Using Long Short-Term Memory Networks and TensorFlow for Image Captioning

Can a machine describe a picture?
TensorFlow and neural networks are actively used to perform image recognition and classification. At the recent TensorFlow meetup, attendees learnt how these technologies can be employed to enable a machine to recognize what is depicted in the image and to deliver a caption for it. In addition, an insightful overview of using TensorBoard was provided.
Pankaj Kumar of DataCabinet focused on enabling a long short-term memory network (LSTM)—on top of TensorFlow—to describe what is shown in the picture.

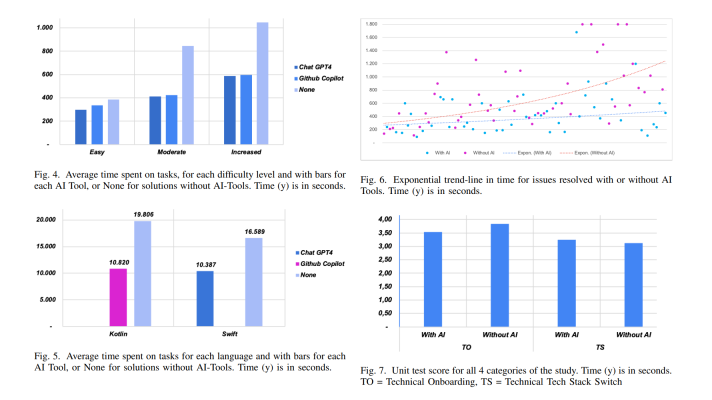
Firstly, he explained how a simple neural network operates (check out the illustration below). In his very example (on the left), one can see a two-layer neural network with a hidden layer of four neurons, or units, an output layer of two neurons, and an input layer. On the right, there is an example of a three-layer neural network with already two hidden layers. Note that in both cases, the connections (synapses) are established between neurons across layers, but not within a layer.
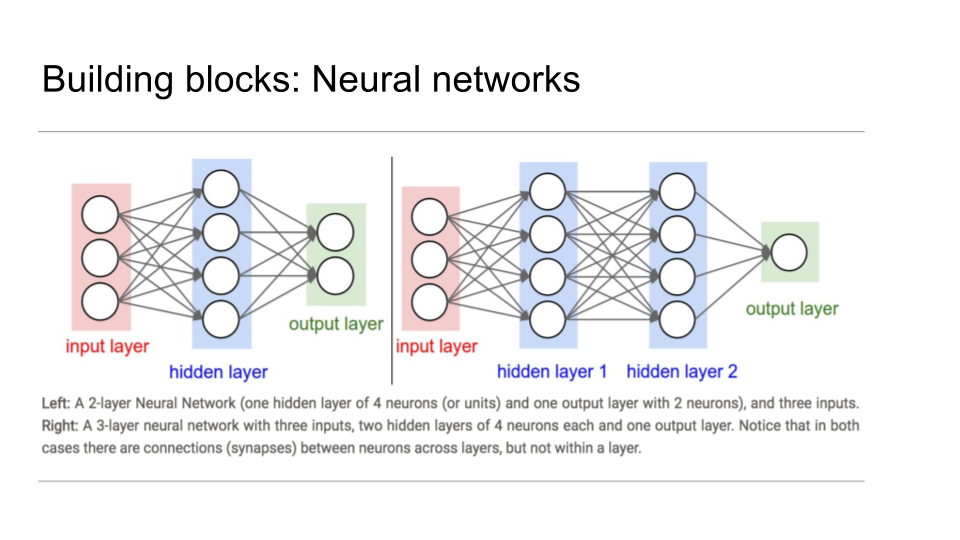
The second key element to employ for image recognition is a convolutional neural network (CNN). Pankaj noted that using CNNs allows for minimizing classification errors.
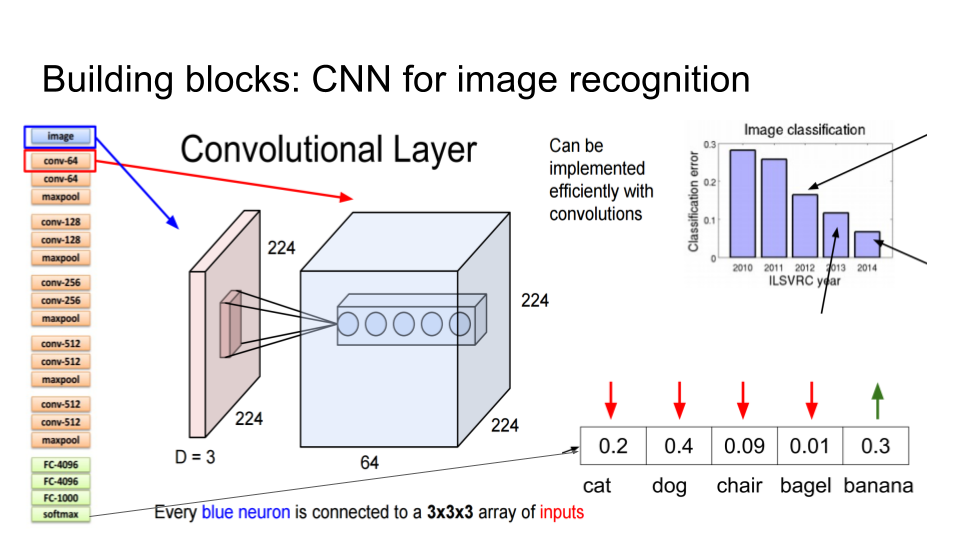
Then, recurrent neural networks are trained on a data set comprising various sentences to build a language model and make predictions. For instance, one may use Microsoft’s COCO data set with 300,000+ images and five captions per each picture.
Still, when training a recurrent neural network, one has to address the problem of a vanishing/exploding gradient.
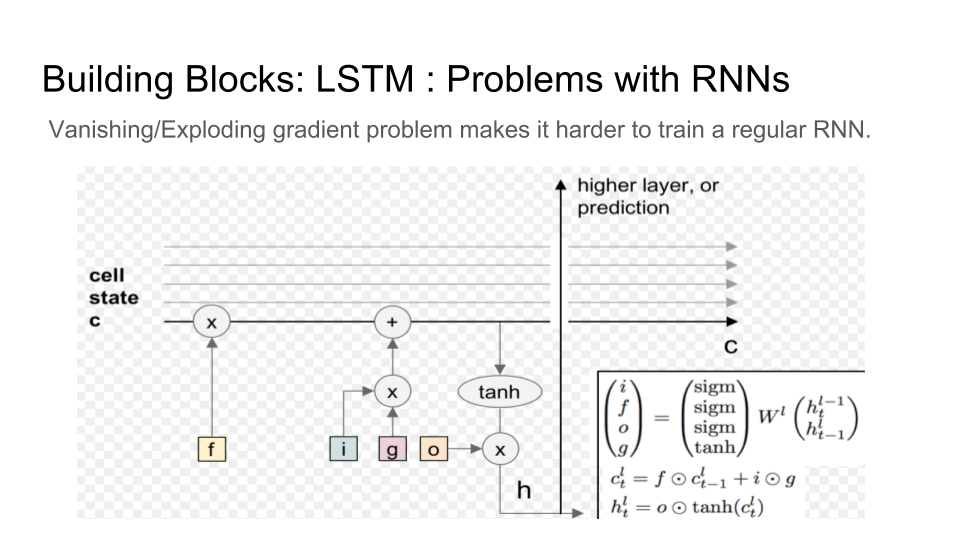
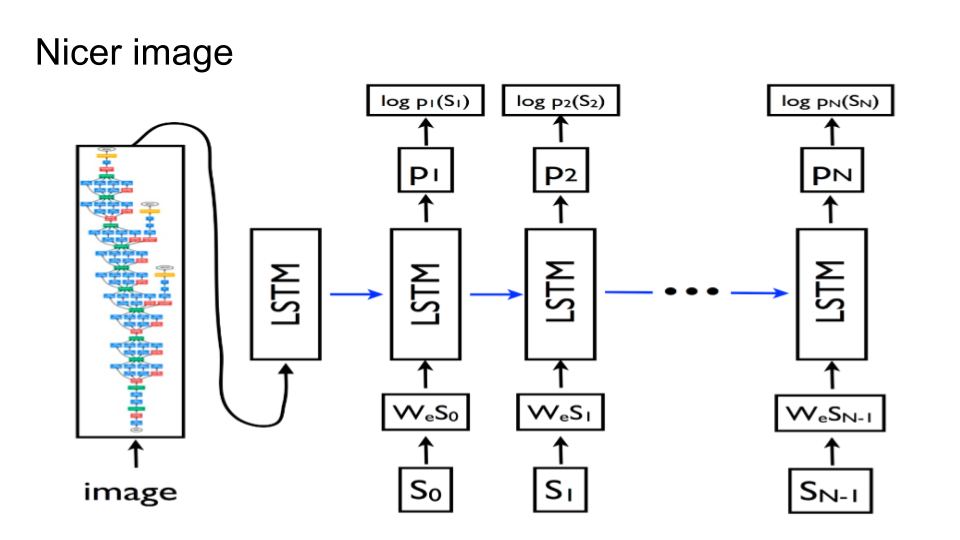
Combining recurrent and convolutional neural networks allows for avoiding word-by-word sampling. Furthermore, one can search over longer word sequences with beam search. Finally, to get a better image, an LSTM is implemented on top of TensorFlow.
How to use TensorBoard
Deepthi Mohindra demonstrated how to make use of TensorBoard to visualize a TensorFlow graph, better understand what’s under the hood, and debug the performance of model if necessary.

Join our group to stay tuned with the upcoming events.
Want detail? Watch the video!
Related slides
You can find the full presentation made by Pankaj Kumar below.
Further reading
- Text Prediction with TensorFlow and Long Short-Term Memory—in Six Steps
- Image and Text Recognition with TensorFlow Using Convolutional Neural Networks
- Recurrent Neural Networks: Classifying Diagnoses with Long Short-Term Memory
- Hitchhiker’s Guide to Using TensorFlow and LSTM for Visualized Learning
About the experts
Pankaj Kumar is a founder of DataCabinet, a company behind a cloud-based IDE solution for machine learning. It enables to maintain a project as a Jupyter notebook in the cloud and is available in beta. Before starting DataCabinet, he worked as an engineer at AppDynamics, focusing on APM agents and back ends. Pankaj graduated from the Indian Institute of Technology (Kharagpur) and then went to Purdue University for Master of Science. He has recently completed the Graduate Certificate in Statistical Data Mining and Applications from Stanford University.
Deepthi Mohindra is a quantitative analyst passionate about exploring data and extracting insights that help to drive meaningful impact. She is a huge fan of the “Datakind,” “Udacity,” and “Women Who Code” communities. You can check out her GitHub profile.