Multimodal Sentiment Analysis with TensorFlow

Beyond conventional sentiment analysis
Sentiment analysis is a widespread approach to gaining valuable insights based on mostly textual data. The approach has become one of the essential ingredients while developing recommendation engines and chatbots, analyzing customer feedback, etc. Sentiment analysis is also used to enable predictive analytics and estimate budgets in finance, for instance.
While textual sentiment analysis is heavily populated and actively researched, sentiment analysis based on visual or audio data gets far less attention. As it might be fundamentally different from simply classifying images, visual sentiment analysis also imposes certain difficulties like:
- a high level of abstraction required to grasp the message behind an image
- implicit knowledge of culture involved
- human subjectivity implying that two individuals may use the same image to express different emotions

Anthony Hu
With the proliferation of social media, traditional text-based sentiment analysis adopted more complex models to aggregate data in its diversity of forms—text, still images, audio, videos, GIFs, etc. At the recent TensorFlow meetup in London, Anthony Hu of Spotify introduced the audience to a novel approach of multimodal sentiment analysis. With deep neural networks combining visual analysis and natural language processing, the goal behind this approach is to infer the latent emotional state of a user.
What is a multimodal sentiment analysis?
Apart from textual data, multimodal sentiment analysis inspects other modalities, specifically audio and visual data. So, the method can be bimodal or trimodal featuring different combinations of either two or three modalities—text, audio, and video—respectively.
As with the traditional sentiment analysis, one of the most basic tasks in multimodal sentiment analysis is classification of different sentiments into such categories as positive, negative, or neutral. However, various combinations of text, audio, and visual features are analyzed under the multimodal approach. For this reason, there exist three fusion techniques that help to execute analysis: feature-level, decision-level, and hybrid fusion.
Feature-level fusion, aka early fusion, aggregates all the available features from each modality and puts them together into a single feature vector, which is then fed into a classification algorithm. Though, one may experience certain difficulties with integrating heterogeneous features under this technique.
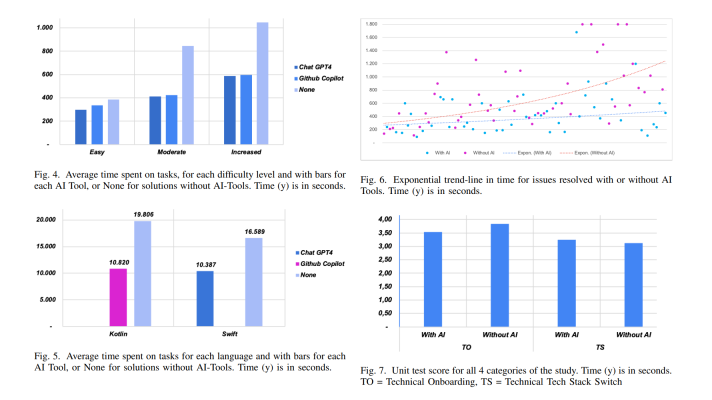
 A co-memory network with memory hops for multimodal sentiment analysis (Image credit)
A co-memory network with memory hops for multimodal sentiment analysis (Image credit)Decision-level fusion, aka late fusion, treats data from each modality independently into its own classification algorithm. The final classification results are acquired through fusing each result into a single decision vector. Unlike the feature-level fusion, the decision-level one doesn’t involve the integration of heterogeneous data. This way, each of the modalities can use the most favourable classification algorithm.
Naturally, hybrid fusion represents a combination of feature-level and decision-level techniques. Usually, it’s a two-step procedure with the feature-level fusion initially performed between two modalities and the decision-level one applied as a second step to fuse the initial results with the remaining modality.
In practice, a multimodal approach can be exhausted in the development of virtual assistants, analysis of YouTube video reviews, emotion recognition, etc. In the latter case, multimodal sentiment analysis might be of a great help to healthcare when detecting the symptoms of anxiety, stress, or depression.
Multimodal data set
In his research on applying multimodal approach, Anthony and his fellow team members built a data set based on Tumblr—a microblogging service where users post multimedia
content usually accompanied by images, text, and tags. These tags can be viewed as a an emotional self-report of a user. This is essential to the research, as its goal was to predict an emotional state of a user rather than sentiment polarity.
Using the Tumblr API, the team searched for emotions through each tagged post from 2011 to 2017. By filtering out non-English blog posts, the team has come up with a total of approximately 250,000 articles. As a result, the data set comprised 15 different emotions form the PANAS-X scale and the Plutchik’s wheel of emotions.
To deal with the visual component of a data set, transfer learning, and the was Inception neural network in particular, was applied. With an architecture comprising 22 layers, the Inception neural network is a common choice as it’s one of the most advanced and precise neural networks.
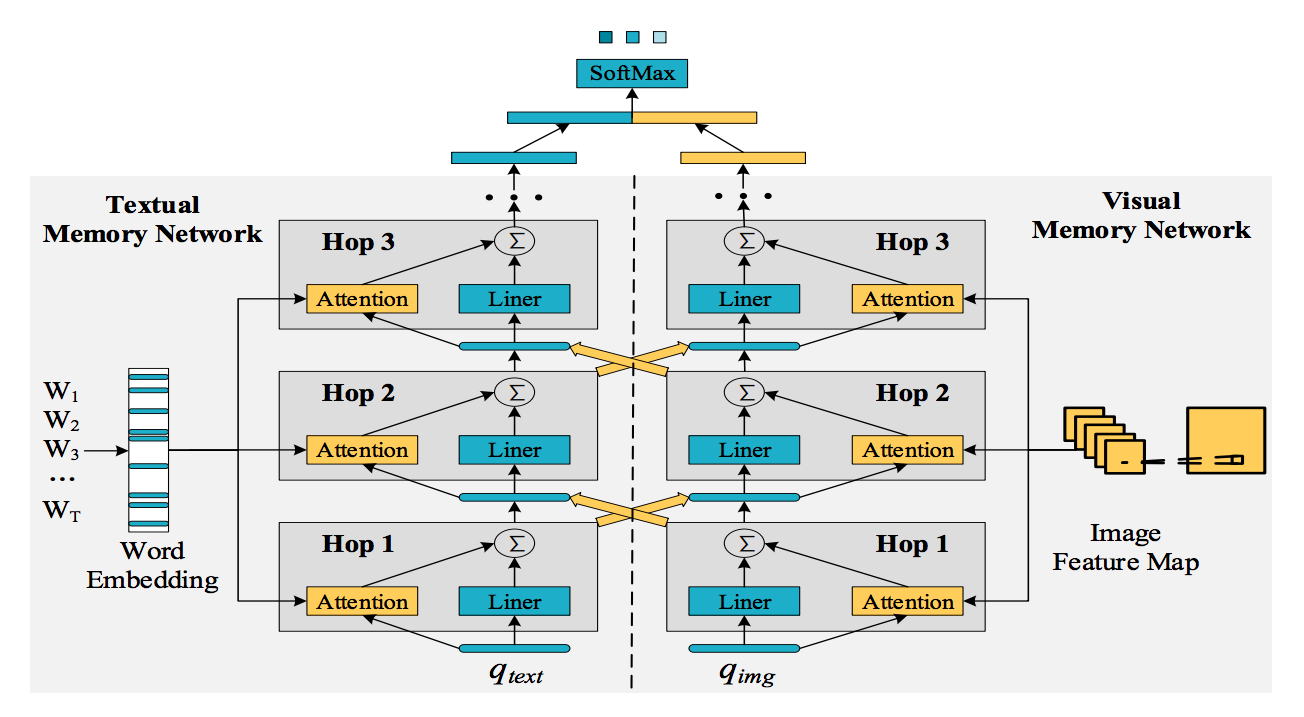
 A high-level architecture of a multimodal neural network (Image credit)
A high-level architecture of a multimodal neural network (Image credit)The text-based data was aggregated using the means of natural language processing. The recurrent neural networks utilized had a temporal awareness of what was said before in a context.
“To understand someone, you’ve got memory, and you know the context, so you are aware of what the person said before. So, you have to keep track of that, and we use recurrent neural networks for that.” —Anthony Hu, Spotify
In the very case, the text of a Tumblr blog post was broken down into a sequence of words that were embedded into a high-dimensional space to preserve semantic relationship and then fed
into a long short-term memory layer.
Training the model with TensorFlow
To read data in a parallel thread, thus ensuring it is always ready to be consumed, TFRecords—a binary file format used by TensorFlow were used for fast data processing. The TFRecordDataset consumes TFRecords and automatically creates a queue for training.
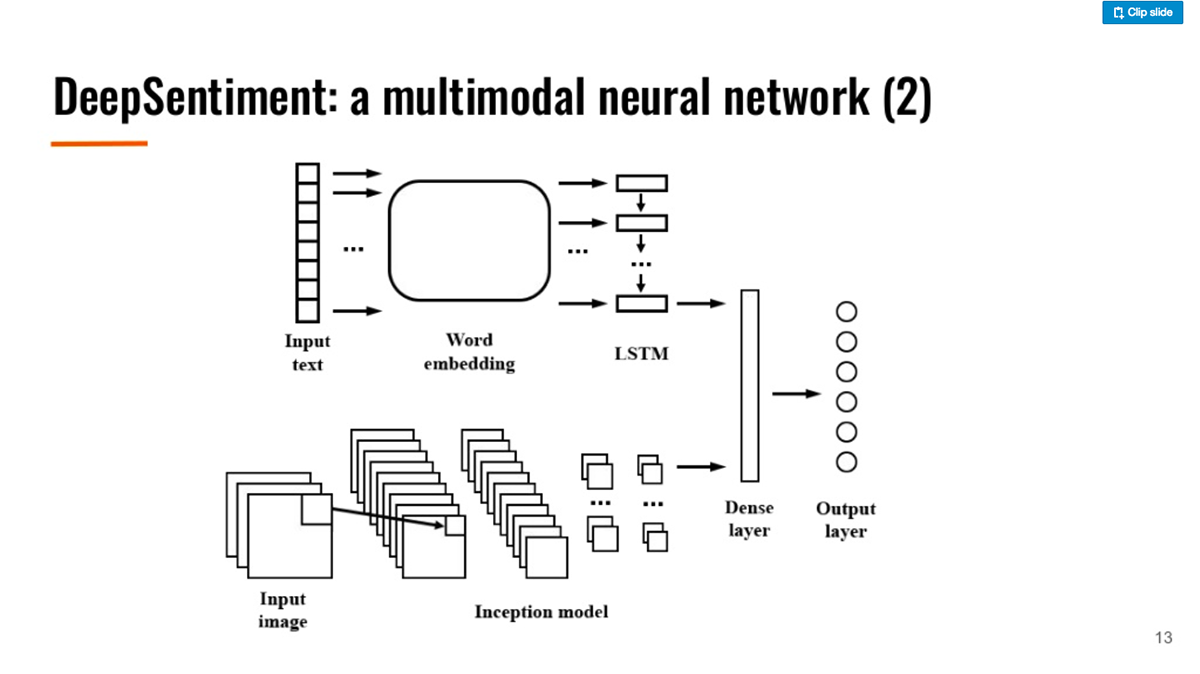
Training a model, which involved only a text-based data set, resulted in 69% of test accuracy. It was twice higher than the result of training the image-based model, which means text is a better input for recognizing emotions. The multimodal approach combining both text and images achieved 80% of training accuracy and 72% of test accuracy.
Before experimenting with multiple modalities, the team first utilized random guessing, which resulted in 11% of accuracy, and trained a purely image model, which achieved 36% of test accuracy and 43% of train accuracy. This way, the multimodal approach significantly outplays all the other models employed.
 Train accuracy results (Image credit)
Train accuracy results (Image credit)To validate how well the system recognizes different shades of emotions, the circumplex model was applied. This model suggests that emotions are distributed in a two-dimensional circular space with arousal and valence dimensions. The arousal dimension represents the vertical axis, while the valence one embodies the horizontal axis, and the center of the circle is a neutral valence and a medium level of arousal.
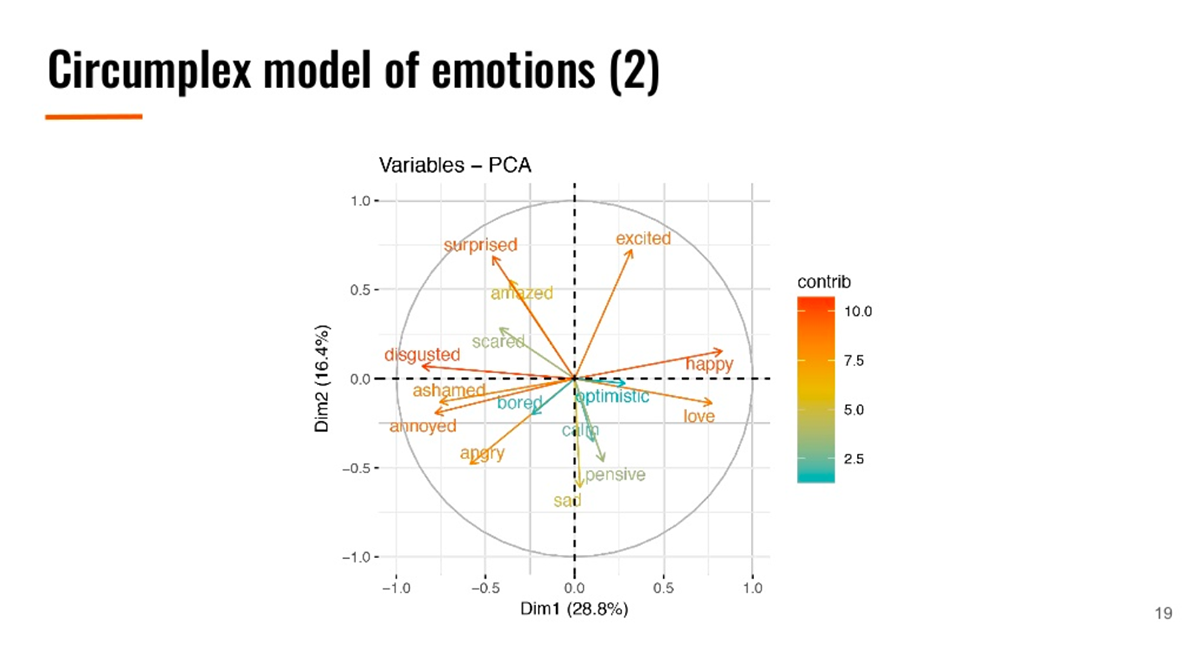 A circumplex model of emotions (Image credit)
A circumplex model of emotions (Image credit)It’s important to note that no validation set was used to tune hyperparameters, meaning that better performance could be reached. Anthony and his colleagues published a research, where they detail the approach and the findings.
Want details? Watch the video!
Table of contents
|
Related slides
Further reading
- TensorFlow for Recommendation Engines and Customer Feedback Analysis
- Natural Language Processing and TensorFlow Implementation Across Industries
- Approaches and Models for Applying Natural Language Processing
About the expert
![]()
Anthony Hu has joined Machine Intelligence Laboratory at the University of Cambridge to work on computer vision and machine learning applied to autonomous vehicles, more precisely in scene understanding and vehicle’s interpretability. Previously, he served as a research scientist at Spotify where he worked on identifying musical similarities at a large scale using audio. Anthony holds MSc in Applied Statistics from the University of Oxford. Prior to that, he went to Telecom ParisTech, one of the top French public institutions of higher education and research engineering.