Building a Chatbot with TensorFlow and Keras

The challenges
Digital assistants built with machine learning solutions are gaining their momentum. However, creating a chatbot is not that easy as it may seem. At the TensorBeat 2017 conference, Avkash Chauhan, Vice President at H2O.ai, outlined major challenges while developing an answer bot using Keras on top of TensorFlow:
- Finding proper tags
- Finding and removing not-safe-for-work (NSFW) words
- Identifying sentiment in the question (positive or negative)
- Setting priority to find the answer (low, medium, high, and critical)
- Figuring out the gender of a questioner
- Rating a question
- Removing question duplicates

Addressing the issues
To address the need of finding proper tags, one may employ word embeddings (word2vec). To find and remove not-safe-for-work words, brute-force search and the NLTK stop words can be utilized.
Sentiment in the question can be identified by enabling a binomial classification (two classes) paired with tree-based algorithms (gradient boosting, random forest, or distributed random forest) or a neural network. With that technique, one can also figure out whether a questioner is male or female.
The above-mentioned algorithms coupled with multinomial classification (four classes) may help out to set priority while looking for an answer. Question rating is defined in the same fashion, but multinomial classification embodies N classes—i.e., as much as needed—to provide for 1–5 star rating.
Finding best available answers involves three major steps:
- Look for the tags and keywords through clustering and reduction
- Create tag and keywords weights for each question
- Match tags and keywords with their weights to find top probabilities

Moving onto the issue of duplicated questions, Avkash exemplified the competition initiated by Quora. Its goal was to predict which of the provided pairs of questions contain two questions with the same meaning.
Then, Avkash demonstrated how to classify sentences to identify rating and sentiments using the following data sets:
- Real data available at Stack Overflow, Community, Quora, etc.
- Experimental data: 41 million reviews in the 1–5 star category available at Yelp
- Twitter sentiment (through searching or mining)
Training a model in a cloud
The technologies used in the course of training a model can be as follows:
- Keras on top of TensorFlow
- the NLTK stop words
- the GloVe algorithm (pre-trained word2ves data sets—400,000 words)
- Sentiment:
make-sentiment-model.pyandPositiveNegative.ipynb - Rating:
make-5star-model.pyand5StarReviews.ipynb - Prediction:
PredictNow.py
Apart from being fast, Keras supports both convolutional and recurrent neural networks, as well as their combination.
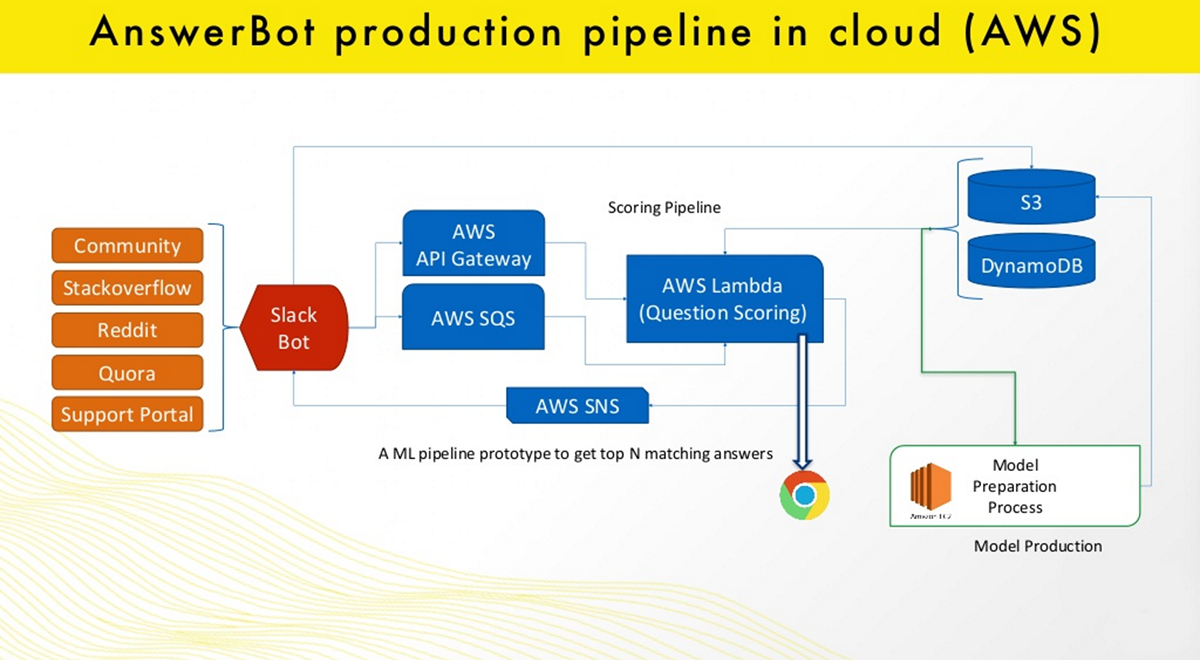 A sample production pipeline of creating a chatbot in the cloud (Image credit)
A sample production pipeline of creating a chatbot in the cloud (Image credit)After the data preparation step, one has to create a data collection and remove stop words. Then, one moves on with tokenizing and uniforming this collection to deliver a final data set, which comprises sentences (sentences_per_record, length) and labels (label_per_recordm, length).
On splitting a data set to train and validate, a predefined word vector is loaded to find match words from the collection and further create an embedding matrix. After delivering and configuring an embedding layer, the training of a model begins.

In case you hit the same prediction, there are a few scenarios to help out:
- Retrain a model.
- Rebalance a data set by either upsampling a less frequent class or downsampling a more frequent one.
- Adjust class weights by setting a higher class weight for a less frequent class. Thus, the network will focus on the downsampled class during the training process.
- Increase the time of training so that the network concentrates on less frequent classes.
To enhance data processing, Avkash suggested using such models as doc2seq, sequence-to-sequence ones, and lda2vec.
You can find the source code of an answer bot demonstrated in Avkash’s GitHub repo.
Want details? Watch the video!
Related slides
Related reading
- Machine Learning for Automating a Customer Service: Chatbots and Neural Networks
- Building a Keras-Based Image Classifier Using TensorFlow for a Back End
- Natural Language Processing and TensorFlow Implementation Across Industries
About the expert
Avkash Chauhan is Vice President at H2O.ai. His responsibilities encompass working with the global enterprise customers to bring their machine and deep learning technical requirements to the engineering team and make sure these requirements are met within the delivered products. Prior to that, Avkash had his own startup, “Big Data Analytics for DevOps,” which was acquired in 28 months after launch. You can also check out his GitHub profile.