
DataOps: The Challenges of Operating a Machine Learning Model

Machine learning: expectations vs. reality
Today, data scientists have a much easier time deploying a machine learning (ML) model through the availability of data and open-source ML frameworks. While it’s a simple matter to write machine learning code to train a basic, non-distributed model with sample at-rest data, the process becomes a lot more complex when scaling up to a production-grade system.
Though there is a diversity of solutions to “operationalize” the machine learning process, one can hardly expect to just lay their hands on writing code, while the chosen instruments do the boring routine for them.
Data scientists still have to worry about such things as data cleansing, feature extraction, serving infrastructure, and the like. Surely, there are tools available to address each of these steps, but then you end up with a technology zoo to maintain. Is there a universal pill?
At a recent TensorFlow meetup in London, Emil Siemes of Mesosphere outlined the challenges behind each step of the deep/machine learning process, as well as overviewed tools that help to address the issues.
 Emil Siemes at the meetup in London (Image credit)
Emil Siemes at the meetup in London (Image credit)
What are the steps involved?
As already said, writing code is far from being the first thing you do in machine learning. According to Emil, other key steps in achieving your goals include:
- enabling distributed data storage and streaming
- preparing data for further analysis
- using machine learning frameworks to set up distributed training
- managing the trained models and metadata
- serving the trained models for inference
“Before you write your machine learning code, you have to collect data, clean the data, and verify the data. There are a lot of activities you need to do. Finally, when you’ve created your model, you have to understand how to put up a serving infrastructure, you have to monitor it, you need to create a process to update it, and so on.” —Emil Siemes, Mesosphere
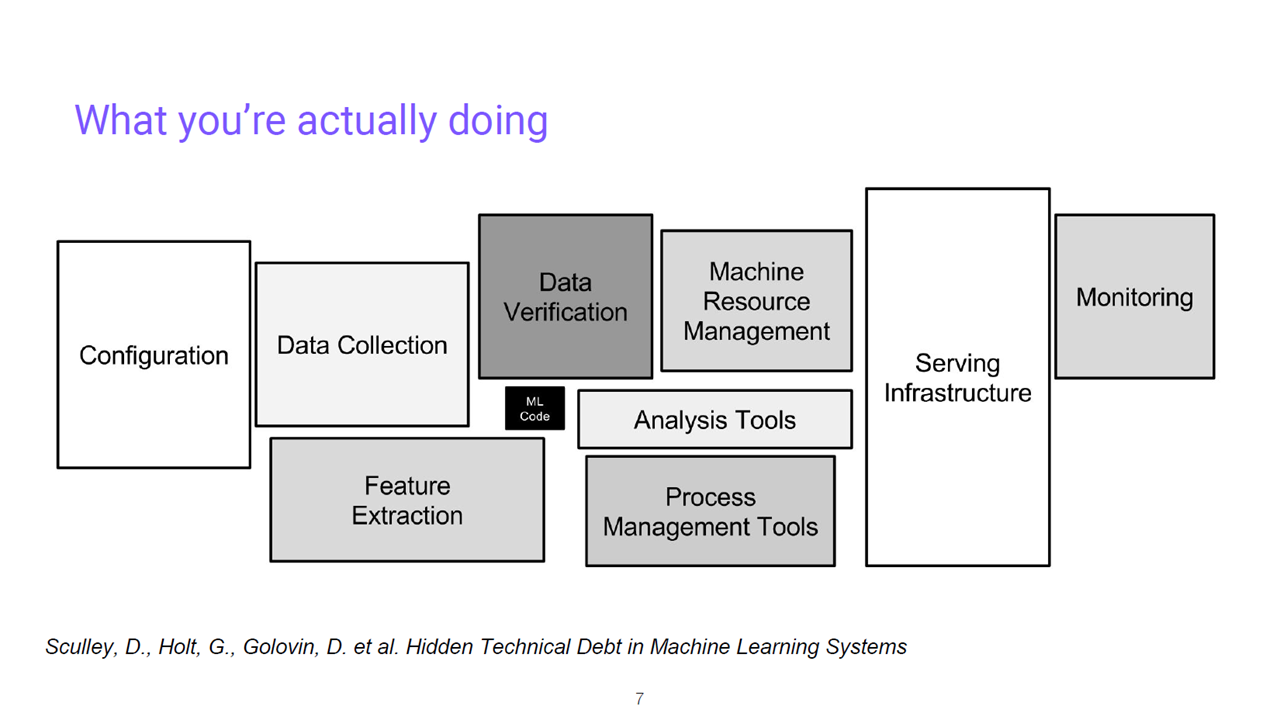 Writing ML code is a small portion of the process (Image credit)
Writing ML code is a small portion of the process (Image credit)
What are the challenges?
Emil also mentioned the problems associated with each step in the process. He also listed a few popular solutions that can be used to resolve them.
The issues with enabling distributed data storage and streaming are typically related to handling large amounts of data. The solutions that can come helpful are HDFS, Apache Kafka, and Apache Cassandra.
In model engineering, data is typically not ready to be used by a machine learning model immediately, so one needs to properly clean it and format. The instruments to consider are Apache Spark and Flink.
When it comes to training a model, a machine learning framework has to be installed on all machines, and then it becomes a matter of resource isolation and allocation. In this case, such solutions as TensorFlow, PyTorch, Apache Spark, and Apache MXNet come to rescue.
Model management becomes an issue, once trained ML models and data sets begin to accumulate. One may rely on HDFS, Google File System, MongoDB, and ArangoDB.
In model serving, deployments need to have minimal downtime. Seldon Core and TensorFlow Serving may be utilized.
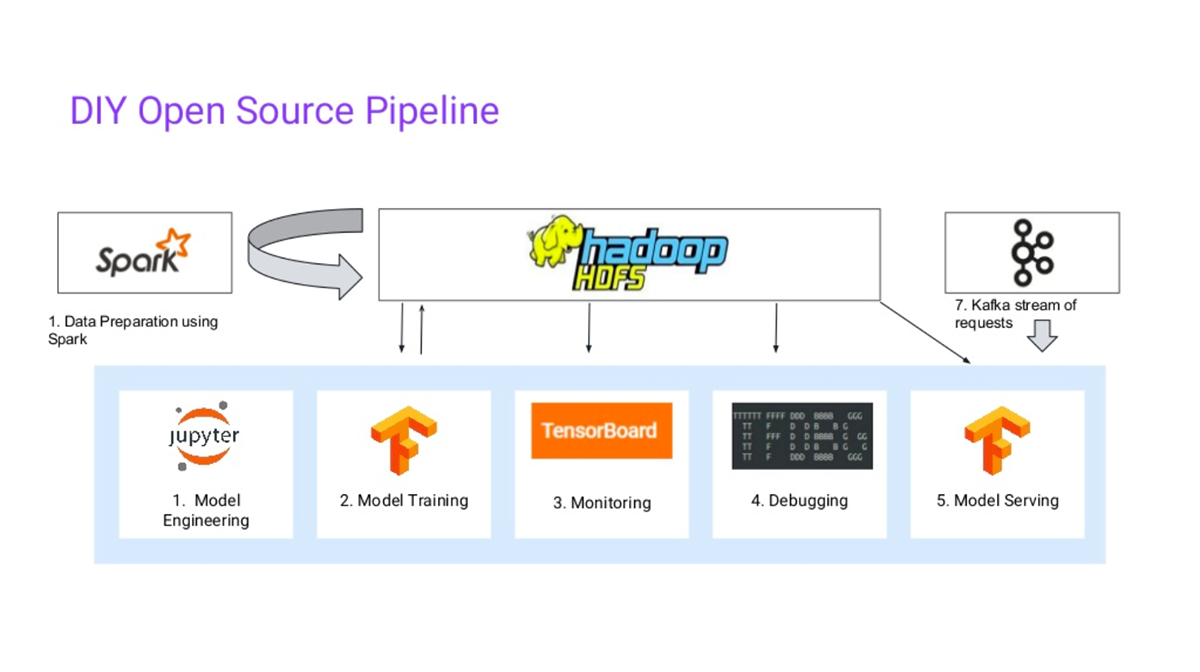 A diversity of technologies in a machine learning pipeline (Image credit)
A diversity of technologies in a machine learning pipeline (Image credit)Without an platform, data scientists looking to scale up from training basic ML models will have to deal with each of these challenges. There have been efforts to simplify operations for data scientists and let them focus on pure deep/machine learning things. For instance, Kubeflow, which was designed to automate the deployment of TensorFlow-based models to Kubernetes. Are there any similar solutions that integrate the collection of technologies into a unified interface?
Mesosphere DC/OS
Emil gave a brief demo of the Mesosphere DC/OS platform that integrates a lot of useful instruments to deploy and manage data-rich apps that use machine learning. According to its official documentation, the solution is positioned as a distributed system, a cluster manager, a container platform, and an operating system. The platform provides support for most of the services a data scientist would need to resolve the operational issues. In the service catalog, one may find all the available tools, as well as guides how to start them within Mesosphere DC/OS.
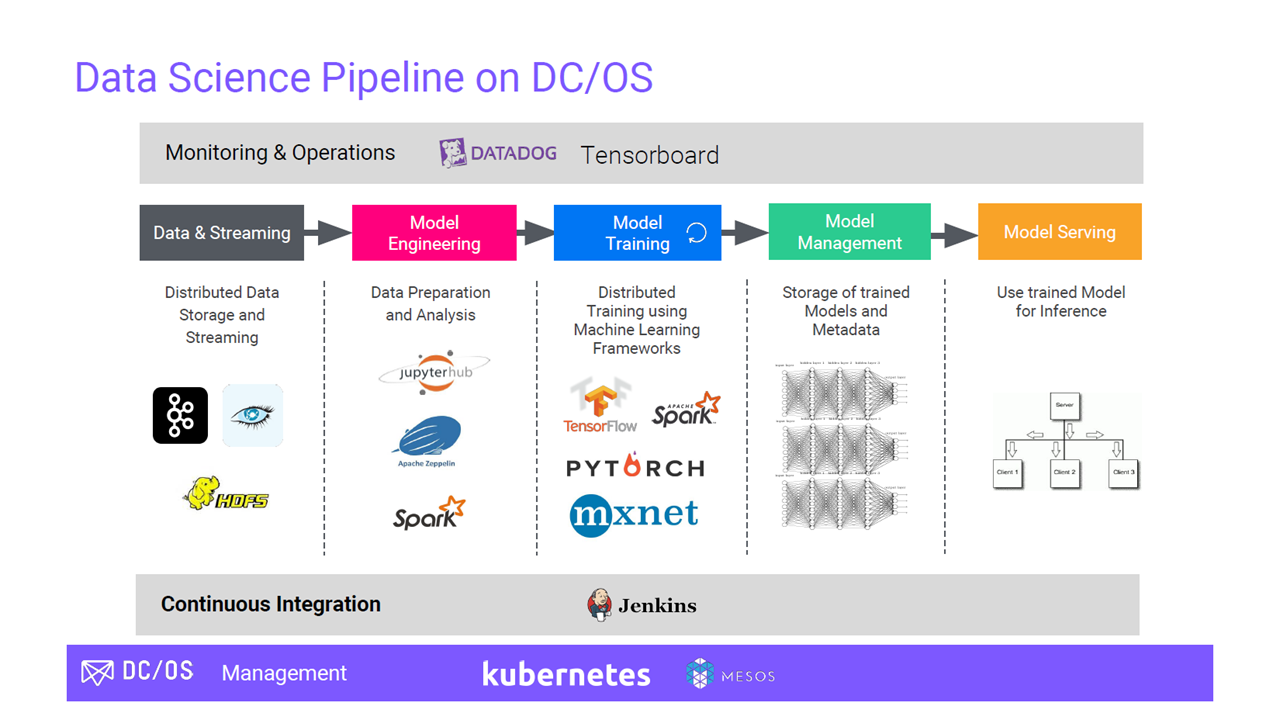 Data science platform pipeline (Image credit)
Data science platform pipeline (Image credit)In terms of machine learning, the Mesosphere DC/OS platform provides support for distributed TensorFlow on the infrastructure of choice. You can find the instructions on how to run TensorFlow on Mesosphere DC/OS in the documentation maintained by the community or in this GitHub repo.
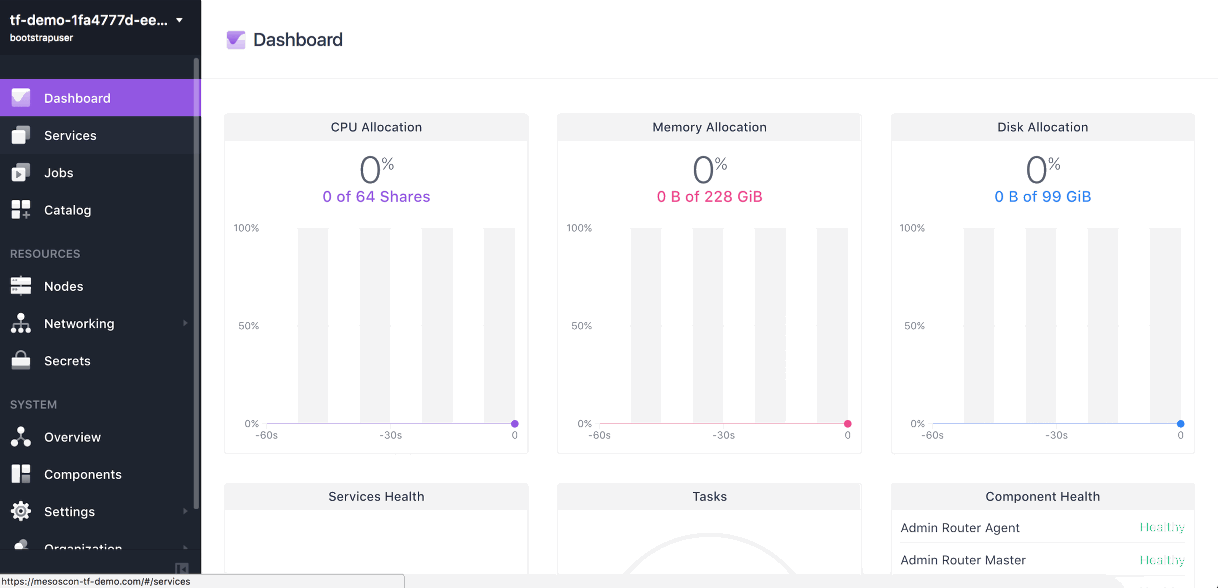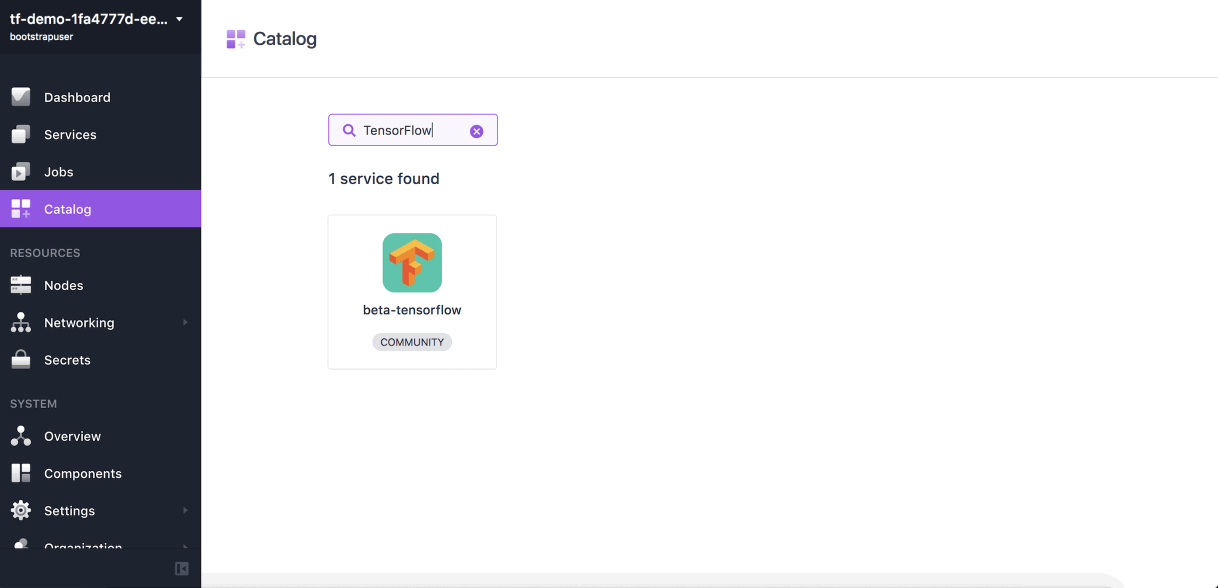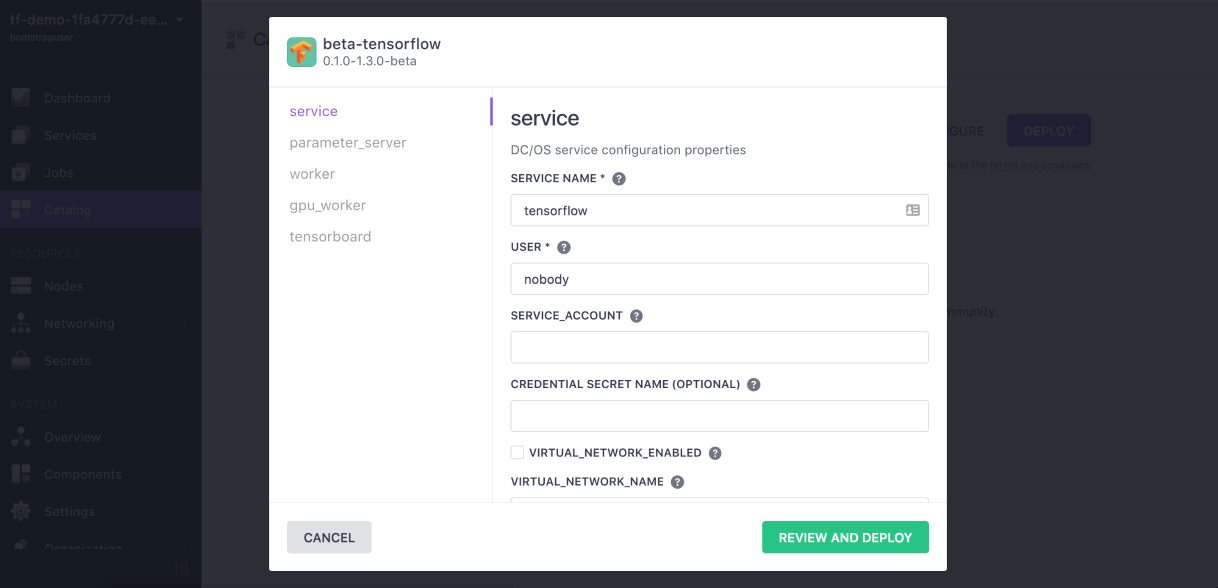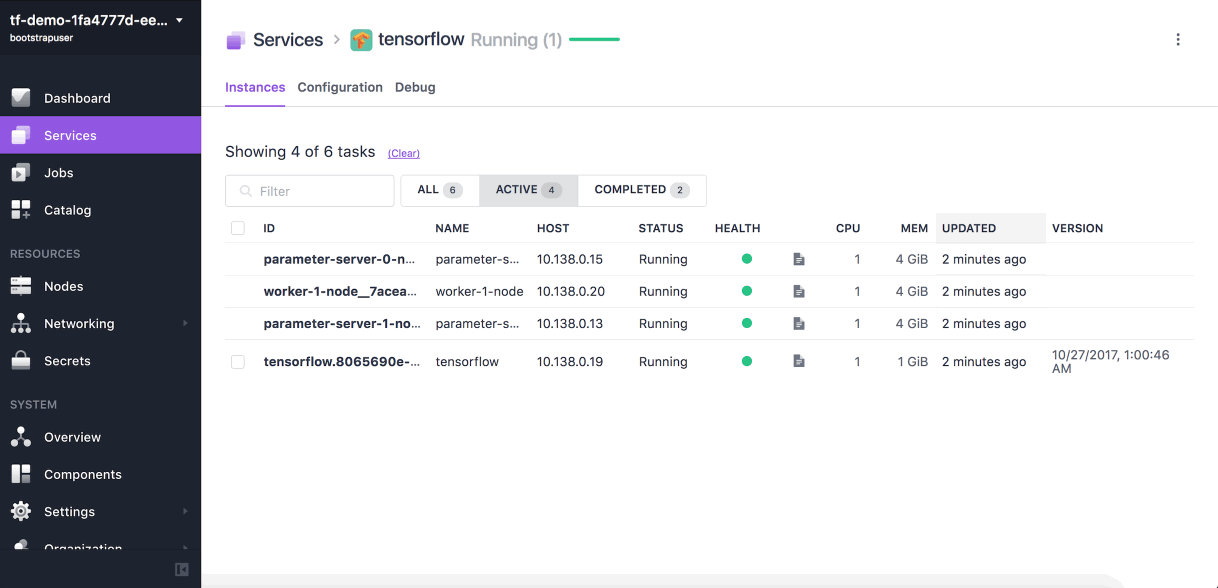 GIF: Running TensorFlow on Mesosphere DC/OS (Image credit)
GIF: Running TensorFlow on Mesosphere DC/OS (Image credit)As the fields of machine machine learning proliferate, and the models grow in complexity, data scientists surely need a solution that maximizes their efficiency and allows for doing first things first. Hopefully, the operational tools are also evolving to fit the needs of artificial intelligence.
Want details? Watch the videos!
Table of contents
|
Related slides
Further reading
- Kubeflow: Automating Deployment of TensorFlow Models on Kubernetes
- Three Approaches to Testing and Validating TensorFlow Code
- Managing Multi-Cluster Workloads with Google Kubernetes Engine
About the expert





