Natural Language Processing Saves Businesses Millions of Dollars

Many discrete approaches within AI

Michael Frederikse
“Artificial intelligence is a process from data to action,” as Michael Frederikse, a Software Technologist at Pattern, Inc., put it during his session at the recent TensorFlow meetup in Boston. Under this process, the following metamorphoses take place:
- transformation of data into features to drive valuable insights (e.g., price-to-earnings ratios in the financial services world)
- analysis of these insights to make predictions (e.g., analyzing satellite imagery to evaluate property risks)
- using predictions to take action (e.g., for decision making in foreign exchange market)
Michael noted that natural language processing is just one approach available within the larger world of artificial intelligence, as well as deep and machine learning. He also paid attention to the intersection of these notions.
 The intersection of NLP, machine/deep learning, and artificial intelligence (Image credit)
The intersection of NLP, machine/deep learning, and artificial intelligence (Image credit)Each of these fields involves discrete approaches to solving real-world problems. So, Michael shared some technical methods and showcased possible implementations that may help to optimize business and/or reporting practices.
Methods behind natural language processing
There is a bunch of tasks natural language processing is applied to:
- Stemming, which is a process of reducing a word to its stem from inflected or derived forms (e.g., faster –> fast).
- Lemmatization is quite similar to stemming, as its purpose is to determine a word’s lemma. However, lemmatization treats a group of the inflected word forms as a single item (e.g., is, are –> be).
- Term frequency estimates the relevance of a word within a single text or a collection of texts. The method can be used as a weighting factor in searches of information retrieval, text mining, or user modeling. The subtype of the approach is inverse document frequency. It is applied to diminish the weight of terms that occur frequently in a document set and increase the weight of more rare terms. For example, let’s take “a pale blue dot.” When assessing the relevance of all the words in a phrase under raw term frequency, each word is treated as of equal importance. However, “a” is a frequently used word in comparison to “pale,” or “blue,” or “dot.” To enable better precision in determining the word weight, inverse document frequency is used.
- Sentiment analysis is common instrument to identify whether statements are positive, negative or neutral. Sentiments can also be treated as industry-specific, source-specific, and formality-specific. What is important, with this approach one can evaluate the complexity of a statement. For example, you can judge whether someone uses slang or the language of a scholar, which can provide additional value to your findings. One can also track similarities on a contextual or structural level. And, finally, sentiment analysis can be applied to time-series data, which may be critical to monitoring industrial processes or tracking corporate business metrics.
“You can also do it (sentiment analysis) by industry. For example, most of my time is spent in finance. So, I don’t care if something is positive. It may be one endless positive, positive, positive review. But if it is always positive, and they give a positive review, that doesn’t mean anything in terms of my stock.” —Michael Frederikse, Pattern, Inc.
To put the above-mentioned capabilities of natural language processing into effect, you build a model and may utilize the means of machine or deep learning to train it. Usually, neural networks are the driving force behind these means. So, you can enjoy the existing variety of them and pick the one that better fits your needs.
 A zoo of neural networks (Image credit)
A zoo of neural networks (Image credit)The preferred methods of Michael, which work for him in 99% of cases, are support vector machines and stochastic gradient descent.
Saving $4M for a logistics company
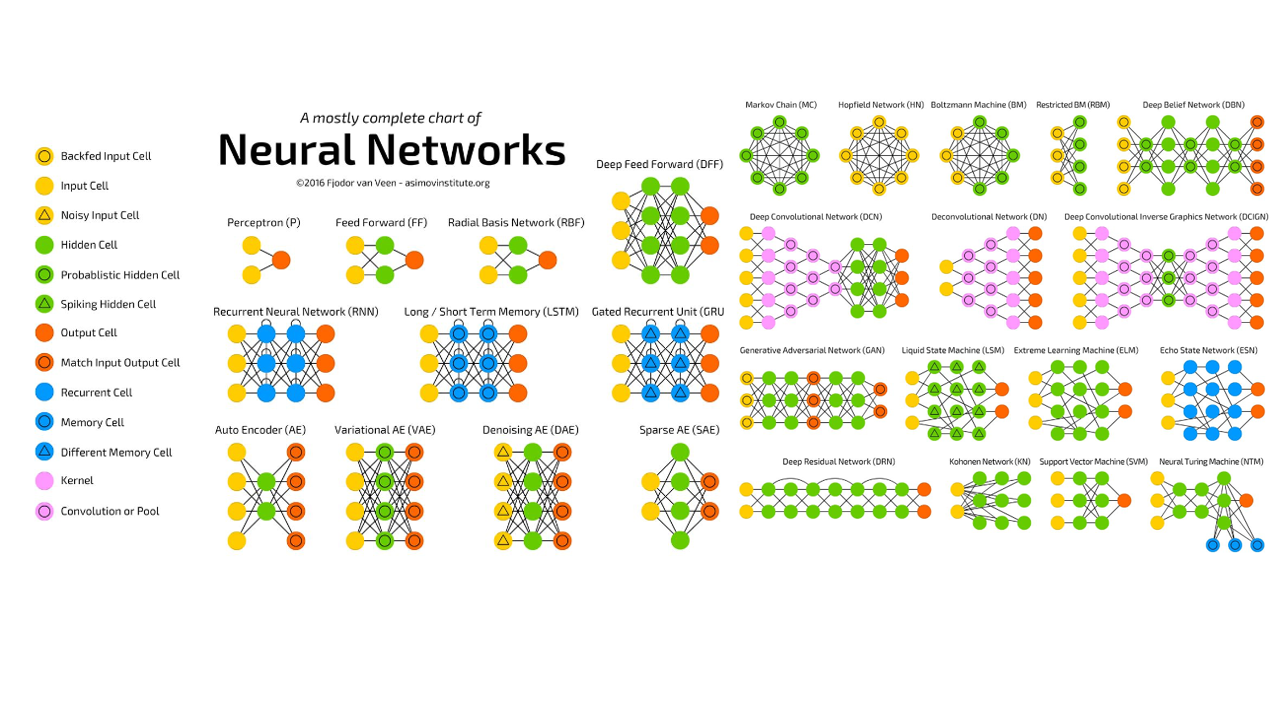
The port of Rotterdam, the Netherlands, is the largest shipping port in Europe with a cargo turnover of nearly 441.5 million tonnes per year. Michael shared a case of a logistics company operating at the port. The company manually handles thousands of PDFs—invoices, orders, manifests, etc. The reason for manual processing is that documentation differs greatly from a customer to a customer. So, it takes time and human inspection to identify what is supposed to be a product or a destination, for example. Naturally, the company sought to gain more efficiency and automate the process.
 An example of a PDF order (Image credit)
An example of a PDF order (Image credit)Using Python libraries, natural language processing, and stochastic gradient descent, Michael and his team were able to do the following:
- parse and clean PDFs
- determine a document type (an invoice, an order, a manifest, etc.)
- extract product-related information (quantity, price, weight, destination, etc.)
As a result, the team was able to achieve 97% of precision across eight categories of data classified. In its turn, this allowed for reducing time spent on document processing by 98%, as well as reducing shipping errors by 6%. For the company, it means around 4 million dollars saved annually.
For the project, such Python libraries as PDFMiner, NumPY, pandas, and scikit-learn were used.
Processing survey results reduced by 99.7%
![]()
Every year, each of the 90 offices operating under the Boston Consulting Group in 50 countries participates in a financial and social survey. Responses are used to forecast growth for the next year, as well as to enable smart decision making and identify what resources should be allocated to which office and why.
Cataloged by office, region, gender (if provided), and level of experience, responses are highly standardized for the executives. Regarding the amount of data generated under the survey, the company wanted to automate its processing.
One of the challenges was to flag each and every entry of names and inappropriate language in comments by employees submitted in a free format.
“We had to flag inappropriate language and names and could not miss a single one. There was no middle ground. The natural language processing algorithm must have 100% recall.” —Michael Frederikse, Pattern, Inc.
To achieve the goal, the team did the following:
- applied linear regression and random forest algorithms to financial data
- built a dictionary of all terms and a directory of all names extracted
- utilized stemming and lemmatization means against unstructured text responses by employees
In addition to pandas and NumPY libraries already used in the case above, technology stack included spaCy and NLTK.
Using historical data of 20 years, the team managed to find 100% of every stem that had to be flagged. The net result was an astonishing 99.7% reduction in processing time, requiring one person for two hours compared to four people for a month in the past that now looked through 200 texts instead of 30,000.
Document review: from 360,000 hours to seconds
JPMorgan Chase developed the COIN system (deciphered as “Contract Intelligence”), which reviews legal documents in seconds instead of 360,000 hours spent by lawyers and loan officers yearly. Furthermore, the software has helped to reduce loan-servicing mistakes in interpreting 12,000 new contracts annually.
“People always talk about this stuff as displacement. I talk about it as freeing people to work on higher-value things, which is why it’s such a terrific opportunity for the firm.” —Dana Deasy, Chief Information Officer, JPMorgan Chase
Aggregating and mapping data
The term knowledge graph isn’t well defined, though it is frequently used in tight association with semantic web technologies, linked data, large-scale data analytics, and cloud computing. This research paper explores the topic and exemplifies some of the definitions by different scholars. One of the simplest explanations defines a knowledge graph as a comprehensive network of entities, their semantic types, properties, and relationships between these entities.
If we take some notion, for instance, Danaë by Klimt, we can build a knowledge graph for it by retrieving as much information as possible about the painting from available sources. This information includes all kind of things from the date of creation to a canvas size.
The term was heavily populated by Google as the company launched its knowledge base under the same name (Knowledge Graph) in 2012. It was delivered to enhance the search engine’s results with information gathered from a variety of sources. The information is presented to users in a box to the right of search results.
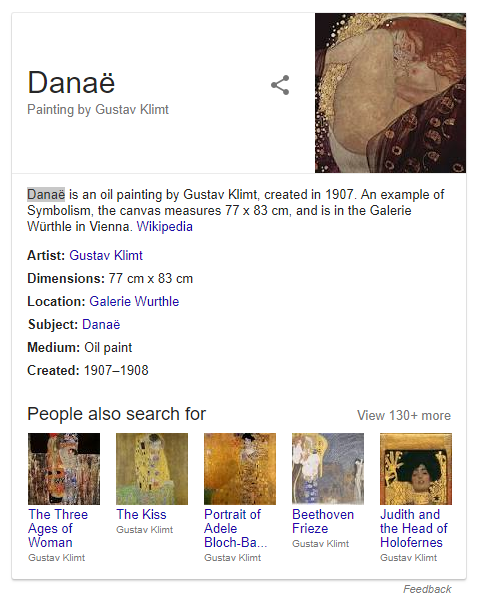 An example of a knowledge box
An example of a knowledge boxSuch mapping of human knowledge can be extrapolated to multiple industries, for example, to finance in order to enable relevance scoring. Michael exemplified a scenario of a news article coming out and the need to create a report about some company. There is a potential in using a knowledge graph to find out whether an article can be relevant to gain insights for a stock.
As artificial intelligence on the whole and its subfields, such as natural language processing and knowledge mapping, evolve, there emerge more and more scenarios. Some of them include:
- Natural language generation for text summarizaion
- Chatbots with dynamic memory banks
- Intellectual property mapping to speed up the patent process
- Automation of legal paperwork
No doubt, the world of artificial intelligence will surely trigger new success stories.
Want details? Watch the video!
Related slides
Further reading
- Approaches and Models for Applying Natural Language Processing
- Natural Language Processing and TensorFlow Implementation Across Industries
- How TensorFlow Can Help to Perform Natural Language Processing Tasks
- Things That Matter When Building a Natural Language Chatbot
About the expert