This 12-page report explores the performance of Apache Spark and two of its modules—Spark Core and Spark SQL—before and after optimization.

or fill out the form
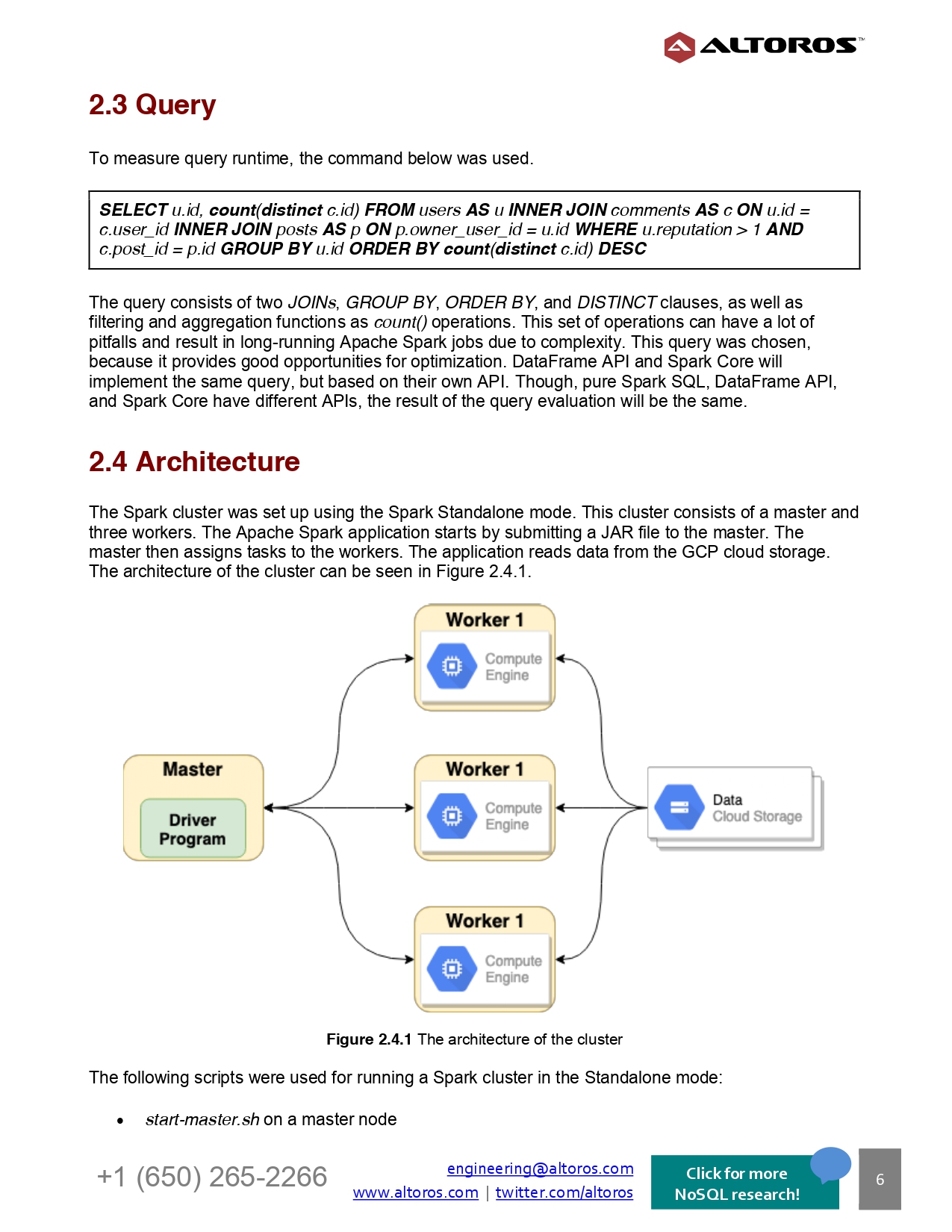
Apache Spark is one of the most popular technologies for processing, managing, and analyzing big data. Different modules of Apache Spark vary in terms of performance. In this regard, knowing different optimization methods to improve query runtime is crucial.
This report focuses on the analysis of two Apache Spark modules—Spark Core and Spark SQL—before and after optimization techniques were applied. Some of the optimization methods include:
Shuffle.partitions and BroadcastHashJoinThe optimization results are supported by four performance diagrams and four descriptive tables.

or fill out the form