
Managing Multi-Cluster Workloads with Google Kubernetes Engine

The challenges of workload management
When deploying application on Kubernetes, users have to rely on the kubectl command-line tool. While this isn’t a problem in itself, a more in-depth understanding of the tool is necessary when dealing with stateful workloads and workloads that require hardware acceleration, as well as enabling low latency across multiple clusters.
Some of the native features available through Google Kubernetes Engine (GKE)—a distribution of the open-source Kubernetes on Google Cloud Platform—may come helpful when addressing these types of tasks. At a recent Kubernetes meetup in Sunnyvale, Anthony Bushong of Google drew the audience’s attention to those distinct features of GKE, which aim at facilitating cluster management:
- global presence with multi-cluster ingress
- GPUs as a service with GPU node pools
- high availability for stateful workloads with regional persistent disks

“In a Google Kubernetes Engine cluster, we actually fully abstract the management of the control plane for you. We want users to focus on deploying applications and not on managing infrastructure just to have a functioning cluster.” —Anthony Bushong, Google
Multi-cluster ingress
For workloads running on multiple clusters located across the world, latency can be an issue if routing is not properly configured. GKE makes use of kubemci—a tool designed to configure Kubernetes ingress to load-balance traffic across multiple clusters. With kubemci, it is possible to route users to the clusters regionally closest to them—thus, achieving low latency. In case of a failover, the traffic is routed to the next closest cluster.
In the following diagram, three different users from San Francisco, Manila, and Paris are directed to a single global virtual IP (VIP) address. This global VIP address, in turn, routes each of those users to the closest cluster in their respective regions.
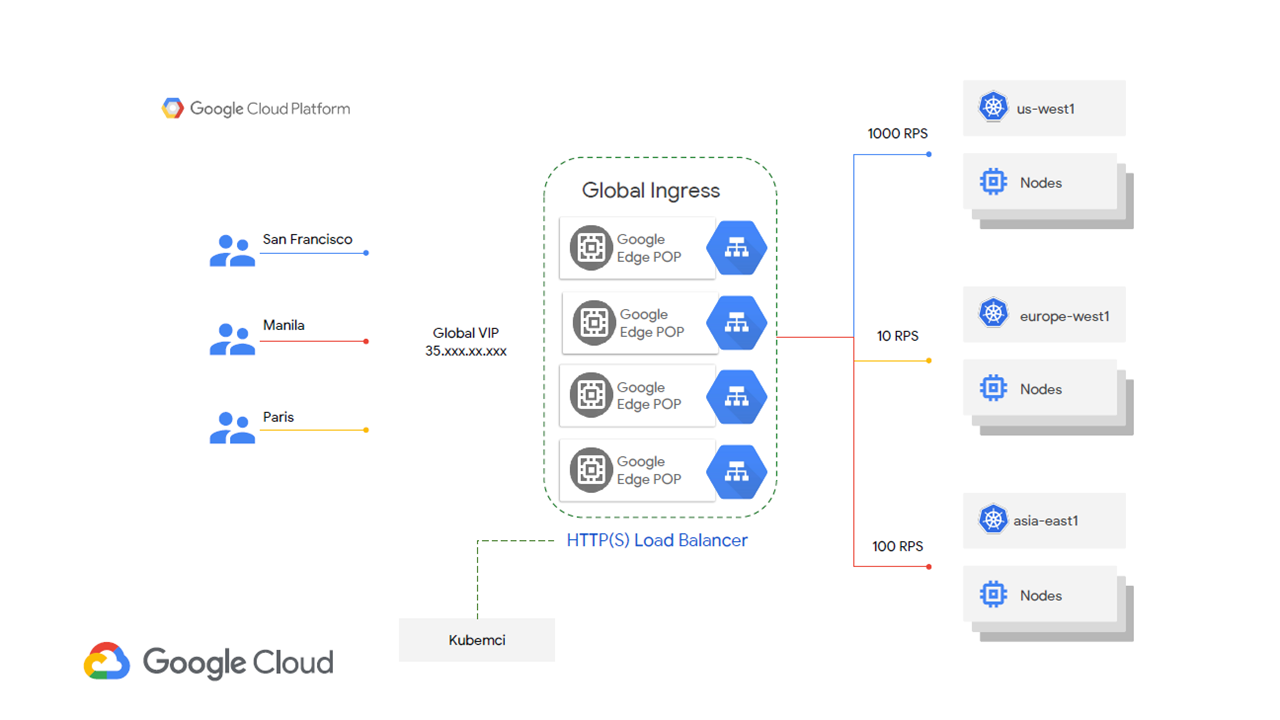 Google Kubernetes Engine sets up a global ingress point (Image credit)
Google Kubernetes Engine sets up a global ingress point (Image credit)Currently, kubemci is available in beta and covers a specific scope of production-grade tasks. For instance, one may update the deployed multi-cluster ingress, delete it, remove clusters from it, or get its status. For details, you may check out the official guide. This way, kubemci seems to be rather a temporary solution, which may be later replaced by an implementation, which uses kubectl.

“Kubemci automically configures the load balancer to have your different clusters across the world as back ends.” —Anthony Bushong, Google
Regional persistent disks
Users who run stateful workloads require high availability and failover across multiple zones. Stateful workloads are often dependent on a persistent volume. In case of a node failure, it cannot be moved to a different node when using zonal persistent disks.
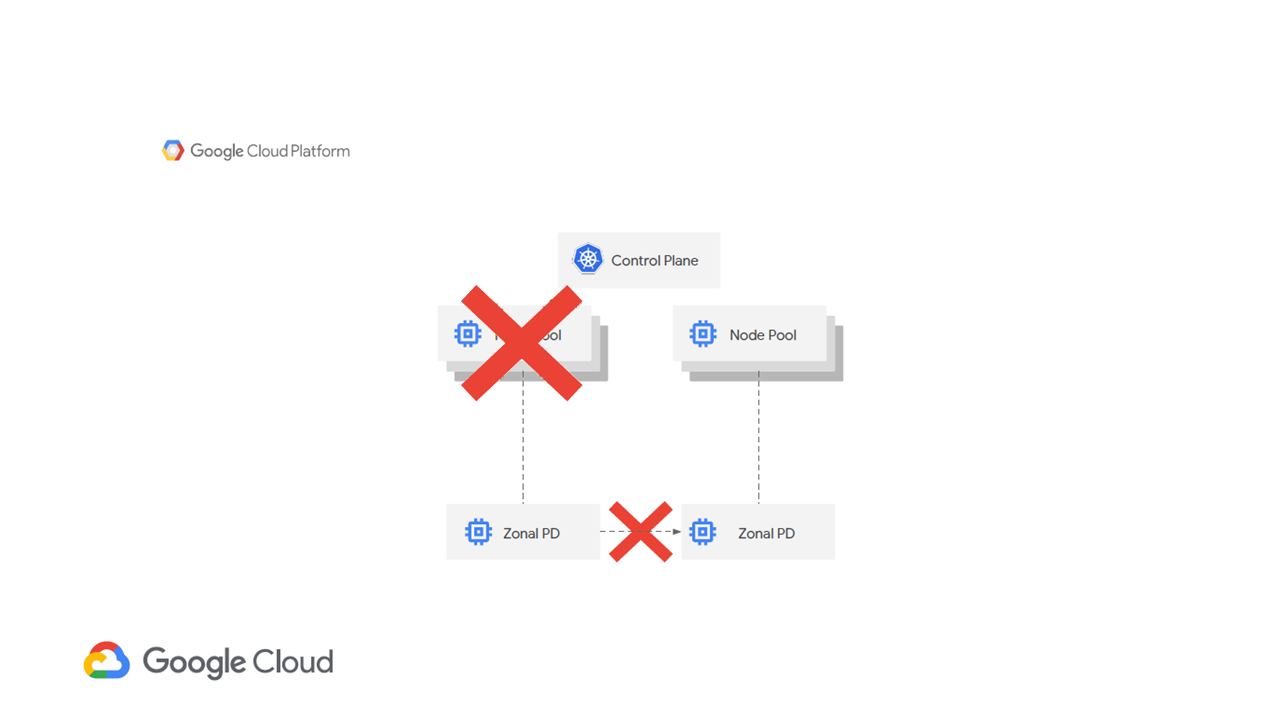 Stateful workloads cannot be moved in a zonal storage configuration (Image credit)
Stateful workloads cannot be moved in a zonal storage configuration (Image credit)To achieve stability, one may employ regional persistent disks. With the force-attach command, you can trigger a failover of a workload running on a regional persistent disk to a VM instance in a different zone.
“Google Kubernetes Engine now supports the concept of regional persistent disks. If a failure occurs in zone A, workloads can be migrated to zone B and they’ll still be able to find their persistent volume.” —Anthony Bushong, Google
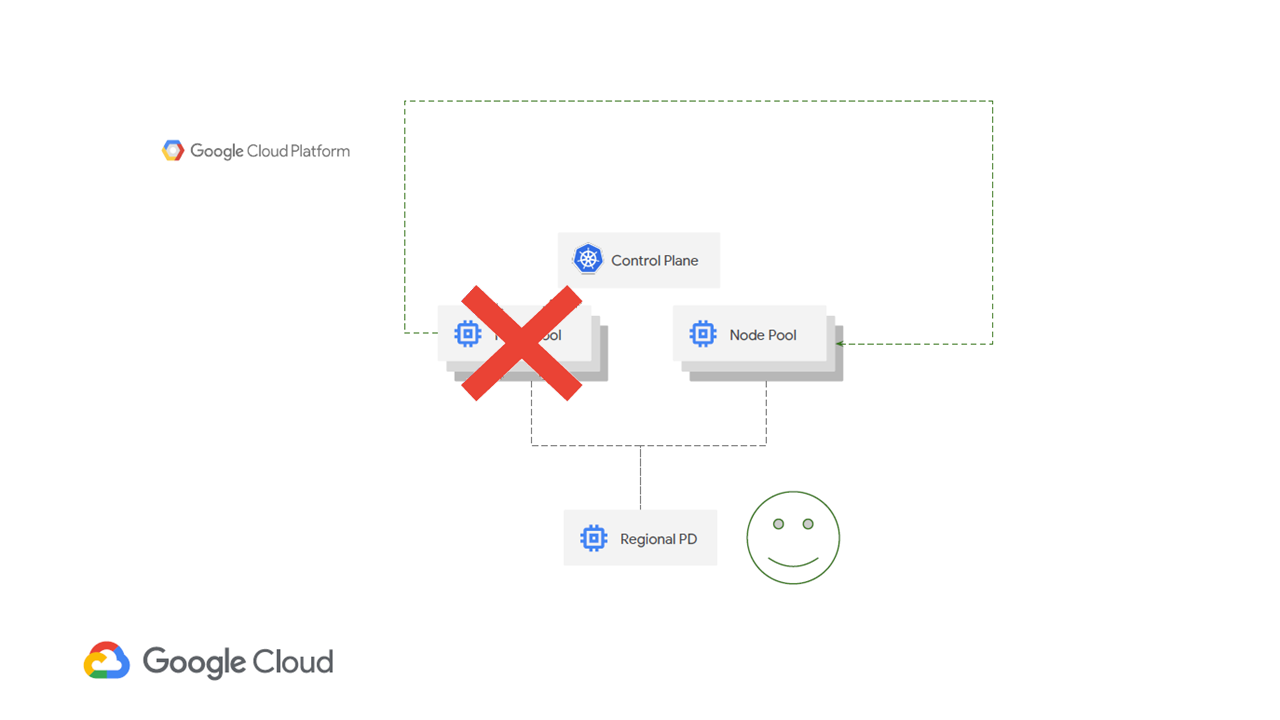 With regional persistent disks, workloads can be moved in case of a failure (Image credit)
With regional persistent disks, workloads can be moved in case of a failure (Image credit)
GPUs as a service
Compute-intensive workloads require a decent number of processors unless you want to compromise on performance. Within GKE, one may employ node pools equipped with NVIDIA Tesla GPUs. To get access to GPUs, users can request for them through kubectl and specify a limit in the manifest.
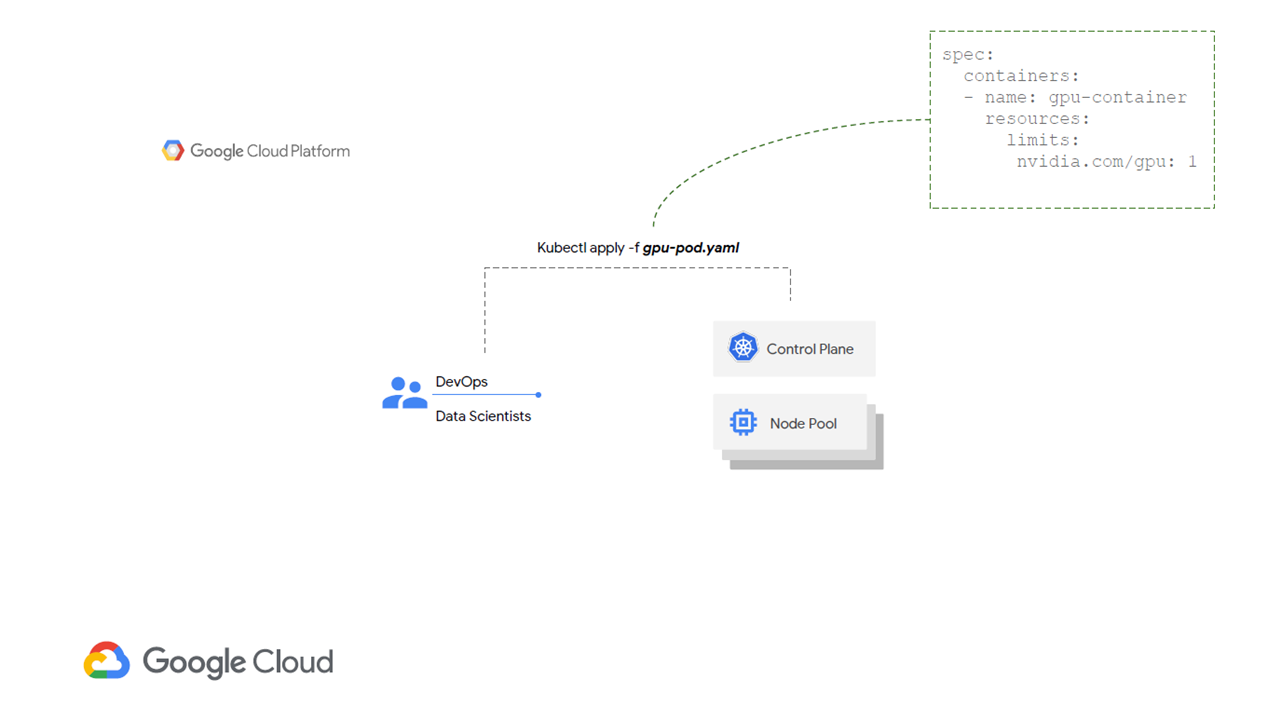 A single GPU is specified in the
A single GPU is specified in the gpu-pod manifest (Image credit)This feature also supports multiple GPU types per cluster by including a node selector parameter in the manifest.
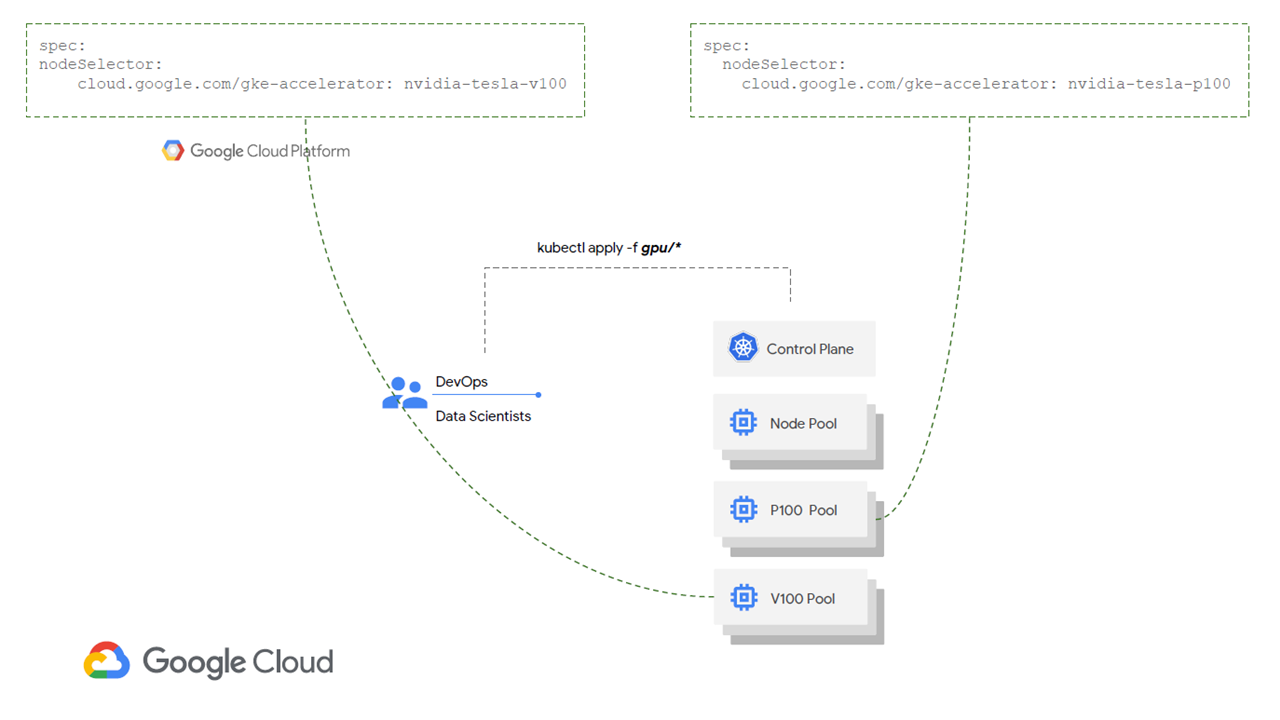 P100 and V100 GPU pools have a unique identifier (Image credit)
P100 and V100 GPU pools have a unique identifier (Image credit)Autoscaling of clusters is also available, so one may scale down idle GPU nodes. However, one can’t add GPUs to the already existing node pools, and GPU nodes can’t be live migrated once any maintenance is taking place.
“Whether you’re running GPUs on premises or in the cloud, they’re expensive, so we want to maximize our use of them.” —Anthony Bushong, Google
Google claims this feature is fit for addressing such compute-intensive tasks as image recognition, natural language processing, video transcoding, etc.
While there is an increasing amount of options when it comes to deploying Kubernetes, managing clusters can still be complicated. GKE is taking steps towards abstracting cluster management to help users focus on deploying and running applications.
Want details? Watch the video!
Related slides
Further reading
- A Multitude of Kubernetes Deployment Tools: Kubespray, kops, and kubeadm
- Kubo Enables Kubernetes Environments Managed by Cloud Foundry’s BOSH
- Deploying Services to Cloud Foundry Using Kubernetes: Less BOSH, More Freedom
About the expert






