
Volcano: Scheduling 300,000 Kubernetes Pods in Production Daily

The need for a unified batching system
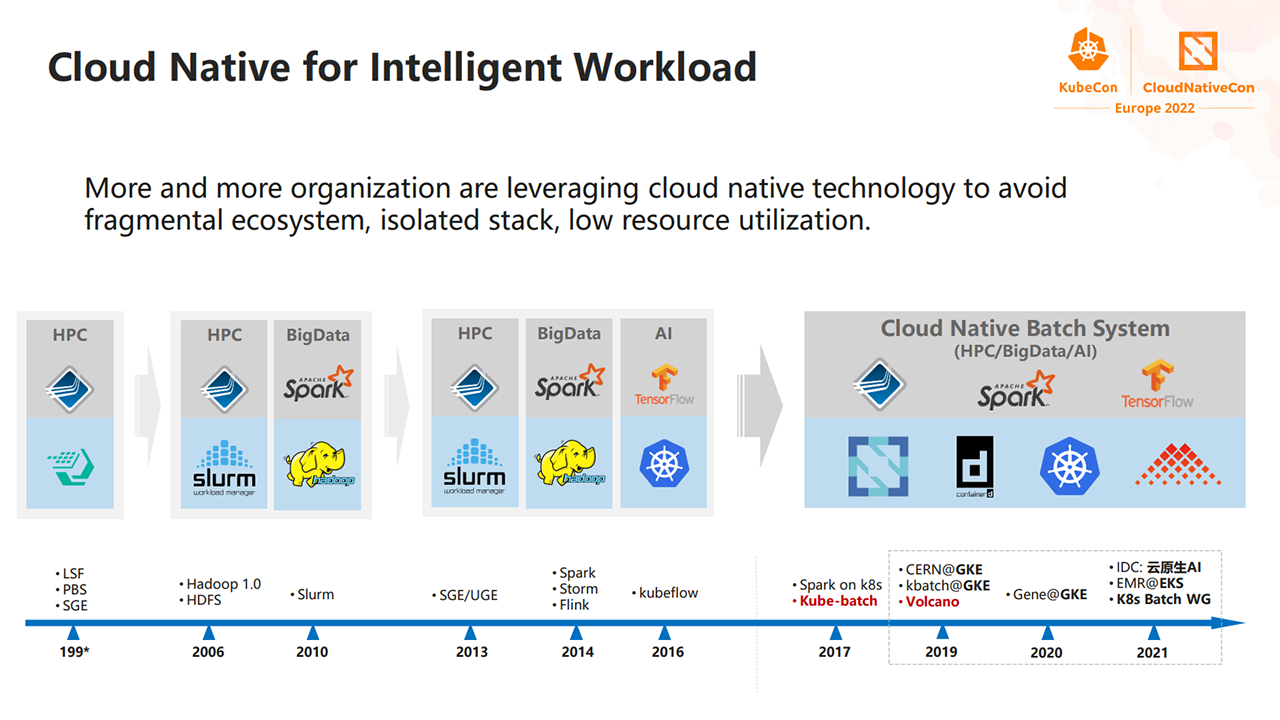
Over two decades ago, companies started running high-performance computing (HPC) applications. Next, in 2006, new technologies were developed to manage the growth of big data. Then, in 2016, cloud-native platforms became the ideal choice for running artificial intelligence (AI) workloads. This resulted in companies having multiple technical ecosystems, making it hard to manage workloads and share resources.
 Workload trends throughout the years (Image credit)
Workload trends throughout the years (Image credit)These days, more and more organizations are making use of cloud-native technologies, such as Kubernetes to create a unified platform for all their workloads. However, there remain a few key challenges that are preventing Kubernetes from being an optimal solution for batch computing.
According to William Wang of Huawei, Kubernetes needed some fine-tuning in certain areas to make it ideal for batch workloads. These include:
- lack of fine-grained life cycle job management
- insufficient support for mainstream computing frameworks, such as TensorFlow, PyTorch, Open MPI, etc.
- missing job-based scheduling and limited scheduling algorithms
- not enough support for resource-sharing mechanisms between jobs, queues, and namespaces

William Wang
The features mentioned are what Volcano, an incubator project by the Cloud Native Computing Foundation (CNCF), is looking to provide.
“Batch computing workloads have higher demand for throughput from the system. Kubernetes cannot effectively run these requests without performance tuning.”
—William Wang, Huawei
What is Volcano?
Volcano is a system for running high-performance workloads on Kubernetes. The project features batch scheduling capabilities that are not provided by Kubernetes, but are typically required by machine learning and big data workloads. Volcano was initially developed in March, 2019 and was later accepted as an incubator project by the Cloud Native Computing Foundation in April, 2022.
Volcano provides:
- support for multiple scheduling algorithms
- efficient job scheduling
- nonintrusive support for mainstream computing frameworks
- support for multiarchitecture computing
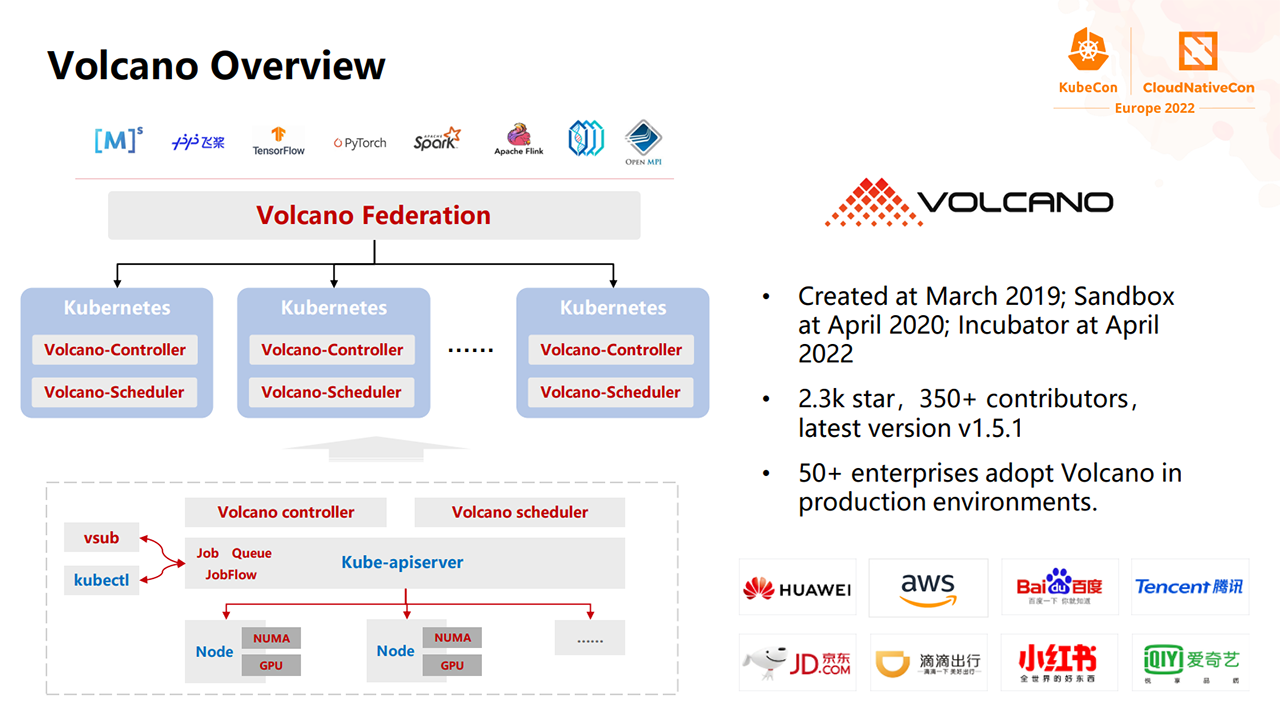 Overview of Volcano (Image credit)
Overview of Volcano (Image credit)The tool supports gang, fair-share, topology-based, proportional, elastic, and service-level agreement (SLA) scheduling algorithms.
“Volcano is not just a scheduler. It has a job controller to support enhanced job life cycle management. It has a queue that enables resource planning and sharing to multitenants.”
—William Wang, Huawei

Klaus Ma
During KubeCon Europe 2022, Klaus Ma, Senior Manager at NVIDIA (ex-Huawei), explained that the project uses multiple templates in order to support different computing frameworks. Volcano also provides fine-grained job life cycle management, noted Klaus. For example, when a task fails, the entire job can be restarted automatically.
“In Volcano, we introduce job customer resource definitions (CRDs) through multiple templates, providing support for different computing frameworks, including TensorFlow, Spark, PyTorch, Open MPI, MXNet, etc.”
—Klaus Ma, ex-Huawei
 An example of an Open MPI job (Image credit)
An example of an Open MPI job (Image credit)Additionally, Volcano includes plug-ins, enabling users to customize jobs. For instance, the SVC plug-in creates a headless service for communication between pods.
Next, to enable resource planning and sharing between tenants, Volcano utilizes queues, which are created at the cluster level. Each queue can be configured to follow specific policies—such as “first in, first out” (FIFO), fair share, priority, etc.
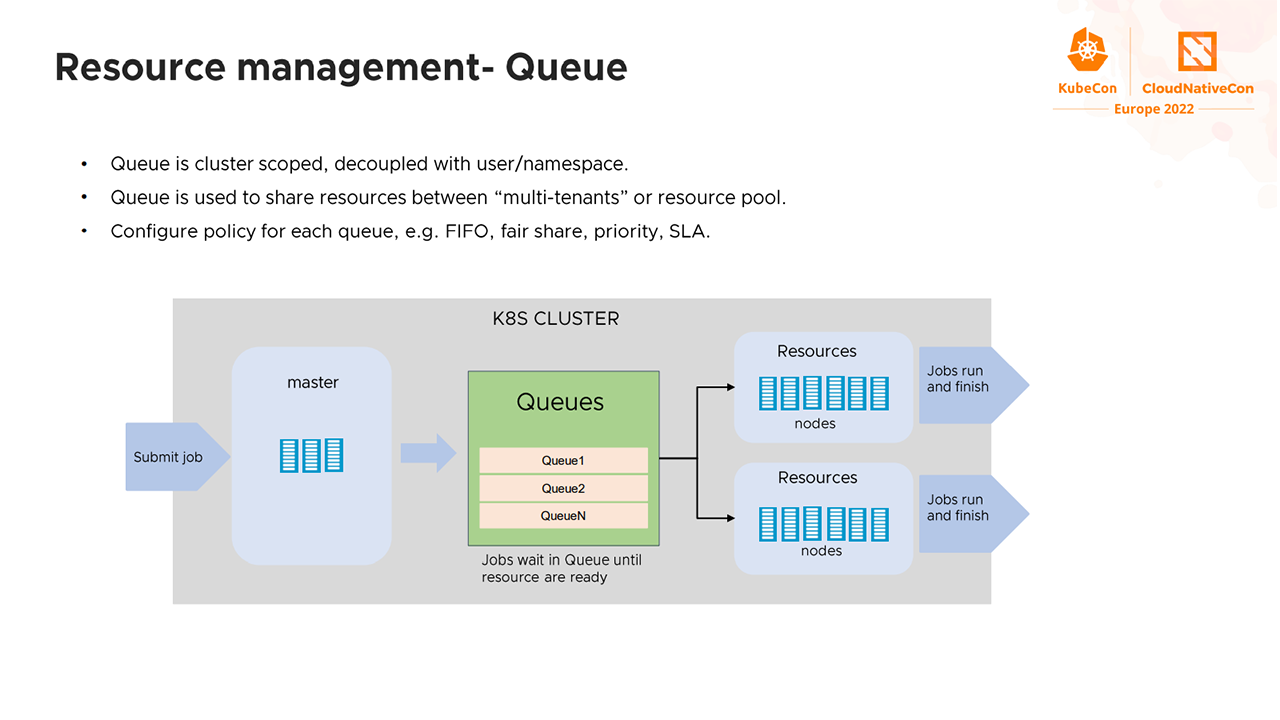 Queues in Volcano (Image credit)
Queues in Volcano (Image credit)Volcano provides dynamic resource sharing between queues. Resources are allocated based on the weight of a queue. For example, in a scenario where there are two queues: Q1 with a weight of 2 and Q2 with a weight of 1, two-thirds of the resources will be allocated to Q1, while one-third to Q2. Dynamic resource sharing can be managed by setting a guarantee and a capacity to each queue. The former sets the minimum resources that should always be available to a queue, while the latter sets the maximum resources a queue can have.
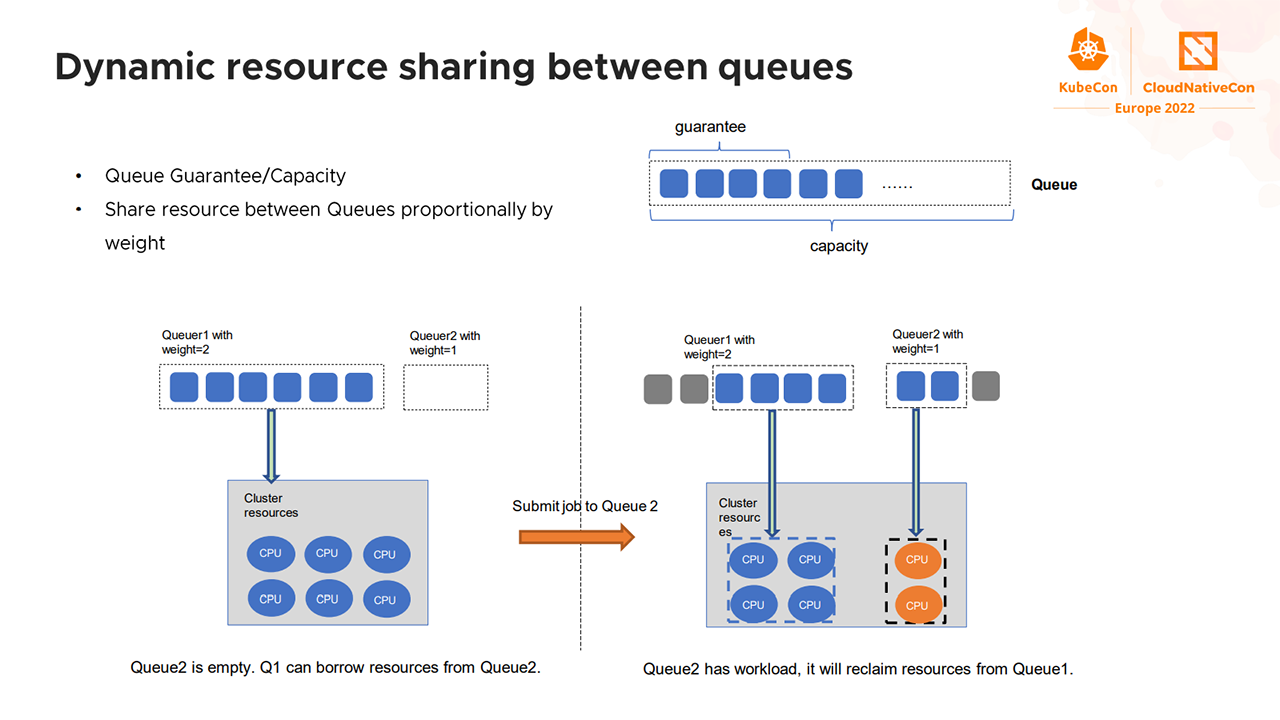 Dynamic resource sharing (Image credit)
Dynamic resource sharing (Image credit)Volcano also enables fair share of resources within queues. This can be configured between jobs and namespaces.
“Fair share is an important requirement for elastic or streaming jobs like Spark. Volcano provides fair share between jobs and namespaces. This is important for a multitenant environment.”
—Klaus Ma, ex-Huawei
Scenarios for Volcano
Since the project was designed to facilitate high-performance workloads, Klaus and William recommended a few scenarios where Volcano could come in handy. According to William, machine learning workloads have higher demand for GPU resources compared to traditional workloads. By utilizing elastic scheduling and parallel jobs, GPU resources can be allocated optimally.
 Example of elastic scheduling (Image credit)
Example of elastic scheduling (Image credit)“Improving GPU utilization is a hot topic and has great value. Elastic scheduling can dynamically adjust the number of instances involved in training, greatly improving the utilization of GPU resources, especially in a public cloud. It can work in a small instance, lowering the cost, while improving training efficiency.”
—William Wang, Huawei
In a production scenario, there are typically small and big jobs that are competing for resources. In this case, SLA scheduling is an ideal option, noted Klaus. With SLA scheduling, users can configure jobs, so that they are completed prior to deadlines.
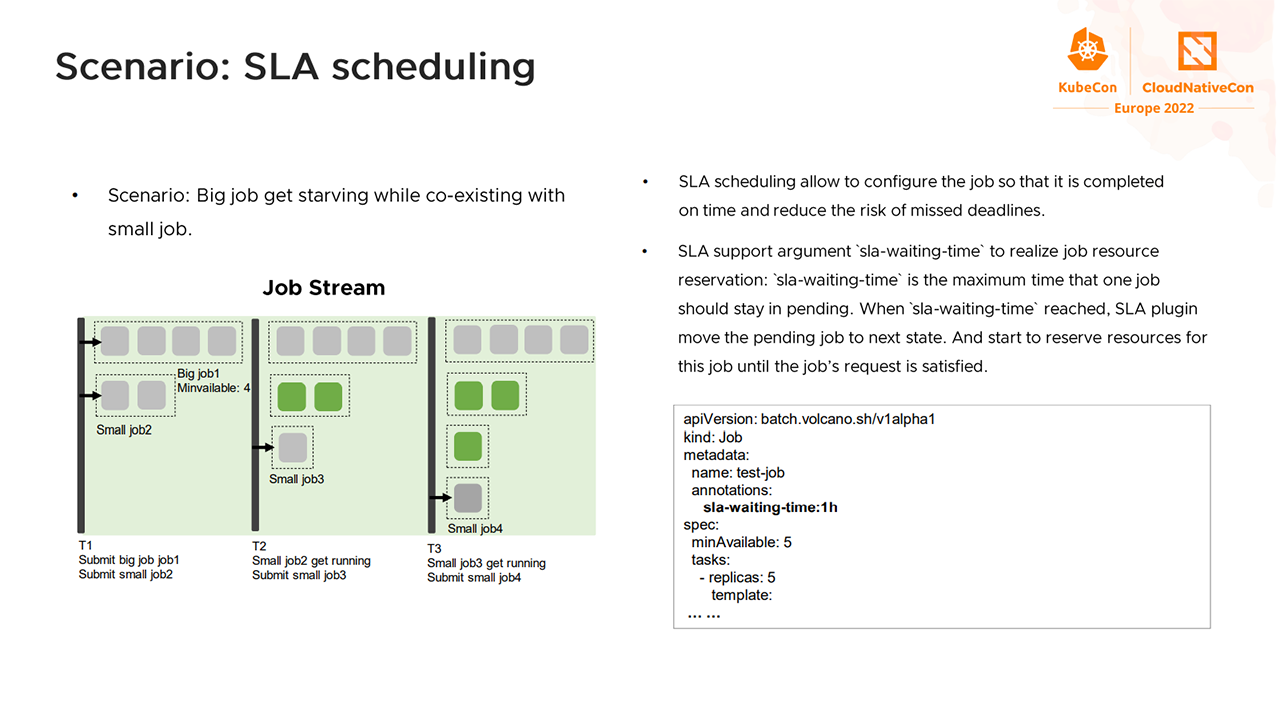 Example of SLA scheduling (Image credit)
Example of SLA scheduling (Image credit)
Managing batch jobs for an investment firm
Ruitian Capital is a hedge fund management firm in China. It is considered as one of the top financial investment companies in the country. Initially, Ruitian Capital relied on Yarn to schedule batch jobs. As the company grew, strategic planners had to work in different environments, prompting the adoption of container technologies, such as Kubernetes.
However, the default scheduler of Kubernetes lacked certain features, including running multiple pods in a single job, fair-share scheduling of jobs assigned to different queues, gang scheduling, etc. The company also required jobs to run in various frameworks, which meant having to spend additional resources on installing different operators in Kubernetes.
While researching solutions to its problems, Ruitian Capital discovered the Volcano project, which is based on Kubernetes, as well as has job scheduling and control policies that met the firm’s requirements.
 Scheduling 300,000 pods in production per day (Image credit)
Scheduling 300,000 pods in production per day (Image credit)“While looking for a solution, Ruitian Capital found that Volcano can satisfy their requirements. They used Volcano to create a unified job specification for all kinds of artificial intelligence training workloads. Eventually, they decided to migrate from Yarn to Kubernetes with Volcano. Currently, they schedule over 300,000 pods everyday in production.”
—Klaus Ma, ex-Huawei
Volcano v1.6.0 was recently released on June 12, 2022. Some of the planned upcoming features include multicluster scheduling and data affinity scheduling.
Since being accepted as an incubator project by the CNCF, Volcano has continued to grow with more than 350 contributors. The project has also been adopted into production by over 50 enterprises, including Amazon, Tencent, Baidu, and Huawei. Anyone interested in Volcano can track ongoing developments in the project’s GitHub repo.
Want details? Watch the videos!
Klaus Ma provides an overview of Volcano at KubeCon Europe 2022.
William Wang discusses Volcano in an online presentation.
Further reading
- KubeEdge: Monitoring Edge Devices at the World’s Longest Sea Bridge
- Longhorn Provides Persistent Storage for 35,000 Kubernetes Nodes
- Osaka University Cuts Power Consumption by 13% with Kubernetes and AI
About the experts

William Wang is Architect at Huawei. He is also the community technical lead for Project Volcano. William is experienced in batch systems, big data, and AI workload performance acceleration. He is currently working on a multicluster scheduling project and a hybrid scheduling project.

Klaus Ma is Senior Manager at NVIDIA, ex-Huawei. He is a system architect, designer, and software developer with 10+ years of experience across a variety of industries and technology bases, including cloud computing, machine learning, big data, and financial services. Klaus is the Founder of Project Volcano and kube-batch.





