
LinkedIn Aims to Deploy Thousands of Hadoop Servers on Kubernetes

Different security models
Hadoop is a collection of open-source software for utilizing a computer network to solve problems around massive amounts of data and computation. It provides a framework for distributed storage and big data processing. For the past 10 years, LinkedIn has invested heavily in this technology, becoming one of the largest Hadoop data lake operators in the world. The organization has over 10 Hadoop clusters, the largest consisting of 7,000+ servers with a storage capacity of 400+ PB.
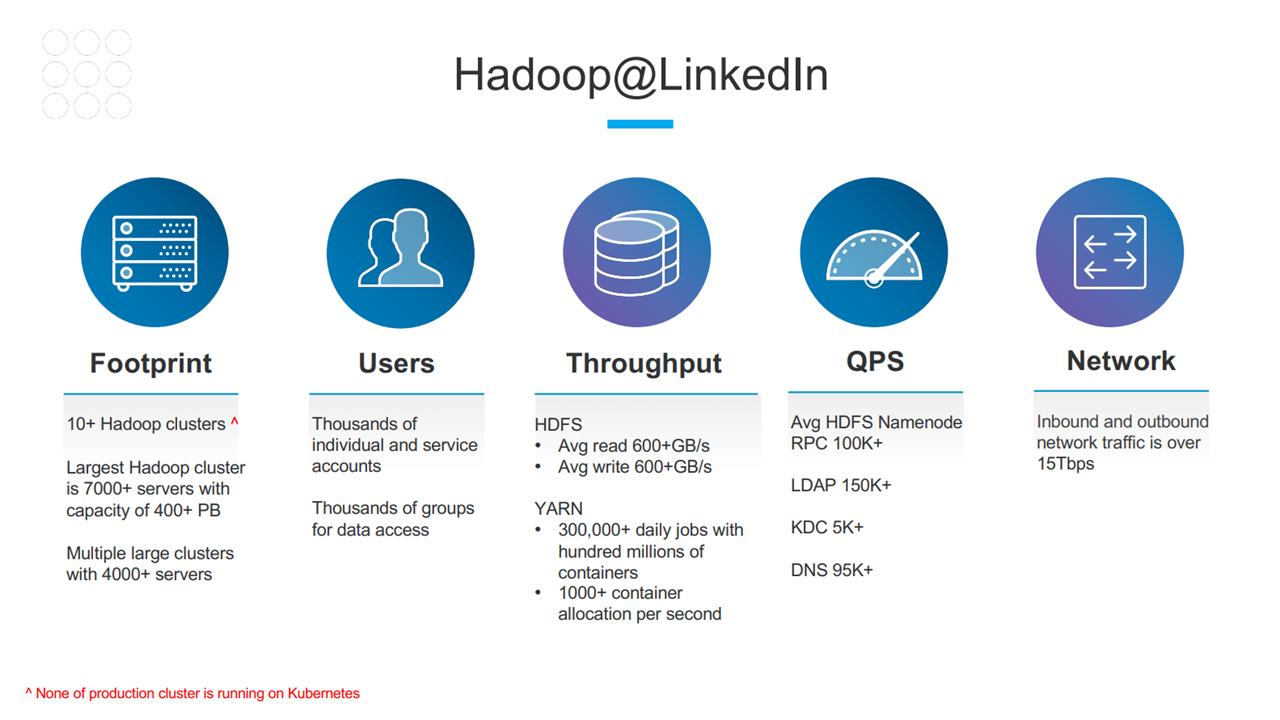 The Hadoop footprint at LinkedIn (Image credit)
The Hadoop footprint at LinkedIn (Image credit)In the past few years, Kubernetes rapidly grew in popularity, and LinkedIn saw the opportunity to use the platform for its artificial intelligence (AI) workloads. However, according to Cong Gu, Senior Software Engineer at LinkedIn, before any adoption could occur, the organization needed to address the gap between the security models of Kubernetes and Hadoop.

Cong Gu
“To enable LinkedIn AI jobs running on Kubernetes, we first need to tackle the problem of accessing a Hadoop data file system (HDFS) from Kubernetes. However, there is a gap in authentication between the two services.”
—Cong Gu, LinkedIn
During KubeCon Europe 2020, Cong Gu along with Abin Shahab and Chen Qiang of LinkedIn revealed how the organization solved these and other issues when integrating Hadoop and Kubernetes.
Binding Hadoop and Kubernetes
Hadoop uses Kerberos, a three-party protocol built on symmetric key cryptography that ensures anyone accessing a clusters is who they claim to be. The LinkedIn team introduced the concept of delegation tokens—a two-party authentication method—to avoid the necessity to always authenticate against a Kerberos server.
By default, the Hadoop delegation token has a lifespan of a day and can be renewed up to seven days. Meanwhile, Kubernetes authenticates via certificates and does not expose the job owner in any of its public-facing APIs. As a result, it is impossible to verify the authorized user from the pod through the native Kubernetes API, and then employ the username to fetch the Hadoop delegation token for HDFS access.
For the integration purposes, LinkedIn created and open-sourced Kube2Hadoop, a project that enables secure HDFS access from Kubernetes. The tool has the following functionality:
- integrates the Hadoop authentication mechanism that uses delegation tokens
- renews delegation tokens to support long-term jobs
- incorporates lightweight directory access protocol (LDAP) for fine-grained access control, enabling users to proxy as themselves or as headless accounts
- generates GDPR-compliant auditable logs and helps administrators to figure out who is accessing data at what time
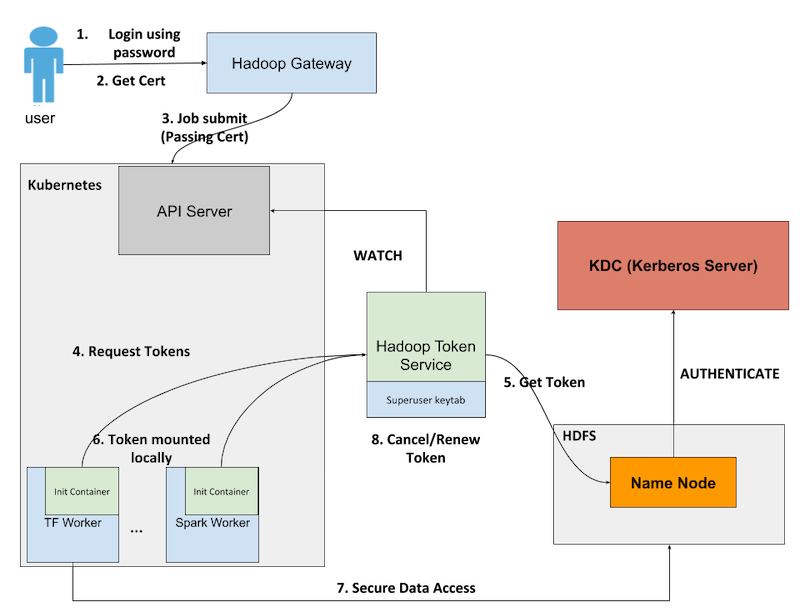 An example of the Kube2Hadoop authentication workflow (Image credit)
An example of the Kube2Hadoop authentication workflow (Image credit)According to the article by Cong Gu, Abin Shahab, Chen Qiang, and Keqiu Hu of LinkedIn, Kube2Hadoop has three major components:
- Hadoop Token Service fetches delegation tokens on behalf of a user. It is deployed as a Kubernetes Deployment.
- Kube2Hadoop Init Container resides in every worker that needs to access HDFS. The component sends a request to Hadoop Token Service for fetching a delegation token.
- IDDecorator writes authenticated userID as an immutable annotation in each pod.
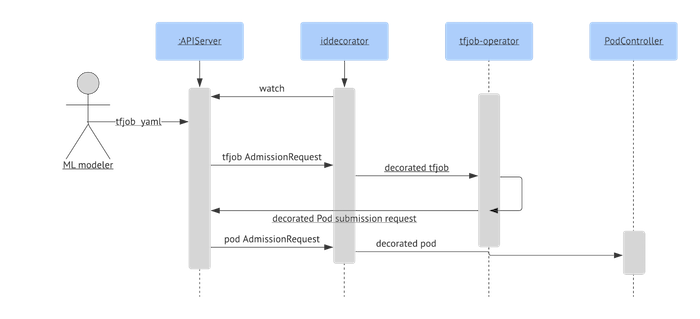 An example of the Kube2Hadoop IDDecorator workflow (Image credit)
An example of the Kube2Hadoop IDDecorator workflow (Image credit)Read the original article by the LinkedIn team for the workflow and additional details.
Issues with network throughput and init container
When LinkedIn started to experiment with Kube2Hadoop in production, the team encountered two major problems related to network throughput and launch speeds of init containers.
Initially, users running synchronous distributed training on the host network could consistently get a rate of 900 Mb/s.
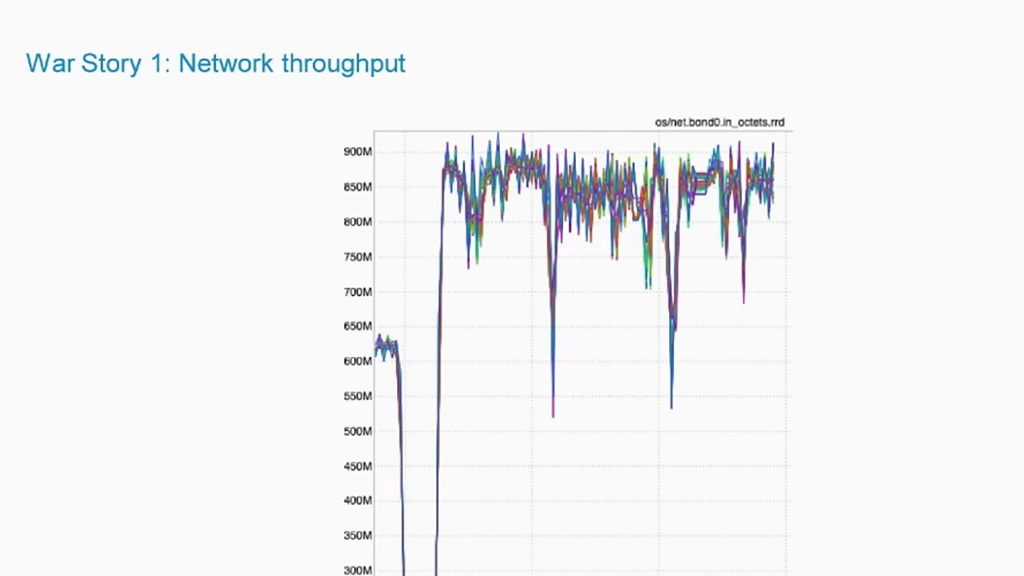 Throughput on a host network (Image credit)
Throughput on a host network (Image credit)Once the team switched over to a pod network for Kube2Hadoop to get pod IP addresses, the users’ network throughput went down to around 140 Mb/s.
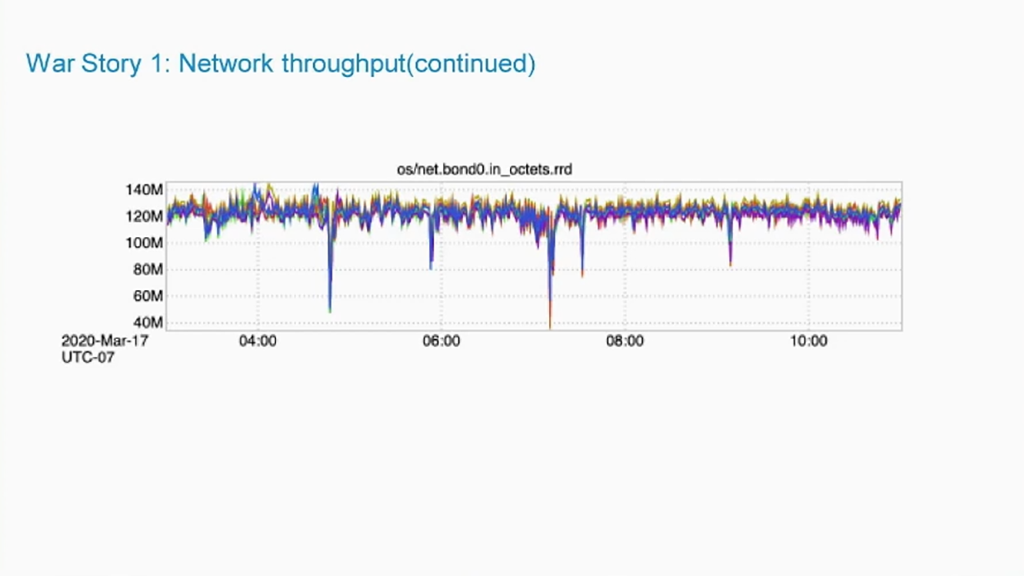 Throughput on a pod network (Image credit)
Throughput on a pod network (Image credit)The second problem were customer complaints about slow launch speeds of init containers. According to Cong, this slow down was intentional to allow the Kubernetes API server to propagate IP addresses.
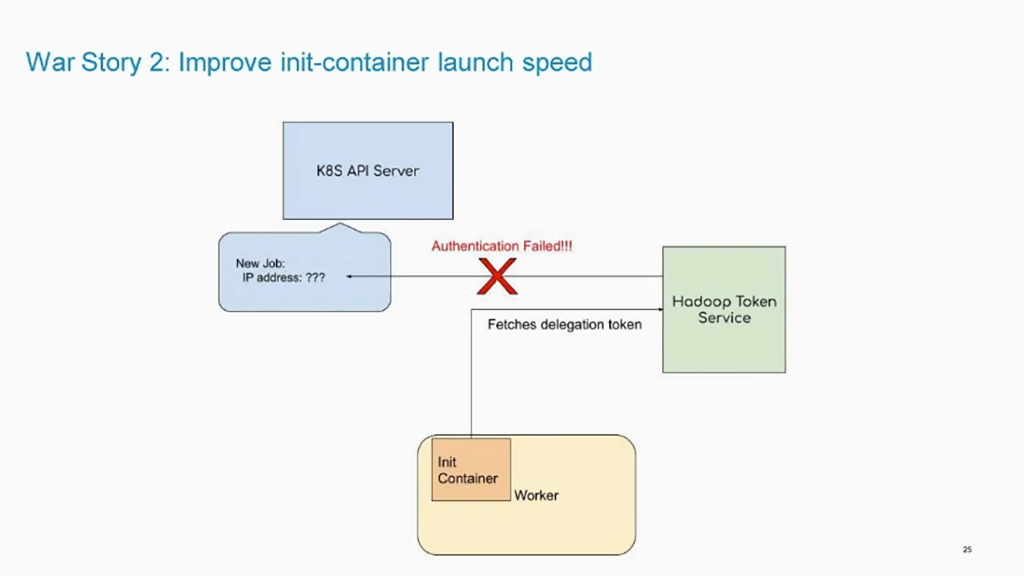 Propagation of IP addresses (Image credit)
Propagation of IP addresses (Image credit)To resolve both the issues, the LinkedIn team made use of the TokenRequest and TokenReview APIs available in Kubernetes v1.14.
“Using tokens instead of IP addresses as authentication, we no longer need to bind ourselves to the pod network. Thus, we can support hosted network jobs. Since we won’t face the IP address propagation issue, we can potentially speed up our init container by a very big margin.” —Cong Gu, LinkedIn
Integration challenges
While running Hadoop on Kubernetes, LinkedIn faced a few challenges related to domain name server (DNS), identity, network, and orchestration. Chen Qiang, Engineering Manager and Data Site Reliability Engineer at LinkedIn, provided an overview of each problem and explained how the team resolved them.
According to Chen, each Hadoop worker or HDFS data node communicate with each other using host names. However, by default, there is no global resolvable hostname associated to each. To address the DNS issue, the LinkedIn team made use of Kubernetes StatefulSets with a headless service to provide every pod a global resolvable hostname. Additionally, a resolvable hostname was injected into the main container.
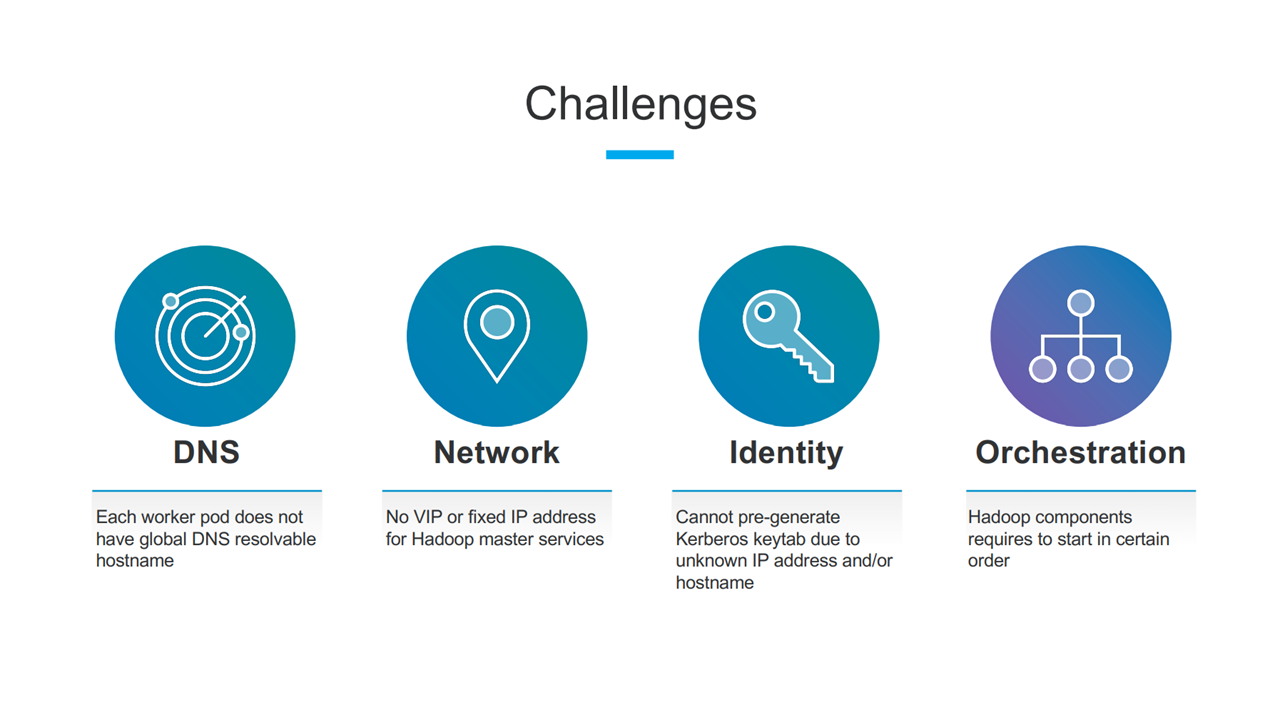 Challenges encountered when integrating Hadoop and Kubernetes (Image credit)
Challenges encountered when integrating Hadoop and Kubernetes (Image credit)Next, there are many components in Hadoop that communicate with each other, while the cluster is up and running, but there are no fixed IP addresses for Hadoop master services. By creating a Kubernetes Service for every Hadoop administrator instance, LinkedIn delivers a predefined and structured DNS-resolvable hostname that can be predetermined in Hadoop configuration files.

Chen Qiang
Additionally, the LinkedIn team encountered an issue around identity related to secure Hadoop clusters with Kerberos enabled. To authenticate, each Hadoop cluster uses a keytab file that includes part of the hostname. However, hostnames have random IP addresses, making it impossible to pregenerate keytabs. To resolve this problem, the team introduced a Keytab Delivery Service (KDS) that uses the authentication mechanism of Kube2Hadoop.
Finally, there is a strong dependency between Hadoop components, making the bootstrap order critical. While the bootstrap order can be orchestrated externally, this introduces additional complexity and prolongs deployment. In response, the LinkedIn team introduced built-in dependencies using an init container with Kubernetes service discovery. This way, all pods can be deployed simultaneously, effectively reducing cluster deployment time down to two minutes.
“Hadoop on Kubernetes may change the way big data infrastructure runs. A lot of Hadoop-native distributed frameworks are now running natively on Kubernetes.” —Chen Qiang, LinkedIn
What’s next?
Moving forward, LinkedIn is looking to expand the effort to run Hadoop on Kubernetes by adding more big data components, such as Spark, Hive, Presto, and Azkaban. The organization is also in the processes of testing long-running Hadoop clusters on Kubernetes in order to replace bare-metal environments.
As for Kube2Hadoop, the LinkedIn team is planning to add a chief init container that will be in charge of fetching delegation tokens from Hadoop Token Service and then distributing the tokens to workers. This has the potential to improve scaling, especially with deep learning jobs involving thousands of containers.
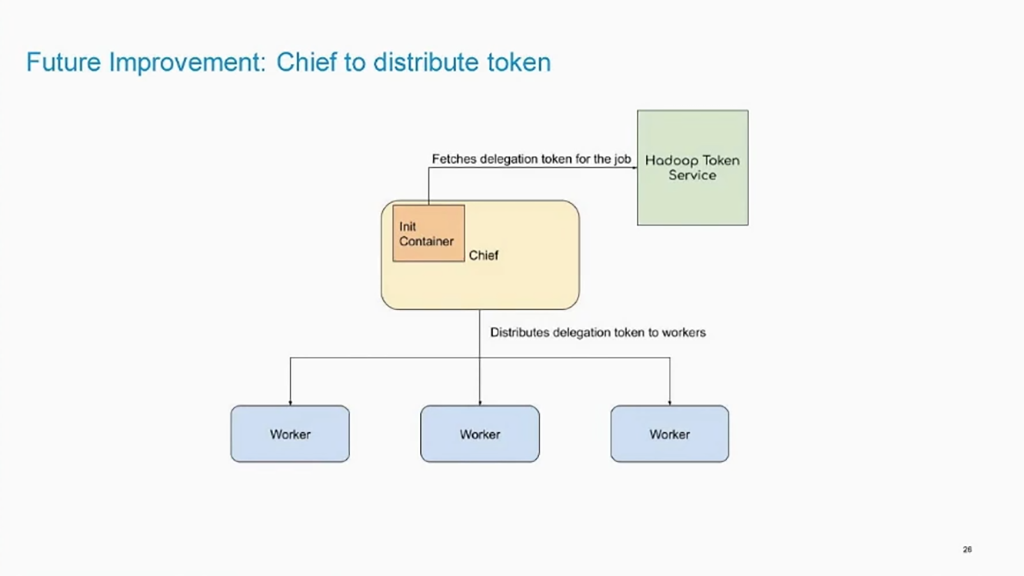 Fetching and distributing tokens through a chief init container (Image credit)
Fetching and distributing tokens through a chief init container (Image credit)By integrating Hadoop and Kubernetes, LinkedIn can better scale its AI projects. With open-source Kube2Hadoop, organizations are able to combine different Hadoop workloads onto a single resource management platform. This way, companies that have separate online and offline infrastructures can easily leverage their online infrastructure during off-peak hours, effectively utilizing idle resources and potentially reducing millions in hardware cost.
Want details? Watch the videos!
Abin Shahab and Cong Gu explain how Kube2Hadoop works.
Chen Qiang provides an overview of lessons and takeaways LinkedIn encountered in running Hadoop on Kubernetes.
Further reading
- GitHub Crafts 10+ Custom Kubernetes Controllers to Refine Provisioning
- Kroger Runs 7,000 App Instances on Pivotal Cloud Foundry and Kubernetes
- Ensuring Security Across Kubernetes Deployments
About the experts
 Cong Gu is Software Engineer at LinkedIn’s Big Data Platform team. He joined LinkedIn in 2017 and helps AI engineers by building infrastructure to improve their productivity. Cong has given technical deep dive talks in company-wide settings, as well as at KubeFlow Summit.
Cong Gu is Software Engineer at LinkedIn’s Big Data Platform team. He joined LinkedIn in 2017 and helps AI engineers by building infrastructure to improve their productivity. Cong has given technical deep dive talks in company-wide settings, as well as at KubeFlow Summit.
 Abin Shahab is Staff Engineer at Linkedin’s Big Data Platform (BDP) team. He joined Linkedin in 2017 and leads the Deep Learning infrastructure team in BDP. Abin is a veteran KubeCon speaker.
Abin Shahab is Staff Engineer at Linkedin’s Big Data Platform (BDP) team. He joined Linkedin in 2017 and leads the Deep Learning infrastructure team in BDP. Abin is a veteran KubeCon speaker.
 Chen Qiang is Staff Site Reliability Engineer at LinkedIn focusing on big data infrastructure. He specializes in continuous integration and continuous delivery for big data. Chen is also an expert in big data infrastructure, such as Hadoop HDFS, YARN, HBase, Hive, and Oozie.
Chen Qiang is Staff Site Reliability Engineer at LinkedIn focusing on big data infrastructure. He specializes in continuous integration and continuous delivery for big data. Chen is also an expert in big data infrastructure, such as Hadoop HDFS, YARN, HBase, Hive, and Oozie.
 Keqiu Hu is Engineering Manager at LinkedIn, where he leads a team that works on big data compute orchestration and deep learning. In addition, Keqiu manages system infrastructure engineers with experience in Apache YARN, Kubernetes, and TensorFlow. He is also involved in the development of TonY and Bluepill.
Keqiu Hu is Engineering Manager at LinkedIn, where he leads a team that works on big data compute orchestration and deep learning. In addition, Keqiu manages system infrastructure engineers with experience in Apache YARN, Kubernetes, and TensorFlow. He is also involved in the development of TonY and Bluepill.




