Using TensorFlow to Compose Music Like the One of Bach or The Beatles

TensorFlow Dev Summit 2017 brought together deep / machine learning enthusiasts to share their experience and breakthroughs. At the session delivered by Douglas Eck of the Google Brain team, the attendees learned how TensorFlow-based Magenta project can facilitate music generation and why output evaluation is critical.
Capturing reaction and almost Bach composing
Douglas Eck of Google contemplated whether machine learning can be applied to generate “compelling media” such as music, images / video, or jokes, for instance. In their efforts to build an ecosystem for creative coders and artists, the Google Brain team has launched Magenta—a research project aiming at delivering algorithms that learn how to generate art and music.

With TensorFlow underlying the initiative, open-source Magenta is being developed to:
- capture such reaction effects as attention and surprise in a machine learning model
- train models to generate a story
- evaluate the output of generative models
The capability to get feedback and evaluate the results achieved is critical. Though one may compare a model output to train data by measuring the likelihood, it will hardly work out for music or storytelling. There is no difficulty in generating outputs close in terms of likelihood. However, generating outputs close/different in terms of appeal is anything but easy.
“We train a model that can generate tens of thousands or hundreds of thousands songs that sound just like The Beatles or whatever. It’s not just interesting to think of pushing that button, right? You just keep generating more and more material, and it becomes overwhelming. I think more interesting is making a feedback loop, where Magenta is used by musicians and artists in some interactive way. So, the stuff generated is evaluated by people.” —Douglas Eck, Google
In the attempt to train a model to compose music, the Magenta team wondered if the same approach as for image inpainting can be utilized. Thus, they took multi-voice samples and removed one voice line.

“You can remove either a part of a score as a chunk or, more interestingly, you can remove a voice at a time. So, remove one voice and other three voices are providing context.”
—Douglas Eck, Google
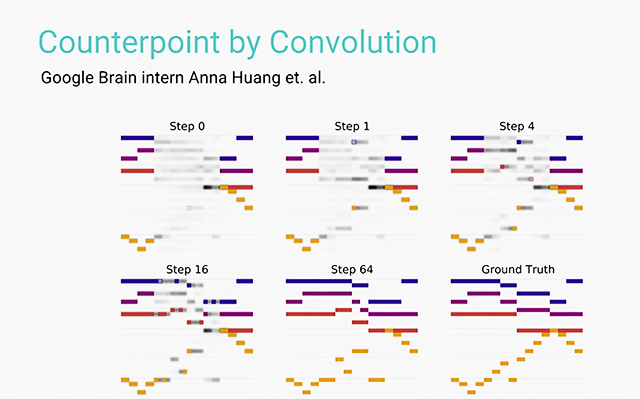
With Gibbs sampling, the team then filled in the missing voice bits, removed another voice lines from the original data, and sampled in again, repeating the process.
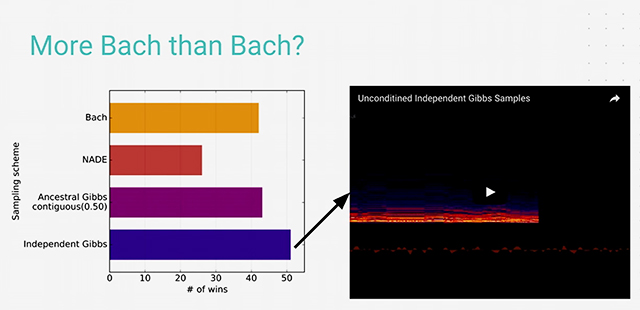
Douglas noted that when the team asked some people to blindly listen to the original samples by Bach and Gibbs-generated, they would prefer the latter.
Another capability offered by the project is enabling image style transfer, which works out of the box with a Docker image. Furthermore, the tool allows for styling images in real time and on mobile devices. You can check out this model by its GitHub repo, as well as Magenta’s GitHub.
Want details? Watch the video!
Further reading
- Analyzing Text and Generating Content with Neural Networks and TensorFlow
- Building Recommenders with Multilayer Perceptron Using TensorFlow
About the expert
Douglas Eck is a Research Scientist at Google, working in the areas of music and machine learning. Currently, he is leading the Magenta project, a Google Brain effort to generate music, video, images, and text using deep learning and reinforcement learning. Douglas has led the search, recommendations, and discovery team for Play Music from the product’s inception to its launch as a subscription service. Before joining Google in 2010, he was an Associate Professor in Computer Science at University of Montreal (MILA lab), where he worked on rhythm and meter perception, machine learning models of music performance, and automatic annotation of large audio data sets.