Approaches and Models for Applying Natural Language Processing

Employ science to predict wisely
A while ago, the Huffington Post made a curious observation that whenever an Oscar-winning Anne Hathaway hits the headlines, the stock price for Berkshire Hathaway (BRK-A) goes up. Prior to Academy Awards 2018, the company’s share gained 2.02%, which amounted to already 2.94% over the weekend after the ceremony. And this is not a one-off, as the same pattern can be tracked down to the opening of “Love and Other Drugs” in 2010, when BRK-A went 1.62% up, or the opening of “Bride Wars” in 2009 with BRK-A rising by 2.61%.
This may well be an indication of stock market analysts using, let’s say, Twitter sentiment analysis to predict market behavior. So, this is a good example of applying natural language processing to real-world needs at large and to the trading industry in particular.
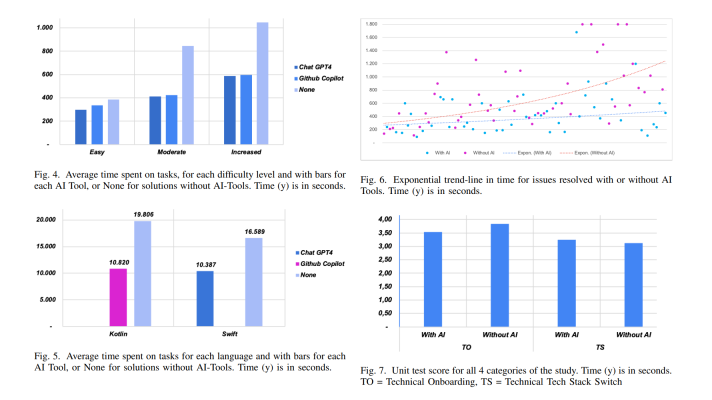
 A sample visualization of sentiment analysis (Image credit)
A sample visualization of sentiment analysis (Image credit)At the recent TensorFlow meetup in New York, Vishal Anand, a researcher from Columbia University, explored what means of natural language processing are applicable to drive value from market data, make further predictions, and deliver insightful business reports to customers.
Traditional approaches
There is a variety of natural language processing models to achieve the above-mentioned goals. Traditional approaches to treating data include:
- Tokenization or sentence splitting, which involves breaking text into a sequence of tokens, roughly corresponding to words.
- Part-of-speech tagging means identifying words as a part of speech they belong to based on both its definition and context.
- Chunking or the Hierarchy of Ideas is based on grouping bits of information in order to come to a deductive / inductive conclusion.
- Named-entity recognition is locating and classifying named entities within text into such pre-defined categories as the names of organization or places.
- Coreference resolution involves identifying all the expressions that refer to the very same entity in a text. This can be further used in natural language understanding to perform document summarization, question answering, or information extraction.
- Semantic role labeling is assigning roles to the constituents or phrases in sentences.
Adaptive models in real-life implementations
One may also employ a bunch of adaptive or self-learning models that help to improve predictions on ever-changing data.
For example, long short-term memory networks (LSTMs) are a good choice to classify, process, and predict time-series data based on time lags of unknown size and duration between important events. This way, real-life applications of LSTMs goes far beyond text recognition or composing music, but enabling predictive analytics in finance, as well.
Coupled with the attention mechanism, which helps to identify and focus on the relevant bits of data, LSTMs can achieve better precision, however it comes with additional complexity of computations.
 LSTMs with the attention mechanism (Image credit)
LSTMs with the attention mechanism (Image credit)Generative adversarial networks (GANs) belong to the world of unsupervised machine learning and comprise two neural networks, one of which generates candidates and the other evaluates them. These networks are widely used to generate content of different kind, produce samples of images to visualize interior/industrial design, model patterns of motion in a video, reconstruct 3D models of objects from images, etc. GANs are also fit for making recommendations based on the input.
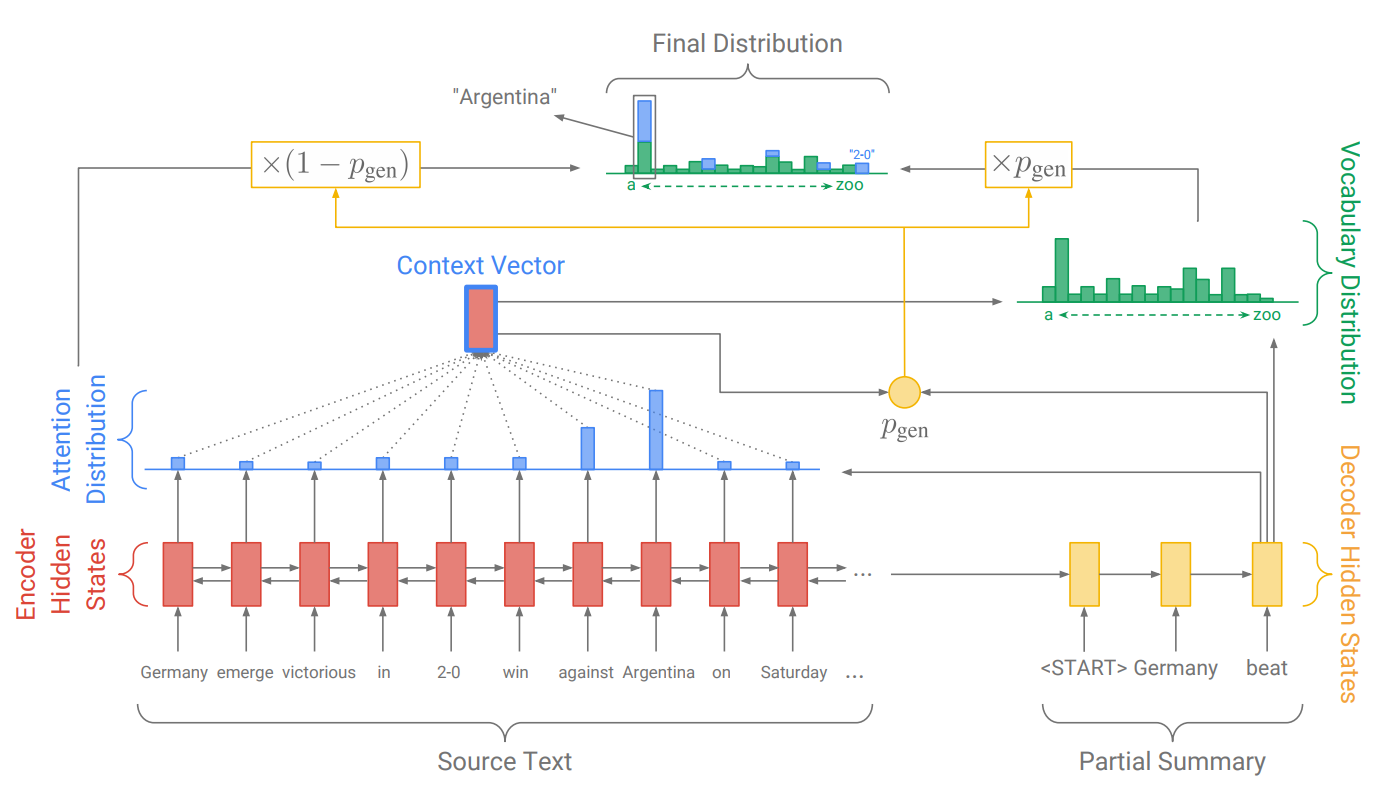
 A sample architecture of a generative adversarial network (Image credit)
A sample architecture of a generative adversarial network (Image credit)Surely, there are many more other neural networks trained to perform natural language processing tasks in a text, audio, or video to drive meaningful insights and make predictions. When paired with TensorFlow, the variety of implementations across industries is almost unbelievable.
You can also check out Vishal’s slides from the meetup.
Want details? Watch the video!
Further reading
- Natural Language Processing and TensorFlow Implementation Across Industries
- TensorFlow for Foreign Exchange Market: Analyzing Time-Series Data
- TensorFlow in Finance: Discussing Predictive Analytics and Budget Planning
About the expert

Vishal Anand is an inventor and an experienced data scientist, specializing in machine learning at Columbia University. After obtaining a bachelor degree in computer science from the Indian Institute of Technology Guwahati, he joined Visa Inc. where Vishal dealt with data-driven risk aspects of financial transactions. He was also awarded a travel grant and sponsorship from Visa for a big data program at Stanford. Vishal has two patent filings in the United States Patent and Trademark Office (USPTO) on machine learning approaches in payment transactions algorithms and a trade-secret with Visa Inc.