
Adobe Migrates 5,500+ Services to Kubernetes

Reaching feature parity on Kubernetes
In 2015, Adobe began Ethos, a project to consolidate infrastructure and software development best practices in the company. The project started with the adoption of Docker containers built on top of Apache Mesos. This led to the first containerized production services of Adobe.
Needing to scale up, Adobe switched from Apache Mesos to the Distributed Cloud Operating System (DC/OS) in late 2016 to early 2017. With DC/OS, Adobe was able to scale up with a multitenant platform. However, to meet with the compliance, scaling, and security requirements of a multitenant platform, Adobe’s engineering team needed to build their own components for crucial features, such as log forwarding, monitoring, autoscaling, container security frameworks, etc.
 Progression of the Ethos project (Image credit)
Progression of the Ethos project (Image credit)In 2018, Adobe started a skunkworks project, which identified Kubernetes reached feature parity with the custom components created by the in-house team. This greenlit a complete migration to Kubernetes. “We reached a point where it wasn’t a question of if, but when are we going to make the jump to Kubernetes?” explained Sean Isom, Engineering Manager at Adobe.

Sean Isom
“We needed to quickly execute on being able to move all of our existing DC/OS services to our new Kubernetes clusters and then end-of-life our DC/OS stack. These are all production services, and we had to execute this move across clusters seamlessly without downtime, so users would not notice an impact to their service.”
—Sean Isom, Adobe
By 2019, Adobe had successfully onboarded new services to Kubernetes. The company then started the process of migrating the rest of its existing services.
Conducting a live migration
To help streamline the migration process, Adobe relied on the Ethos service spec, a YAML file that represents a service’s requirements. The Ethos service spec is not limited to either DC/OS or Kubernetes. It specifies what a service’s environments are, as well as what resources it needs.
 An example of an Ethos service spec (Image credit)
An example of an Ethos service spec (Image credit)“The service spec has become our single source of truth. It informs all the infrastructure we provision. From our perspective, when we migrate or add a new cluster orchestrator, it’s a matter of building a functionally equivalent transformation of the service spec into the new architecture. This level of abstraction allows us to do that.” —Sean Isom, Adobe
The Adobe engineering team prepared a migration tool comprising three steps:
- Configure and deploy. Services are configured to seem like they were initially onboarded to Kubernetes. Services are then deployed to a temporary DNS endpoint to allow health checks to run automatically.
- DNS cutover. Once all health checks are passed, a user can simply flip the service from DC/OS to Kubernetes.
- Mark as good. After the service has been fully tested on Kubernetes, they can be marked as good. This results in the removal of infrastructure used by the service on DC/OS.
The tool was exposed to users, which are developers of Adobe services, through a self-service portal, enabling them to migrate their own services. At any point during migration, a service can rollback in case an error occurs.
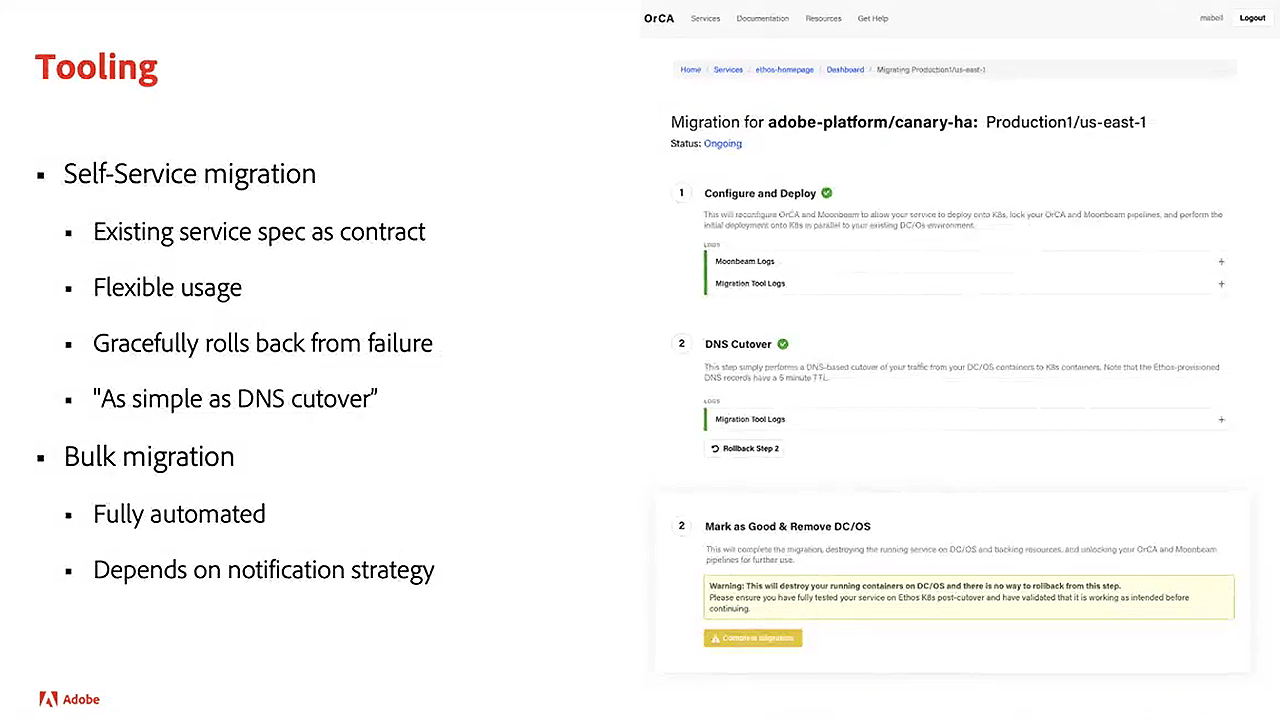 Service migration in three stages (Image credit)
Service migration in three stages (Image credit)With thousands of services and users still on DC/OS, the Adobe engineering team built a bulk migration tool, which automated the entire process. For example, bulk migration can be used to configure and deploy all the services in a cluster. All services that fail are rolled back, while those that succeed proceed to the next step.
During migration, users are notified of the status of their services.
“It’s an important dichotomy to give users the flexibility to run the migration themselves and to roll things back, but also to keep control on our end to be able to perform mass migration on clusters, so we’re not constantly waiting on users to take action.” —Sean Isom, Adobe
In the early days of the Ethos project, the CI/CD system was built separately from the cluster infrastructure. This removed the need to make structural changes to the provisioning system or to the CI/CD system during the migration.
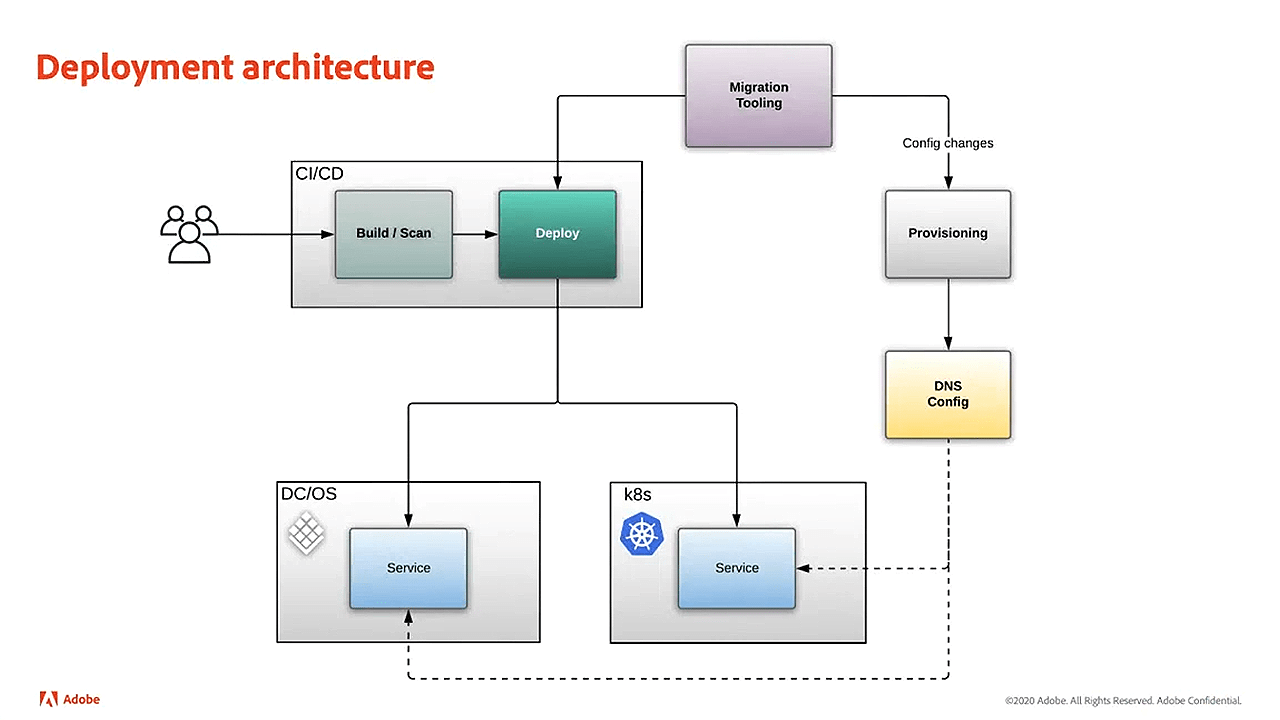 The Ethos deployment pipeline (Image credit)
The Ethos deployment pipeline (Image credit)The Adobe engineering team could simply be able to replace the components that interacted with the cluster and did the deployment. For example, in DC/OS, the Ethos service spec would be translated to a Marathon JSON file or as a YAML file in Kubernetes.
Next, the team created a migration schedule that was flexible, but also realistic. Throughout the migration period, users were given the ability to use the self-service tools. In addition, managed bulk migrations were used on clusters on a per-wave basis going from environment to environment.
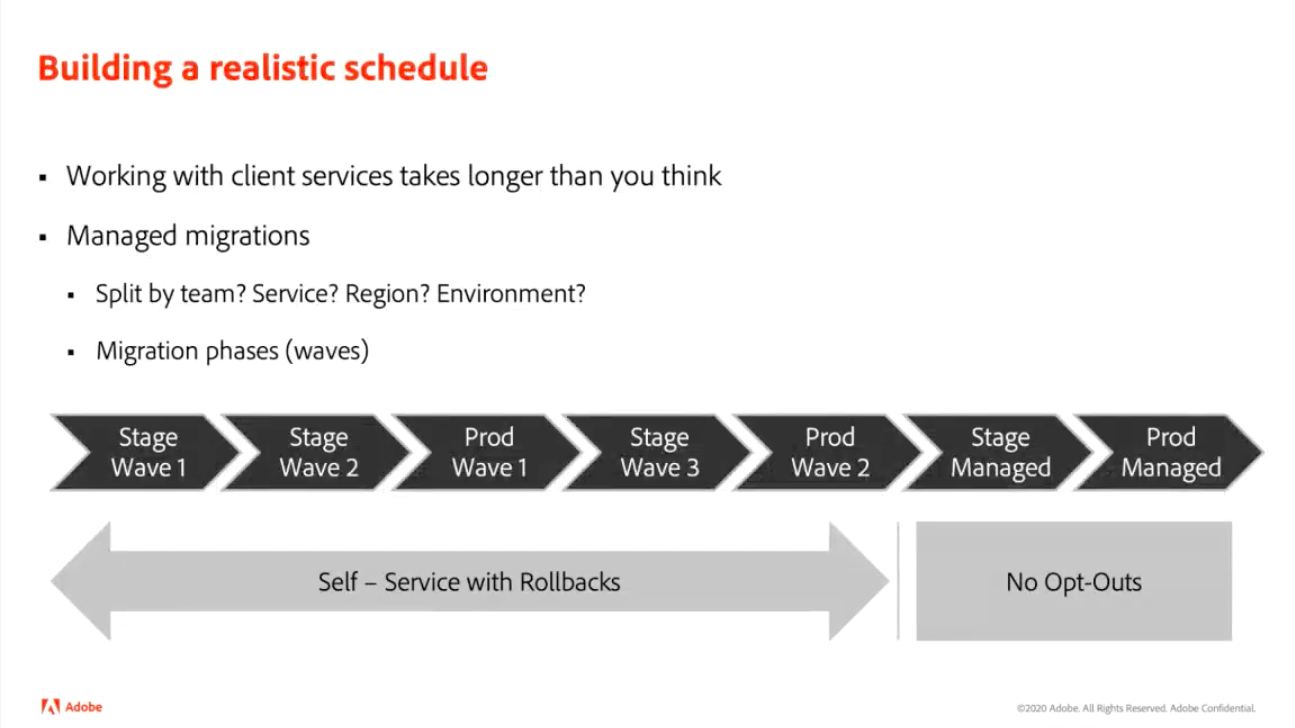 Performing migration in waves (Image credit)
Performing migration in waves (Image credit)“We would bulk migrate a stage cluster once, wait a few weeks, and then retry what did not migrate successfully the first time. This is a pattern that we built over time, where we migrate what’s there. Anything that succeeded automatically moved on. Anything that failed, or a user rolled back, would get left behind. We’d work with the users to iterate on those services, fix what we could, and try again. This was the key strategy that allowed us to get the migration done in less than a year.”
—Sean Isom, Adobe
Creating dedicated infrastructure
One of the products running on Kubernetes is Adobe Experience Manager (AEM), a content management system used by multiple Fortune 100 organizations. “Adobe Experience Manager runs on Microsoft Azure,” noted Carlos Sanchez, Senior Cloud Software Engineer at Adobe. “We have more than 14 clusters right now and are growing,” he said in May 2021 at KubeCon Europe.

Carlos Sanchez
While the move to Kubernetes added multitenancy capabilities for the clusters, it also brought a new challenge.
“The requirement we got from customers is that they wanted to have dedicated infrastructure. This boiled down to dedicated egress IP addresses, private connections, and virtual private networks.” —Carlos Sanchez, Adobe
In order to provide dedicated infrastructure for each customer, the AEM team built a solution using Squid, a caching and forwarding HTTP web proxy.
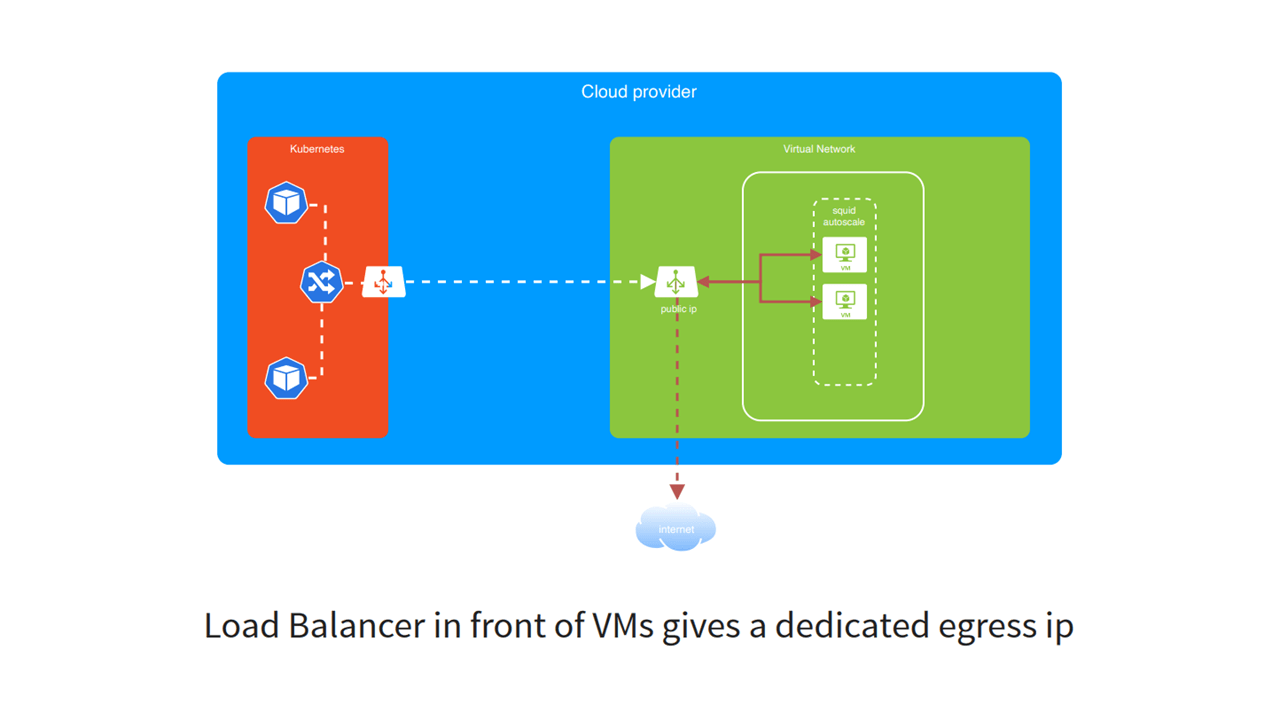 Dedicated infrastructure using Squid (Image credit)
Dedicated infrastructure using Squid (Image credit)Squid provided a couple of upsides in that:
- Java virtual machine configuration is simple and transparent.
- Virtual network peering makes all traffic private.
On the other hand, there were also some downsides:
- Proxy authentication and authorization is not well supported.
- Squid only works on the HTTP and HTTPS protocols.
- HTTP traffic is not encrypted.
- Squid does not support virtual private networks or other private connections.
Due to the limitations with Squid, the AEM team looked for another solution. In the second iteration, the team opted to use Envoy.
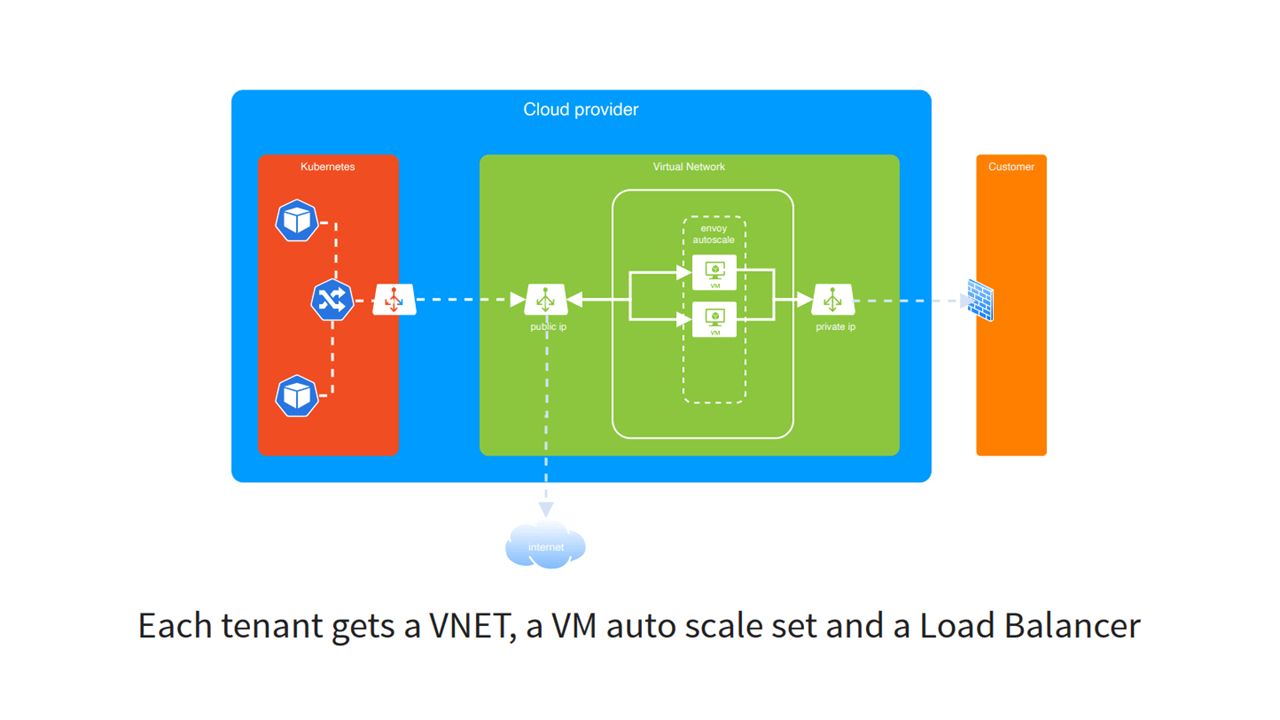 Dedicated infrastructure using Envoy (Image credit)
Dedicated infrastructure using Envoy (Image credit)The iteration with Envoy provided the following advantages:
- Java virtual machine configuration is simple and transparent.
- Any protocol can be supported using different listeners in Envoy sidecars.
- All traffic is encrypted.
- The virtual network provides multiple configuration options on the service level of the cloud provider.
- mTLS prevents unauthorized connections.
Meanwhile, it also had certain disadvantages:
- Virtual private networks and other private connections require a non-overlapping IP range with a customer’s private network.
- Certificate management can be complex.
“We run Envoy on the virtual machines, as well as on pod sidecars in Kubernetes.” —Carlos Sanchez, Adobe
Reducing the impact of failure
To minimize the number of errors during migration, Adobe’s engineering team prepared several precautions. First, the migration tool was feature-flagged. This enabled the team to pause the progress of migration if a problem is detected, providing the opportunity to troubleshoot.
Second, the waves in managed bulk migrations are designed for active pauses. This means that bulk migration can be stopped, while allowing the self-service tool to still function. This way, users who have no issues can complete migration, while the Adobe team can focus on issues such as cluster stability.
Third, rollbacks are expected and even automated. As previously mentioned, during the configure and deploy step of the migration, health checks are performed on the service and, if any of them fail, the service is automatically rolled back.
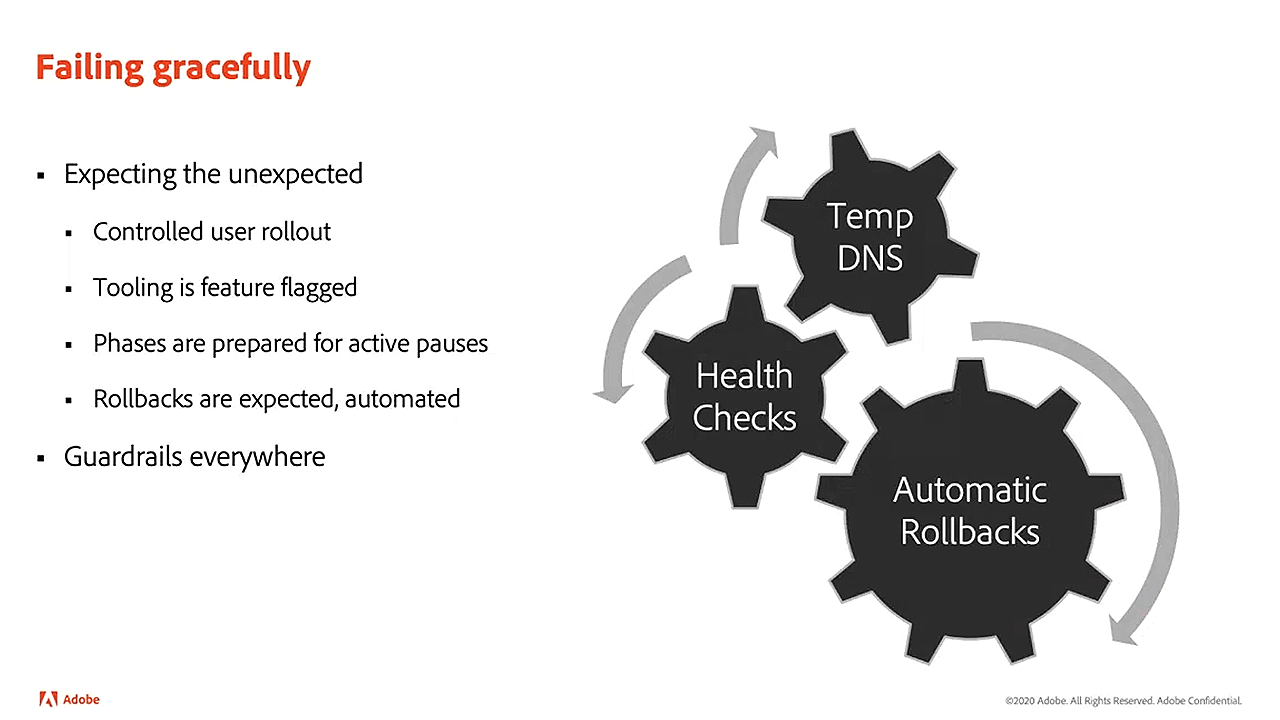 Errors should be expected and prepared for (Image credit)
Errors should be expected and prepared for (Image credit)“We needed to make sure that we were prepared to fail gracefully during migration. Not everything is going to come up successfully on Kubernetes the first time. Sometimes, services will exhibit interesting artifacts that only become known after they’ve been running and serving production traffic on Kubernetes. We had to make sure that every level of our design had flexibility built into it.”
—Sean Isom, Adobe
To conclude, Sean shared some of the lessons learned during migration.
- Abstractions, like the Ethos service spec, were critical in during the process of migration, enabling the company to transition from DC/OS to Kubernetes fairly quickly.
- Always have your features in a consistent state regardless of the platform.
- Empathize with users and keep them engaged during the migration process.
- Be firm on the migration goals, but be flexible on the execution.
“We made sure that users understood why we had to migrate, but also we understood what their requirements were for the platform. It’s important to have that level of mutual empathy for the process.” —Sean Isom, Adobe
With proper tooling, guardrails, as well as a schedule in place, the Adobe engineering team managed to completely migrate all of the existing DC/OS services to Kubernetes in 2020. The entire process lasted nine months, and Adobe was able to migrate over 5,500 services, more than 1,200 of which serve in production. All DC/OS clusters have also been decommissioned.
Want details? Watch the videos!
In the video below, Sean Isom details how Adobe managed to perform a live migration of its services to Kubernetes.
In this next video, Carlos Sanchez discusses how the Adobe Experience Manager team built solutions to provide customers with dedicated infrastructure.
Further reading
- GitHub Crafts 10+ Custom Kubernetes Controllers to Refine Provisioning
- LinkedIn Aims to Deploy Thousands of Hadoop Servers on Kubernetes
- Maturity of App Deployments on Kubernetes: From Manual to Automated Ops
About the experts

Sean Isom is Engineering Manager at Adobe, where he works on the Ethos project, the company’s container compute, and the CI/CD framework. He is responsible for the Kubernetes migration project, live migrating over 5,000 service environments from DC/OS to Adobe’s own Kubernetes implementation. Previously, Sean worked as a senior engineer and manager at several startups and medium-sized businesses, transitioning into cloud engineering after working in computer graphics and with C++.

Carlos Sanchez is Senior Cloud Software Engineer at Adobe, where he specializes in software automation—from build tools to continuous delivery and progress delivery. For more than a decade, Carlos has been a member of the Apache Software Foundation, contributing to numerous open-source projects, such as Maven, ActiveMQ, Jenkins, Puppet, Fog, Commons, etc. During his career, he was also an engineer and a consultant in various technology companies, as well as a project lead at the Eclipse Foundation.



