Optimizing the Performance of Apache Spark Queries

A testing environment
Apache Spark is a popular technology for processing, managing, and analyzing big data. It is a unified analytics engine with built-in modules for SQL, stream processing, machine learning, and graph processing.
In this post, we will explore optimization techniques, which improve query run times for two particular modules of the technology: Spark Core and Spark SQL. In its turn, Spark SQL comprises two components: pure Spark SQL, which will also be under investigation, and DataFrame API.
As a testing architecture, we set up a Spark cluster of a master and three workers using the Spark Standalone mode. The Apache Spark application starts by submitting a JAR file to the master, which then assigns tasks to the workers. The application reads data from the Google Cloud Platform storage.
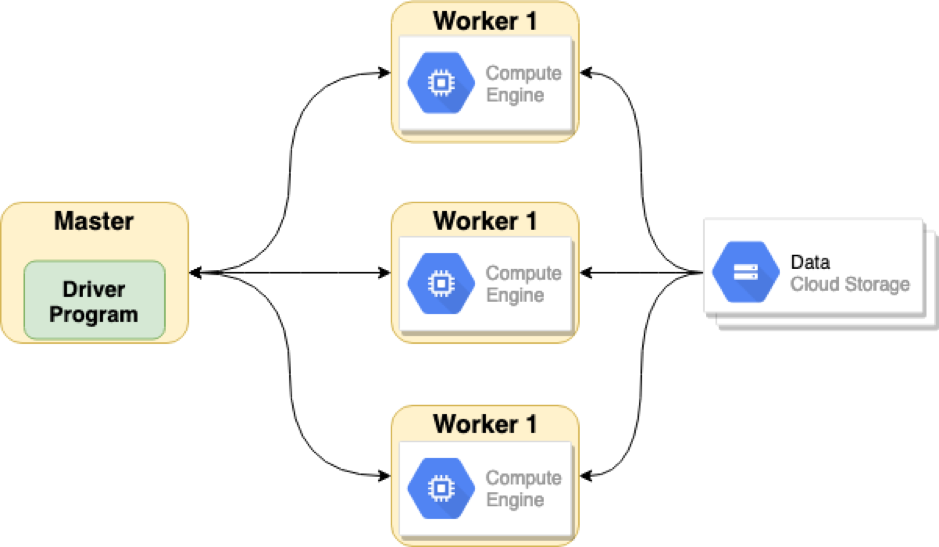 An architecture of the Apache Spark cluster with a master and three workers
An architecture of the Apache Spark cluster with a master and three workersTo measure query run time, the following command was used (see the full source code in this GitHub repo):
1 | <strong>SELECT</strong> u.id, <strong>count</strong>(distinct c.id) <strong>FROM</strong> users <strong>AS</strong> u <strong>INNER JOIN</strong> comments <strong>AS</strong> c <strong>ON</strong> u.id = c.user_id <strong>INNER JOIN</strong> posts <strong>AS</strong> p <strong>ON</strong> p.owner_user_id = u.id <strong>WHERE</strong> u.reputation > 1 <strong>AND</strong> c.post_id = p.id <strong>GROUP BY</strong> u.id <strong>ORDER BY</strong> <strong>count</strong>(<strong>distinct</strong> c.id) <strong>DESC</strong> |
What can be optimized?
Spark Core
Using default settings, Spark Core has the slowest processing time among the three investigated components. This can be optimized through changes to resilient distributed data set (RDD) and serialization.
Since the User RDD is small enough to fit in the memory of each worker, it can be transformed into a broadcast variable. This turns the entire operation into a so called map side join for a large RDD, which doesn’t need to be shuffled this way. The User RDD will then be converted into a typical Map and will be broadcasted on each worker node as a variable.
The Post RDD can be partitioned before joining the User RDD via the partitionBy(new HashPartitionBy(25)) method. This helps to reduce shuffling, as it will be predefined for Post RDD in future transformations and joins.
Some of the RDD’s methods use variables in the code. For example, there’s the filter(user -> user.getReputation() > 1) variable, which should be broadcasted to take a value from a local virtual machine instead of getting it from a driver. Then, the driver stores the broadcasted filter variables on each worker node. In this case, each task stops polling the value of the variable and gets it locally.
Next, Apache Spark uses a Java serializer by default, which has mediocre performance. This can be replaced with the Kyro serializer, once the following properties are set:
spark.serializerequalsorg.apache.spark.serializer.KryoSerializerspark.kryoserializer.buffer.maxequals 128 mebibytesspark.kryoserializer.bufferequals 64 mebibytes
Additionally, the User classes should be registered in registerKryoClasses, otherwise it will not affect the serialization process.
Pure Spark SQL
Before optimization, pure Spark SQL actually has decent performance. Still, there are some slow processes that can be sped up, including:
Shuffle.partitionsBroadcastHashJoin
First, pure Spark SQL has 200 shuffle.partitions by default, meaning there will be 200 completed tasks, where each task processes equal amounts of data. Since Apache Spark spends time executing extra operations for each task, such as serializations, deserializations, etc., decreasing the number of shuffle.partitions to 25 will significantly shorten query run times.
Second, pure Spark SQL uses SortMergeJoin for the JOIN operation by default. Compared to BroadcastHashJoin, SortMergeJoin does not use a lot of RAM, but processing queries takes longer. If the amount of RAM available is enough for storing data, BroadcastHashJoin becomes the optimal choice for faster data processing.
To enable BroadcastHashJoin, the value of autoBroadcastJoinThreshold should be increased to match the size of the filtered data set being queried.
Optimization results
While using Spark Core, developers should be well aware of the Spark working principles. Otherwise, the ignorance of them can lead to inefficient run times and system downtimes. After the implementation of various optimization techniques, the job run time was decreased by 33.3%.
The investigation demonstrated that pure Spark SQL showed the best results out of the three modules before implementing any optimization techniques. By applying basic optimization, the results were improved by 13.3%.
Although technologically similar, DataFrame API can’t boast of the same processing time as pure Spark SQL due to the amount of data aggregated. DataFrame API processes all the data from the tables, which significantly increases job run time. With optimization applied, we improved the running time by 54%, making it similar to pure Spark SQL.
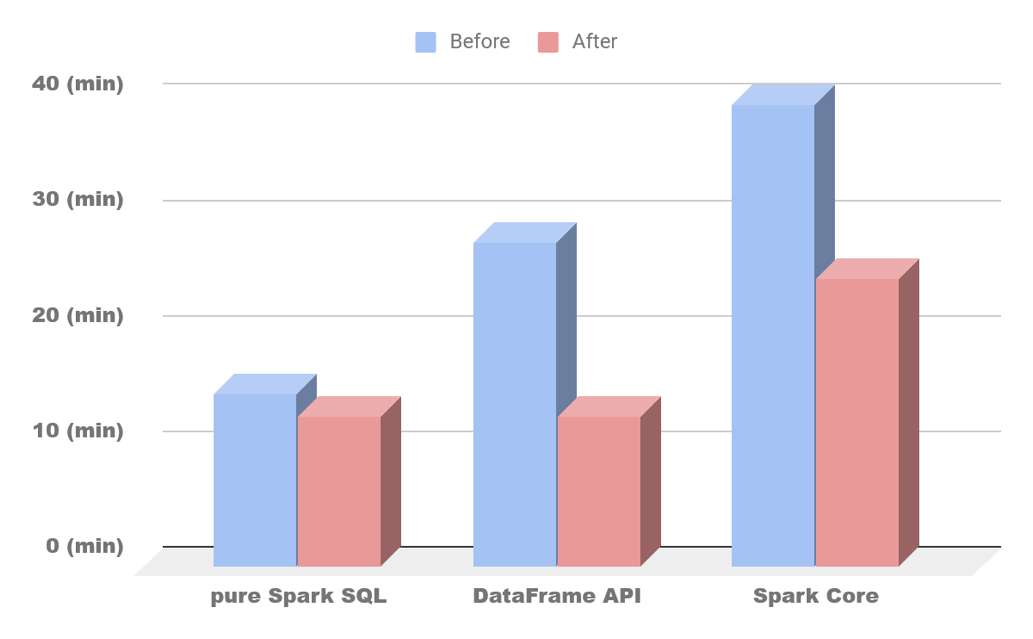 The results of optimizing the three Apache Spark modules
The results of optimizing the three Apache Spark modulesWhile default implementations of Apache Spark can be optimized to work faster, it is important to note that each Apache Spark–based project is unique and requires a customized approach dependent on system requirements and parameters. In this regard, the values suggested above are based on our own tests with Apache Spark.
To learn more about how we optimized our Apache Spark clusters, including DataFrame API, as well as what hardware configuration were used, check out the full research paper.
Further reading
- Multi-Cluster Deployment Options for Apache Kafka: Pros and Cons
- Using Multi-Threading to Build Neural Networks with TensorFlow and Apache Spark
edited by Sophia Turol and Alex Khizhniak.