
Airbnb Deploys 125,000+ Times per Year with Multicluster Kubernetes
The need for horizontal scaling
Airbnb is one of the largest online marketplaces for lodging. Founded in 2007, the platform currently has more than 5.5 million listings across more than 100,000 cities and 220 countries.
Initially, a small team of engineers at Airbnb ran a Ruby on Rails monolith, which they called Monorail. Later on, the company grew and started having dependency issues with Monorail. “We began to experience tight coupling between the modules as our engineering team grew larger,” noted Jessica Tai, Engineering Manager at Airbnb, during a presentation at QCon 2018. “Modules began to assume too many responsibilities and became highly dependent on one another.”
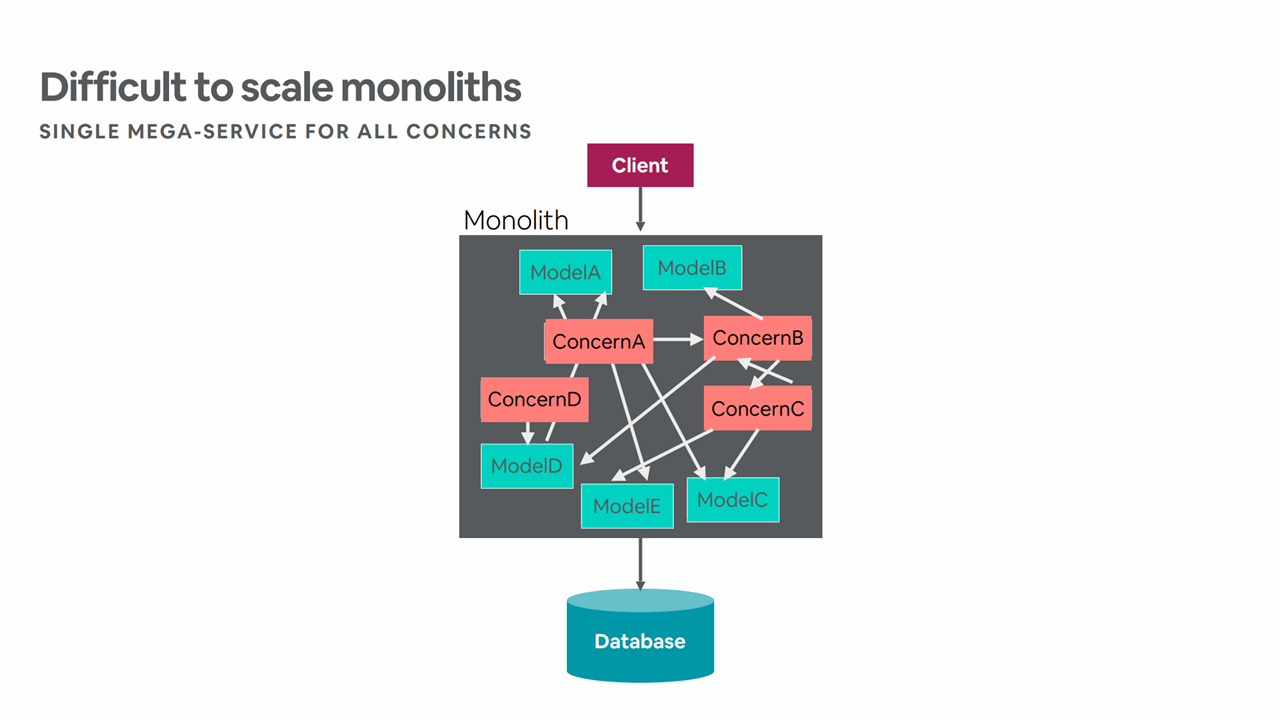 Increasingly complex dependency tracking (Image credit)
Increasingly complex dependency tracking (Image credit)
Jessica Tai
In 2015, Airbnb had over 200 engineers that were adding features to Monorail. With 200 commits deployed to the monolith per day, it would experience an average of 15 hours per week being blocked due to reverts and rollbacks.
“As our engineering team continued to grow, so did the spaghetti entanglement over Monorail code. It became harder to debug, navigate, and deploy Monorail.”
—Jessica Tai, Airbnb
In response, Airbnb started to break apart Monorail and shifted to a service-oriented architecture (SOA) in Amazon Elastic Compute Cloud (EC2). While this change resolved issues with tight coupling, the company now faced a new problem with scaling. “We needed to scale continuous delivery horizontally,” explained Melanie Cebula, Software Engineer at Airbnb, during a presentation in KubeCon NA 2018.
According to Melanie, each service needed its own continuous delivery cycle. This would enable Airbnb to scale development for engineers by simply adding new services. To address scaling, the company began migrating to Kubernetes in 2017.
Migrating Monorail to SOA and microservices

Jens Vanderhaeghe
In its early days, Monorail’s front end was built with Backbone.js as stated by Jens Vanderhaeghe, Senior Software Engineer at Airbnb, during GitHub Universe 2018. In 2015, the front end was migrated to Redux and React, while the back end utilized Java services. The Monorail codebase grew rapidly and, at some point, it accumulated to 220 changes deployed daily, 30,000 SQL database columns, 155,000 pull requests merged in GitHub, and 1,254 unique contributors. Eventually, Monorail was divided in two major services: Hyperloop and Treehouse.
In order to reduce complexity and abstract away configurations, Airbnb’s engineering team relied on YAML templates rather than file inheritance. This also made it easier to migrate legacy services and retrain engineers, according to Melanie Cebula.
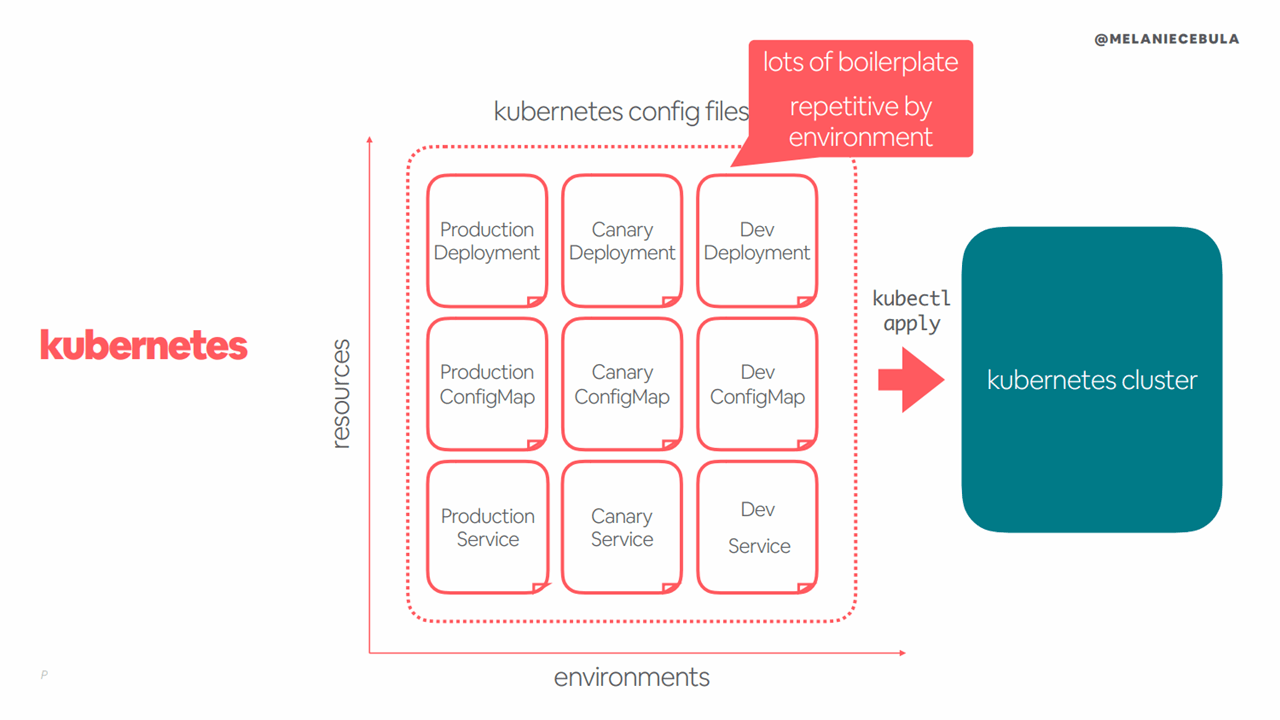 Reducing configuration repetition with YAML templates (Image credit)
Reducing configuration repetition with YAML templates (Image credit)
Melanie Cebula
“We learned the hard way that it was difficult for our engineers to visualize complex hierarchies with files. We prefer templating for that reason.”
—Melanie Cebula, Airbnb
Building on the concept of templates to reduce repetition, engineers at Airbnb began storing configuration files in Git. This way, reviewing, updating, and committing configuration files is streamlined. Additionally, Kubernetes deployment best practices can easily be set as default parameters.
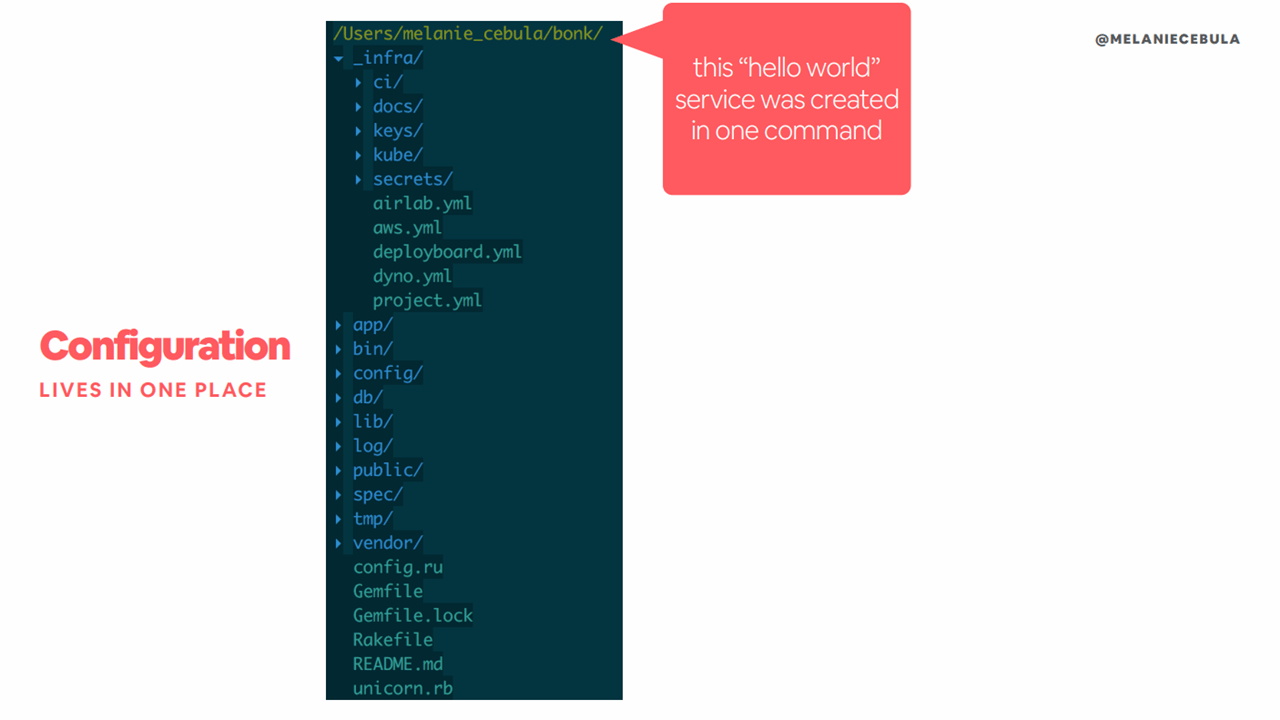 Simpler standardization with Git (Image credit)
Simpler standardization with Git (Image credit)“Once you start storing things in Git, it unlocks so many opportunities. When you start deploying with the same process, you have a standard way of storing and applying configuration.”
—Melanie Cebula, Airbnb
Scaling up with multiclusters
In September 2018, Airbnb’s main production cluster had reached 450 nodes. By December of the same year, this had doubled to 900 nodes. Around this point, concerns around etcd began as explained by Ben Hughes, Software Engineer at Airbnb, during KubeCon North America 2019. “It would be bad if our etcd instances were suddenly getting out of memory,” he added.
Before the end of 2018, etcd in Airbnb’s Kubernetes deployment would get backed up and fall over. This was caused by multiple problems, including low cache hit rate on the API server or a chain of events overwhelming etcd.
Fortunately, when etcd failed, Kubernetes would just stop any deploy and scaling in process. No workloads got taken down. Issues with etcd were resolved by upgrading to the etcd v3 data format.
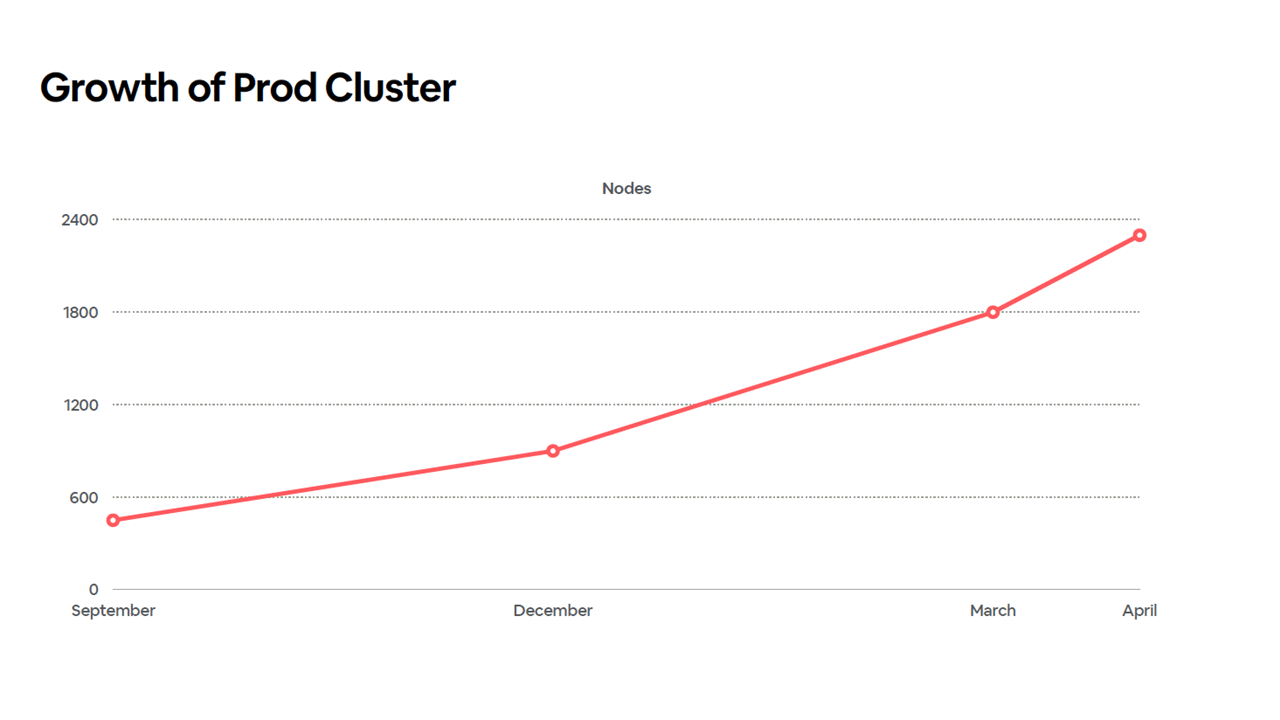 4x growth of the production cluster in less than a year (Image credit)
4x growth of the production cluster in less than a year (Image credit)
Ben Hughes
“Many of the issues were caused by hitting against limits against the etcd v2 data format. Once we upgraded to the etcd v3 data format and did other things like adjusting
quota-backend-bytesup to 8 GB, most of our etcd problems went away.”—Ben Hughes, Airbnb
By March 2019, the company’s production cluster again doubled in size to 1,800 nodes. By April, this increased to around 2,300 nodes. At this point, the engineering team were encountering more issues by increasing the amount of nodes and opted instead to add more clusters.
Airbnb was able to transition to a multicluster environment without much problem. This was largely due to SmartStack, Airbnb’s service mesh, and legacy infrastructure not having any colocation requirements.
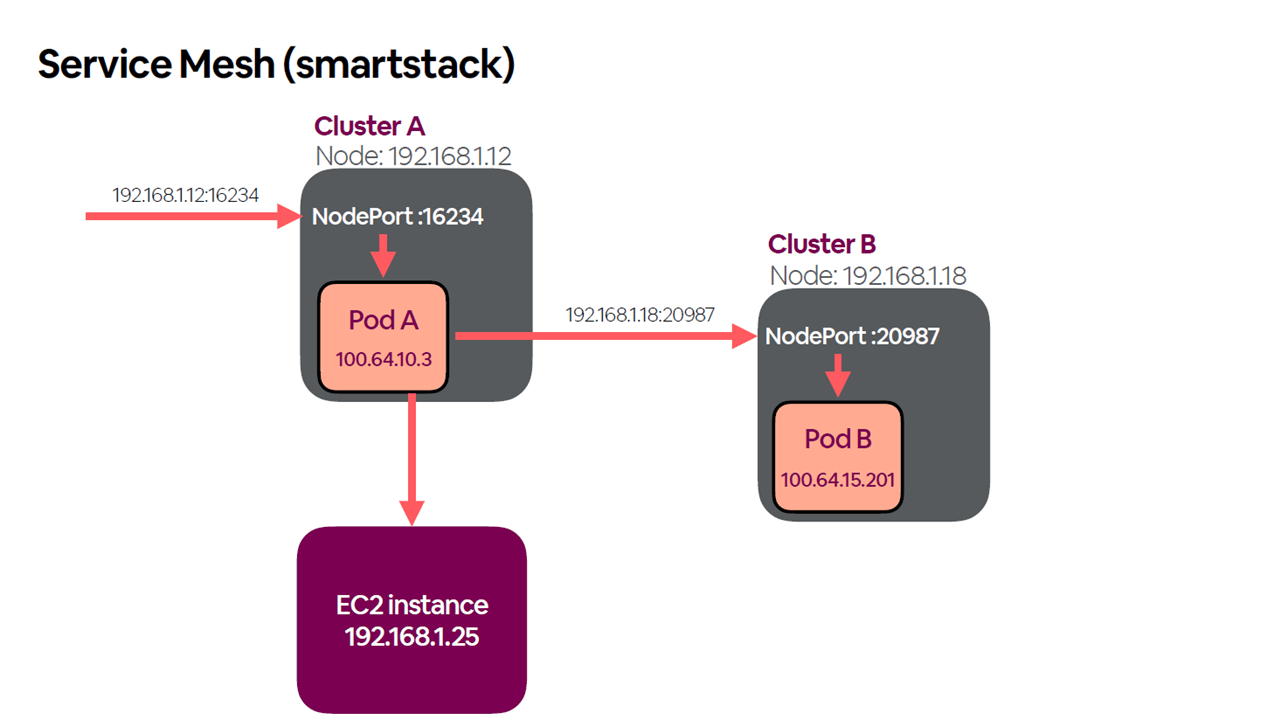 Enabling routability of the pods using the NodePort services (Image credit)
Enabling routability of the pods using the NodePort services (Image credit)“Any of our workloads can run on any of the clusters that we stand up. Our view of clusters is that they are giant pools of compute and memory that we can allocate as we see fit.”
—Ben Hughes, Airbnb
In a multicluster environment, workloads are assigned randomly to a cluster during creation. To ensure that individual clusters can scale without getting close to size limits, engineers at Airbnb only allow new services to be added to clusters with less than 400 nodes.
Keeping multiple clusters consistent
To ensure that clusters perform equally, the Airbnb team created kube-system, an in-house method for deploying clusters. Components for clusters are written as Helm charts that are templated into a single manifest. Applications are then deployed using kube-gen, Airbnb’s internal framework. Under kube-system, deploys take less than 10 minutes.
To better organize multiple clusters, Airbnb additionally introduced the concept of types. These cluster types serve as classes, whereas clusters serve as instances.
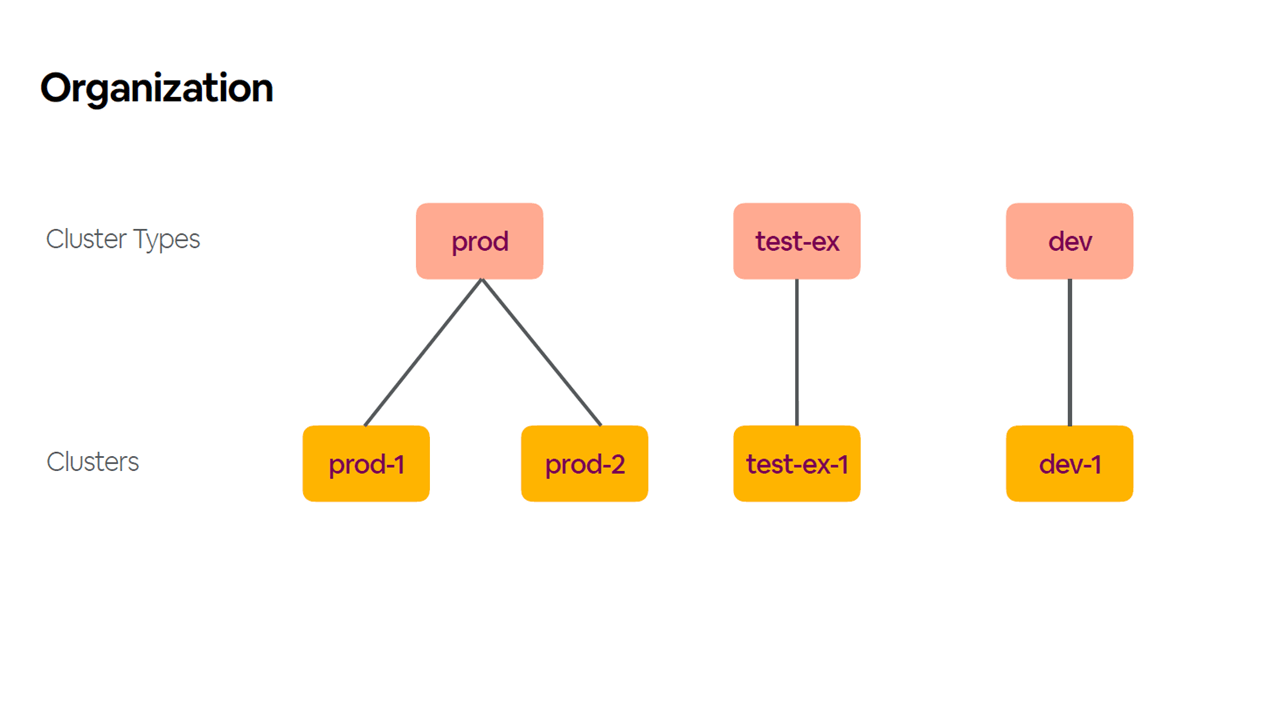 Organizing multiple clusters by types (Image credit)
Organizing multiple clusters by types (Image credit)“Ideally, a user who is deploying a service to one of our clusters should not be able to tell which cluster they are on. We want to avoid people trying to land their services on the good cluster by making all of our clusters good.” —Ben Hughes, Airbnb
Since the migration to Kubernetes, Airbnb has reached no less than 125,000 production deploys per year. Since 2019, more than 50% of the company’s services have been running on over 7,000 nodes across 36 Kubernetes clusters. This includes over 250 critical services. Moreover, the Airbnb team has added over 22 cluster types, such as production, testing, development, special security groups, etc.
Want details? Watch the videos!
In this video, Melanie Cebula discusses Airbnb’s journey from a monolithic architecture to Kubernetes.
In this next video, Ben Hughes explains how Airbnb scaled its services with a multicluster Kubernetes environment.
In the video below, Jens Vanderhaeghe uncovers Airbnb’s journey into microservices.
Related slides
Here are the slides from Jessica Tai‘s presentation.
Further reading
- Installing Kubernetes with Kubespray on AWS
- Maturity of App Deployments on Kubernetes: From Manual to Automated Ops
- Ensuring Security Across Kubernetes Deployments
About the experts

Jessica Tai is Engineering Manager at Airbnb, where she leads the User Platform and Foundation teams. She has presented as a speaker in several conferences, including ScaleConf 2020, QCon London 2019, QCon San Francisco 2018, Women Who Code CONNECT 2018, etc. Jessica also serves as Vice President of Airbnb’s women in technology group, where she mentors for several engineers and interns.

Melanie Cebula is Software Engineer at Airbnb, where she is building a scalable modern architecture on top of cloud-native technologies. Being an an expert in cloud infrastructure, Melanie is also recognized worldwide for explaining radically new ways of thinking about cloud efficiency and usability. She is an international keynote speaker, presenting complex technical topics to a broad range of audiences, both international and domestic.

Jens Vanderhaeghe is Senior Software Engineer at Airbnb. He works on the Continuous Delivery team and is reponsible for building tools that enable fast, safe, and repeatable deployments for all of Airbnb’s engineering organizations. He was involved in the creation of Merge Queue, an in-house queueing system for continuous integration at a large scale. Jens was part of the long term company-wide migration from a monolithic Rails application to a microservices-based architecture built on Kubernetes.

Ben Hughes is Principal Engineer at Amazon. Previously, he was Software Engineer at Airbnb, where he served as the technical lead for the Compute Infrastructure and Kubernetes team. Ben also worked on database scaling, Ruby and Node.js performance, and incident responses at Airbnb.




