Kafka and ZooKeeper alongside with StatefulSets. If you are in the ZooKeeper service, and you want it to interact with Kafka, and you’ve configured it to happen by a pod name, routing will just work like this. If you are in the Kafka service, but you’re still part of the same namespace, you just need to qualify the pod name with the particular service you want to rout to, and this will rout the queries directly to that pod bypassing the load balancer.
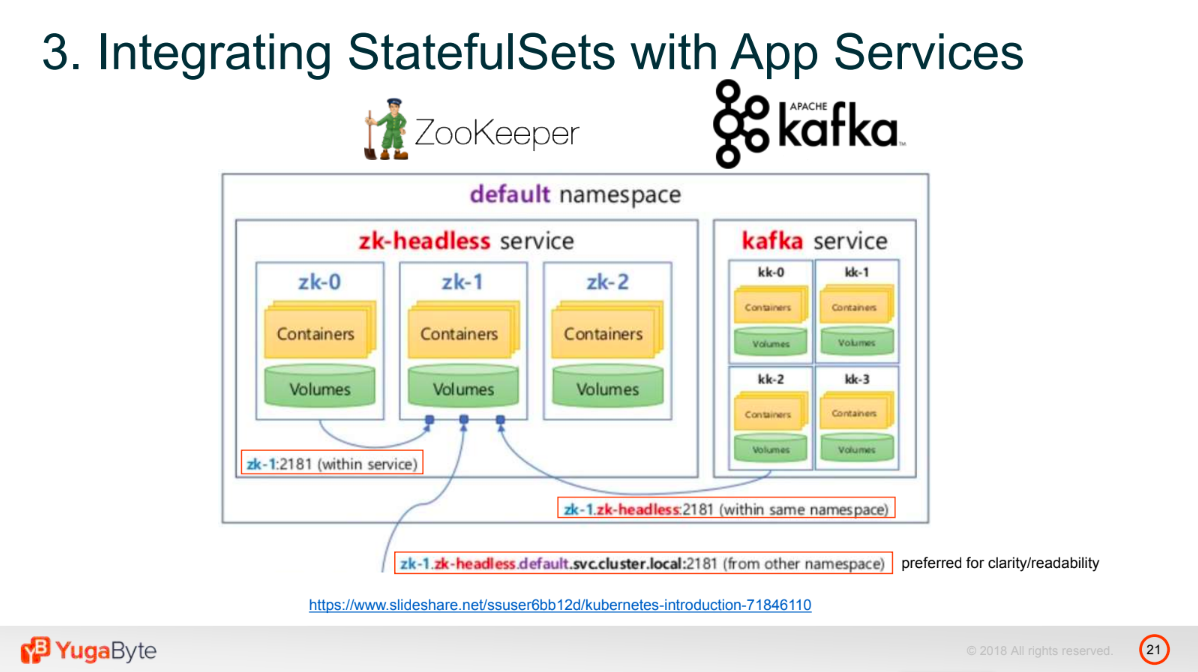 A sample app using Kafka, ZooKeeper, and StatefulSets (Image credit)
A sample app using Kafka, ZooKeeper, and StatefulSets (Image credit)
Considerations for operators
What about Day 2 operations, such as handling failures? Pod failures are handled by Kubernetes automatically, while node failure has to be handled manually by adding a new slave node to a cluster. Local storage failure is also treated manually via mounting a new local volume to Kubernetes.
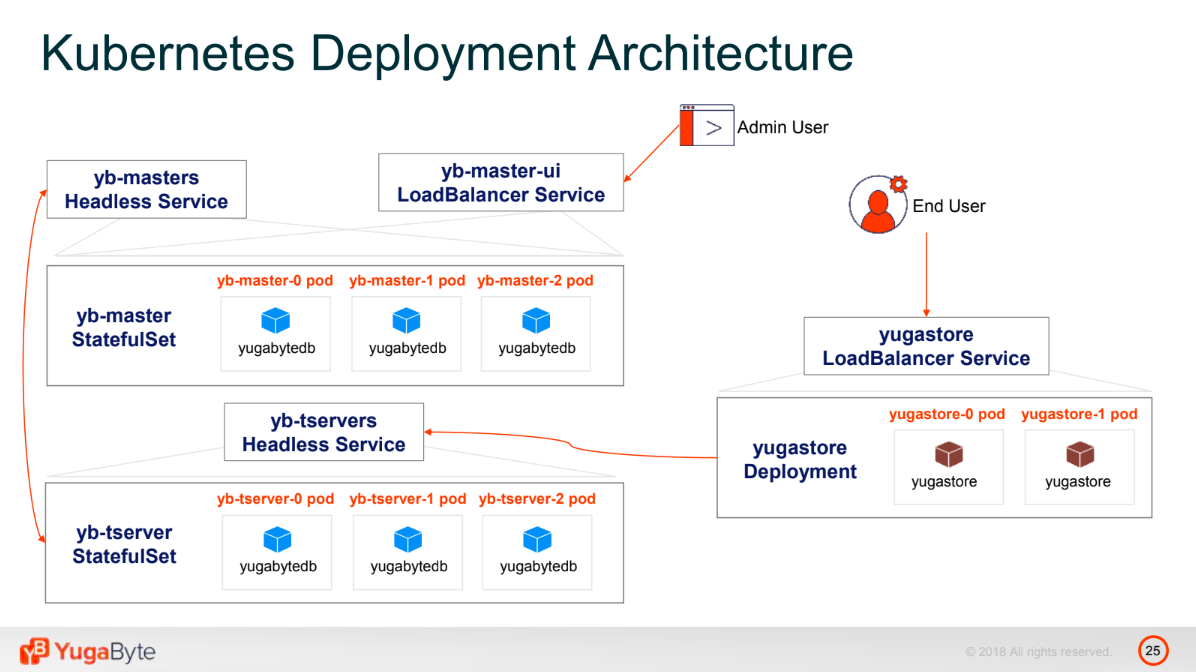 A sample architecture of a stateful app deployed on Kubernetes (Image credit)
A sample architecture of a stateful app deployed on Kubernetes (Image credit)Kubernetes supports two rolling upgrade strategies: onDelete (default) and rollingUpgrade. The best variant is to pick up a strategy for a database is to choose the one that supports zero-downtime upgrades.
As Bogdan put it, backups and restores represent a database-level construct, and noted that it makes sense to restore the backup into an existing cluster or a new cluster with a different number of tservers.
To get more control over operations, one can create a custom controller in Kubernetes for the purpose he/she needs. To get more recommendations for running a stateful app on Kubernetes, watch the video below.
At the end of his session, Bodgan also demonstrated a sample bookstore app functioning as a stateful one and deployed to Kubernetes. Find the source code in this GitHub repository.
Want details? Watch the video!
Table of contents
|
These are the slides demonstrated by Bodgan.
Further reading
- NetApp Builds Up a Multi-Cloud Kubernetes-as-a-Service Platform
- Integrating Calico and Istio to Secure Zero-Trust Networks on Kubernetes
- Managing Multi-Cluster Workloads with Google Kubernetes Engine
About the expert

Bogdan Matican is a Founding Engineer at YugaByte, working across all aspects of the product, from core database features to the enterprise administration console. He has been working on distributed systems for over 5 years in such companies as Facebook and UCar, where he was engaged in enabling stream processing, monitoring, data analytics, etc. Bogdan is also an active researcher in the fields of security and cluster management.





