Automotive Insurance with TensorFlow: Estimating Damage / Repair Costs

Burdens of damage estimation in auto insurance
At TensorFlow meetup in London, Marcel Horstmann and Laurent Decamp of Tractable shared their experience in building a working solution for automotive insurance that will allow for improving the process of damage estimation.
When a vehicle gets damaged in an accident, an insurer has to cover the repair cost. However, the estimation for it is done by a body shop, which may overcharge sometimes. Furthermore, the estimation process is manual and requires human experts and their time to evaluate the damage.
Employing machine learning, it’s possible to train a model that will recognize the damaged car parts, assess damage, make predictions about what kind of repair is needed, and estimate how much it may cost.
To deliver accurate estimation, the model should be capable of predicting what type of maintenance exactly is to follow. As it influences the final cost, it is necessary for the model to distinguish, for instance, whether the damaged car part can be still fixed or has to be replaced.
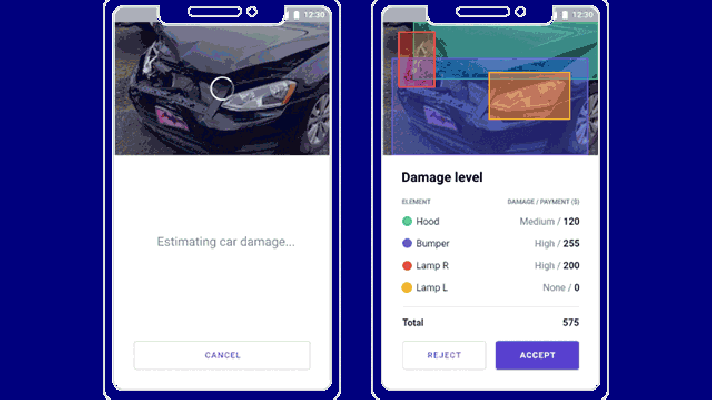
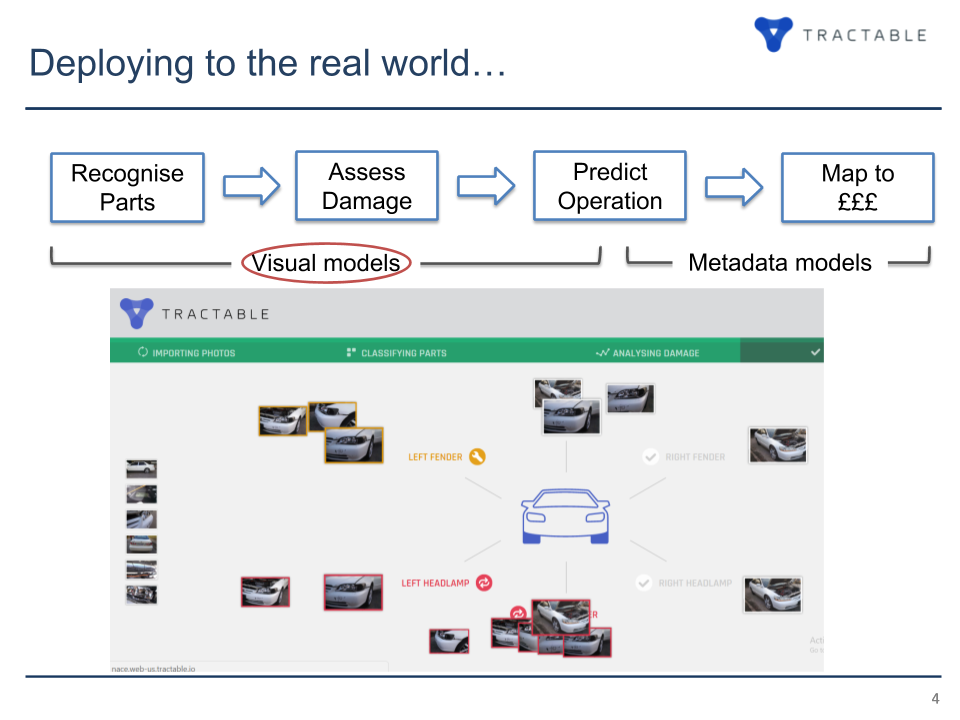 Image credit: Tractable
Image credit: TractableVisual models, as Marcel calls them, are responsible for image recognition and damage assessment. Repair estimate belongs to the domain of metadata models, while prediction uses both the models.
“So, we have to decide if this part is so damaged that we need a new one, and then we have to figure out what the part number is, and how expensive it is.”
—Marcel Horstmann, Tractable
Enabling multi-instance learning
To build a model capable of estimating repair cost, there is a need for data to train this model on. Partnering with auto insurers, Marcel and Laurent got access to an immerse collection of 130+ million images of damaged cars. Furthermore, these images have annotations—highlighting which vehicle part was particularly damaged.
Within a single insurance claim, Marcel and Laurent usually exploit between 15–50 images to train the model. Some of them depict the overall vehicle condition, some illustrate the damage occurred, and some are just irrelevant for the assessment case.
To make it all work, they rely on the following technology stack:
- Amazon S3 to store data
- A custom-built API to download, decompress, and buffer images in parallel
- Keras and TensorFlow to actually train the model
Marcel referred to multi-instance learning that they were trying to enable. By this, he meant that the model is to check a variety of images—taken from different angles—of the same damaged vehicle before making a final prediction. For the purpose, the team also employed the ResNet convolutional neural network and tested a bunch of approaches to pooling.
 Image credit: Tractable
Image credit: TractableOn the way, there were some challenges to address:
- Providing real-time inference
- Using a relatively modest volume of data (1.2 million images submitted by an individual insurer daily, which can be treated as 12.5 images/second throughput per model)
- Ensuring an ability to sustain irregular peaks of traffic
Additional constraints were imposed through training 12 data sets—containing images of 12 car parts—as different models. In addition, the recognition stage and assessment stage required separate treating, so it resulted in 24 models to train.
Overcoming the hurdles
The team decided to deploy each model on a dedicated GPU. This allowed for using large batch size and achieving high throughput (170 images/second per model). However, the cost it took mounted $16,000 per months for 24 models, which Laurent naturally coined as expensive and resource-wasteful.
Looking for better options, the team considered using CPU for inference or collocating multiple models on the same GPU. The first option proved invalid due to scalability issues. Running parallel processes on the same GPU improved the situation a bit, still one needs to reserve additional memory for TensorFlow and Keras apart from the model itself and a batch.
Betting on the latter strategy, engineers were able to put either five models with a batch size of 32 or six models with a batch size of 16 on the same GPU. It resulted in a satisfying throughput, though they had to compromise performance to a certain extent.
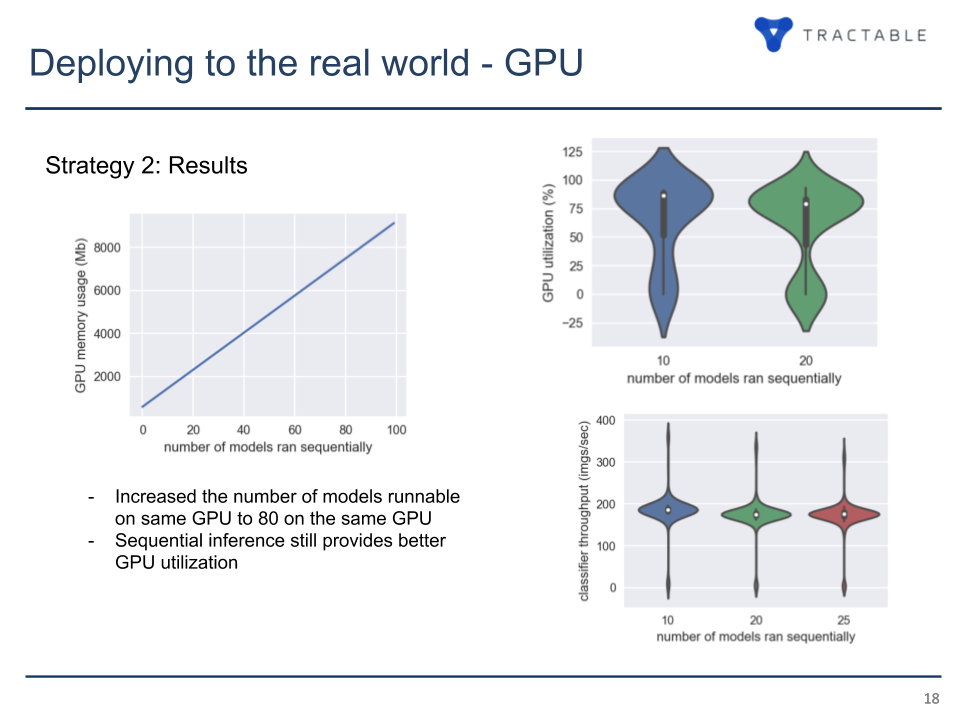 Image credit: Tractable
Image credit: TractableThere is a potential to boost the performance by optimizing the process of image decompression. According to Laurent, it may happen if they take a single Python process, warm up models weights, and then sequentially run the models. This way, he estimates it will be possible to scale up to 80–85 models on a GPU.
In the long run, the team utilized four GPUs to train 24 models. The total cost for the computing resources amounted for $3,300 with around $12,700 saved monthly—in comparison to the initial setup.
As a result of this research, Tractable has developed two products AI Review and AI FNOL Triage. You can also read this article, featuring a demo of the company’s solutions.
Want details? Watch the video!
Related slides
Further reading
- Automotive Blockchain: from Manufacturing to Security to Insurance
- Blockchain for Insurance: Less Fraud, Faster Claims, and New Models
- Using Machine Learning and TensorFlow to Recognize Traffic Signs
About the experts
Marcel Horstmann is Deep Learning Researcher at Tractable with a background in quantum optics. With an MS degree in Physics, he is experienced in applying deep learning to both solar power prediction and energy efficiency.
Laurent Decamp is Deep Learning Engineer at Tractable. Recently, he was engaged in a research project on real-time image-based localization in large-scale outdoor environments. Laurent has got MS in Artificial Intelligence from the University of Edinburgh.