
Longhorn Provides Persistent Storage for 35,000 Kubernetes Nodes

The challenges with persistent storage
Containers work well with stateless applications as there is no need to save data. Kubernetes can rapidly create and remove containers, because the applications within the containers are packaged up with all of their dependencies.
However, the dynamic creation and removal of containers can run into problems with stateful apps that require persistent storage. A stateful containerized application must have consistent and reliable access to its data. This means persistent storage cannot easily be created and removed dynamically. (Previously, we’ve written about some considerations when running stateful apps on Kubernetes.)
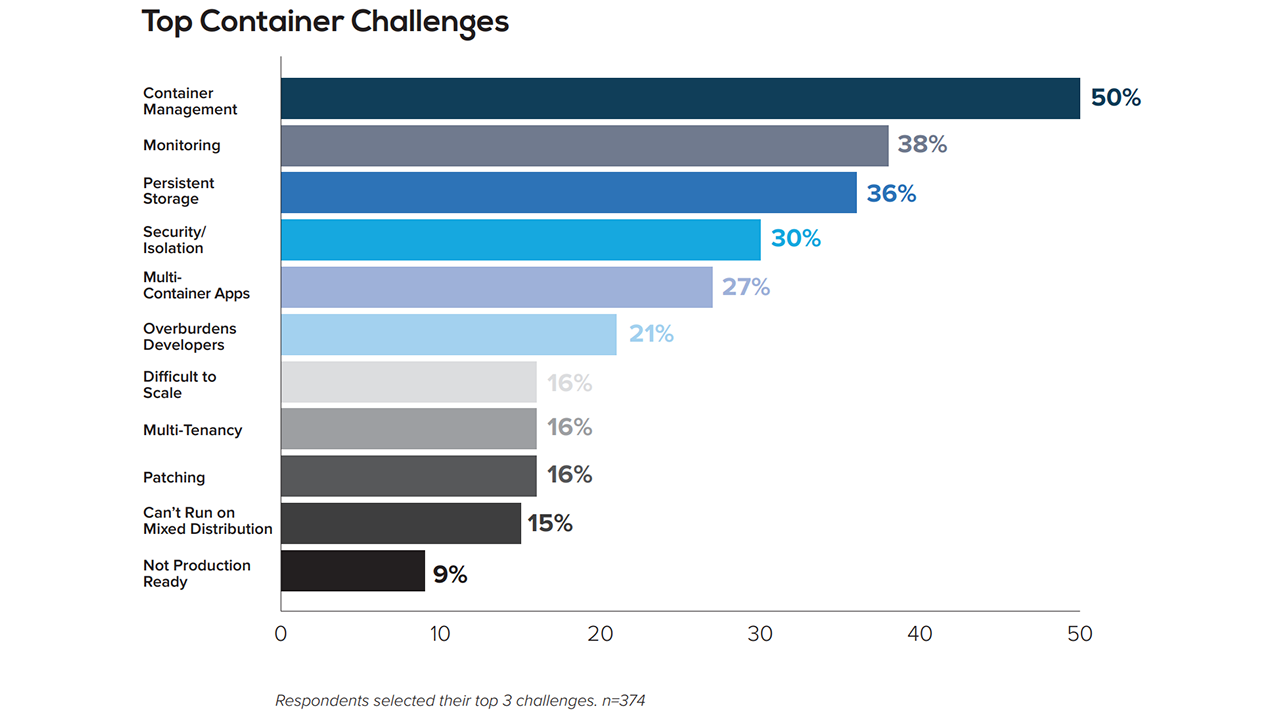 Persistent storage is a primary concern (Image credit)
Persistent storage is a primary concern (Image credit)During a Rancher Online Meetup, David Ko from SUSE highlighted additional challenges related to storage when using Kubernetes:
- Most traditional external storage arrays are expensive and inflexible.
- External replication solutions are not application-aware, so replication involves the entire data store, instead of pods and their volumes, increasing recovery time.

David Ko
“If you want to have a storage solution using external storage arrays, there are some factors you need to consider, like location and infrastructure constraints. Also, traditional external storage arrays are not designed for Kubernetes.”
—David Ko, SUSE
The challenges mentioned above is what Longhorn, an incubator project by the Cloud Native Computing Foundation, is looking to resolve.
What is Longhorn?
![]()
Longhorn is a cloud-native distributed block storage system for Kubernetes, designed to run on top of different types of physical storage devices, infrastructures, and architectures. It was initially developed by Rancher Labs and was accepted as an incubator project by the Cloud Native Computing Foundation on October 11, 2019.
Longhorn enables DevOps teams to manage persistent data volumes in any Kubernetes environment, while bringing a vendor-neutral and an enterprise-grade approach to cloud-native storage.
At KubeCon Europe 2020, Sheng Yang from SUSE overviewed some of the design principles behind Longhorn:
- Data is written in multiple replicas simultaneously. Even if multiple nodes go down, so long as there is a single replica, data can be recovered.
- While Longhorn is customizable, first-time users can use a one-click installation to deploy quickly.
- Recover from the worst scenarios with a single hard drive. Upgrade without interrupting workloads.
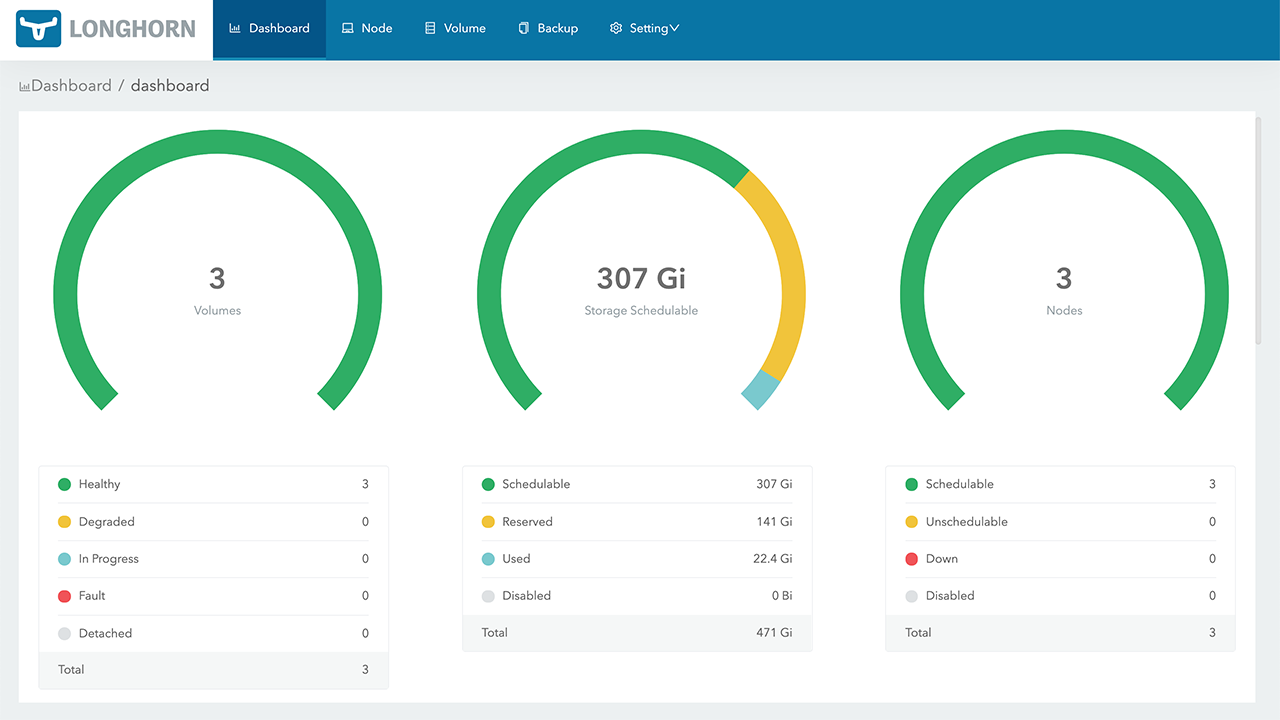 Longhorn’s dashboard (Image credit)
Longhorn’s dashboard (Image credit)The project enables:
- enterprise-grade distributed block storage software for Kubernetes
- volume thin-provisioning, snapshots, expansion, as well as backup and recovery
- cross-availability-zone replica scheduling
- recurring jobs of snapshot and backup
- cross-cluster disaster recovery volume with defined recovery time objectives (RTO) and recovery point objectives (RPO)
ReadWriteMany(RWX) support- automated nondisruptive software upgrades

Sheng Yang
“Our target for Longhorn is to get persistent storage everywhere. Kubernetes is already pretty good at handling stateless workloads, but when it comes to stateful workloads like databases, there are always concerns. Longhorn was developed to address that.”
—Shen Yang, SUSE
(In this blog post, you can read how to enable persistent storage using Docker’s volumes and swarms, as well as Kubernetes PersistentVolumes.)
How it works
Longhorn has two layers: the data plane and the control plane. The Longhorn Engine is a storage controller that corresponds to the data plane. The Longhorn Manager corresponds to the control plane.
The Manager pod runs on each node in the Longhorn cluster as a Kubernetes DaemonSet. It is responsible for creating and managing volumes in a Kubernetes cluster.
The Manager communicates with the Kubernetes API server to create a new Longhorn volume customer resource definition (CRD). Next, the Longhorn Manager waits for the API server’s response. When it sees that the Kubernetes API server has created a new Longhorn volume CRD, the Manager creates a new volume.
When making a new volume, the Manager creates a Longhorn Engine instance on the node the volume is attached to. It then creates a replica on each node where a replica will be placed.
“The process of creating replicas and engines only takes a couple of seconds,” explained Shen. “That is how fast Longhorn can attach and detach volumes.”
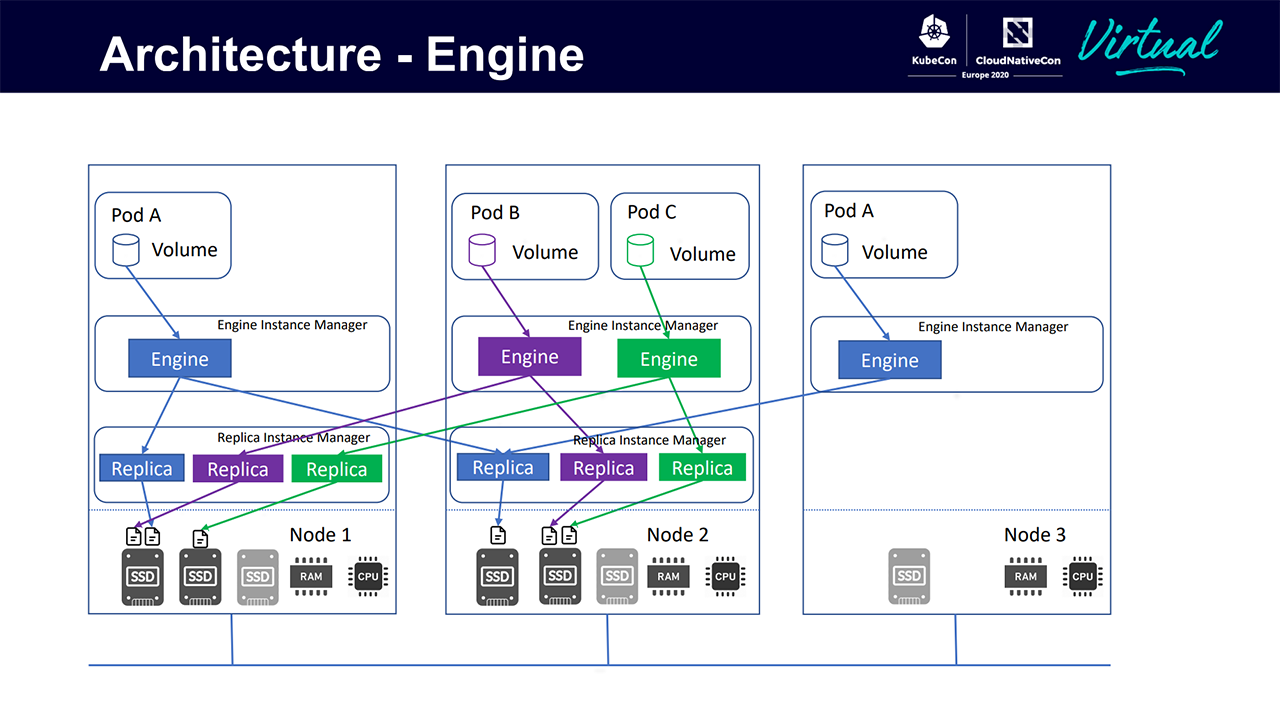 Longhorn’s architecture (Image credit)
Longhorn’s architecture (Image credit)A Longhorn volume achieves high availability thanks to the multiple data paths of the replicas. Should a problem occur with a certain replica or an engine, the pod will continue to function normally. “Engines and replicas are grouped,” added Shen. “Each group has a contained data path, and they do not interact with each other. This is an advantage of Longhorn’s design.”
“The data path of Longhorn does not interfere with any other volume. If one volume goes down, there is no way to affect other volumes, engines, and replicas. By doing this, we can avoid having a highly available engine for whole clusters. Instead, we have small engines and replicas dedicated to each volume.” —Shen Yang, SUSE
Future plans
Since the project was donated to the CNCF in 2019, Longhorn has experienced exponential growth. The project is considered production-ready and is already being used by multiple organizations. For instance, Cerner (NASDAQ: CERN), a health information technology company, relies on Longhorn for persistent storage and highly available data replication. Another example is Tribunal Regional Eleitoral do Pará, the regional electoral court of the state of Pará, Brazil, which uses Longhorn as the storage back end for Prometheus and other tools.
“After the CNCF donation, we have seen 15x growth. Across the world, we have 35,000 active nodes that are running Longhorn. The project is not only being used by the open-source community, but also top enterprises, which means Longhorn is ready for production.” —David Ko, SUSE
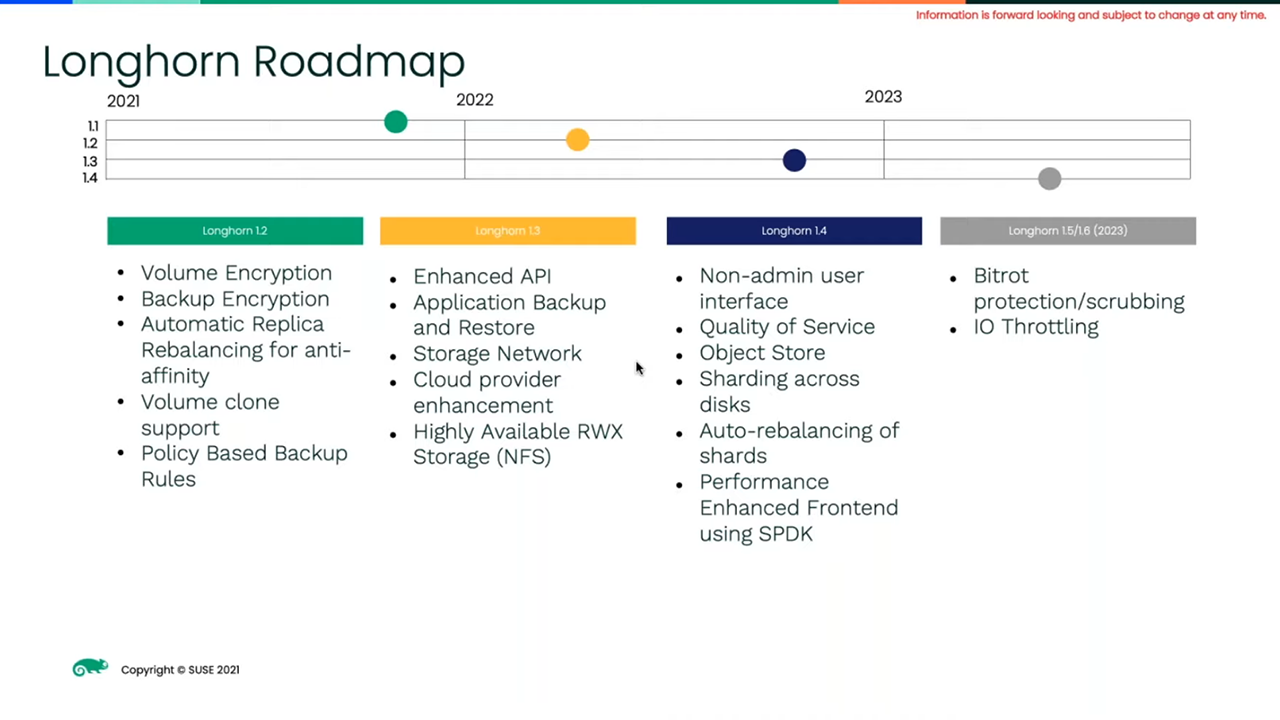 The project’s roadmap (Image credit)
The project’s roadmap (Image credit)Longhorn v1.2 was released in September 2021. Since then, the community has been working on incremental improvements ahead of v1.3, the next major update.
“For the upcoming release of Longhorn v1.3, we are trying to enhance and pay more attention to the API interface,” explained David. “Not everyone wants to upgrade from the Longhorn UI, so there needs to be some integrated automation.”
In addition to RWX maturity, some of the other features planned for v1.3 include:
- consistent application backup and recovery
- storage network support
Longhorn is currently on v1.2.4. Anyone interested in the project can track its development in the GitHub repo.
Want details? Watch the videos!
Sheng Yang provides an overview of Longhorn at KubeCon Europe 2020.
David Ko highlights new features in Longhorn v1.2 at Rancher Online Meetup.
Further reading
- KubeEdge: Monitoring Edge Devices at the World’s Longest Sea Bridge
- Considerations for Running Stateful Apps on Kubernetes
- Enabling Persistent Storage for Docker and Kubernetes on Oracle Cloud
About the experts

Sheng Yang is Engineering Director at SUSE. He is responsible for Project Harvester and Project Longhorn. Sheng joined SUSE through the Rancher Labs acquisition, where he worked on Longhorn, Harvester, local path provisioner, and other projects. Before that, he worked on the CloudStack project and CloudPlatform product at Citrix. Sheng also spent a few years as a kernel developer at Intel, focused on KVM, Xen, and Linux kernel development.

David Ko is Senior Engineering Manager at SUSE. He has over 10 years of software development experience and is familiar with various technologies and techniques—including microservices, distributed system design, CI/CD, automation, DevOps, container orchestration, and cloud computing. David is also an expert at different programming languages, such as Go, Rust, Java, Python, Groovy, and TypeScript.





