
Cloud Native Buildpacks: Streamlining the Creation of Docker Images

Why the Cloud Native Buildpacks framework?
When deploying apps to Kubernetes or other container-as-a-service platforms, the proliferation of nonstandard, unauditable containers built manually via Dockerfiles is a real problem. A few products have emerged to solve this problem, among them Cloud Native Buildpacks (СNB). In this blog post, we explore the capabilities of these buildpacks and explain how to use them in build pipelines to deliver standardized, auditable images as artifacts suitable for deployment.
Why adopt a new tool when you are already producing images for your apps? Do your developers hate or aren’t able to write Dockerfiles? Would it thrill your operations team to manage and release a single kind of a deliverable? Does your security team grouse that images are sorely out of date? Buildpacks offer a way to ensure that images of a particular type (JVM, node, etc.) get built the same way, from the same base image, every time, without writing a single Dockerfile. Increasing the level of abstraction in the continuous integration/delivery (CI/CD) process to make a Docker image the basic functional unit makes the process simpler and easier to manage.

The Cloud Native Buildpacks framework represents the evolution of Heroku and Pivotal Cloud Foundry (now, VMware Tanzu) buildpacks into a public, cross-platform build tool serving major modern language ecosystems. With a Dockerhub style registry and deep customization of the build stack possible, dockerizing apps has never been easier.
At its core, the framework is an additional abstraction on top of Docker images. Just as the introduction of images increased the basic software unit from an app executable to a complete, reusable execution environment, buildpacks up the abstraction from an individually crafted image to a process that creates all the images necessary. This is the same sort of step up in process: the automated generation of many consumables from a few specifications. Later on, we’ll explore an example to understand how everything works.
The challenges of manually creating Dockerfiles
Cloud-first, containerized apps are the new industry standard. Of course, this means images containing apps. Is it worth investing time and money adopting a new process and tool? Very likely. Consider some of the common problems with development teams manually writing Dockerfiles:
- Base images and framework components can vary among teams and over time.
- Nonreproducible builds (
RUN apt-get install …orFROM node:latest) will yield different results over time, opening the possibility of introducing silent, and likely breaking, third-party changes. - An operations concern—the creation of infrastructure hosting apps—bleeds into the development realm.
- Security updates in the underlying image or framework components must be done manually, and entire images have to be rebuilt and deployed.
- It’s very difficult to standardize and reuse base images. An organization must home-roll the entire process.
- Images with very few or very many layers are difficult to analyze and audit.
- There comes inevitable human error when writing many Dockerfiles manually.
The Cloud Native Buildpacks framework addresses all of these by creating a standardized, automatable process. Buildpacks are to images as Helm charts are to deployments. Here are some pros that buildpacks bring to the table:
- Remove image maintenance from developers and correctly place it under operations
- Reduce or eliminate the need to write custom Dockerfiles
- Improve frequency of security updates to underlying components or dependencies
- Infrastructure- and tooling-agnostic
- Standardize and automate images as the deliverable
However, there also comes some level of complexity through:
- Introduction of additional tools and possibly external dependencies.
- Potential loss of build idempotency if using buildpacks with nonspecific tags.
- Potential increase of clock time for builds if appropriate caching is not used.
- Cleanly putting the entire image life cycle under operations requires intermediary storage to hold app artifacts.
- Image layers are timestamped with a fixed, incorrect date to facilitate reproducibility.
How it works
Getting started with buildpacks is incredibly easy:
- Install Docker and log in
- Install the pack CLI tool
- From the root of your repository, run
pack build DockerUser/MyImage --builder paketobuildpacks/builder:full --publish
That’s it! You should see a new image pushed to your Docker Hub account. If you run it, you’ll have a containerized version of your app ready to go. But what’s actually happening?
Cloud Native Buildpacks have the following components:
- Buildpacks represent the fundamental unit of work. This is what performs the operations of building and packaging of source code or artifacts into a Docker image.
- Stacks are the underlying environment. This is what defines the execution environment for the buildpack and the base image for the final result.
- Builders are the combination of one or more stacks and buildpacks. This is where the framework configuration and processing definition live.
Of course, you can create, configure, and publish custom components of all three types. The depth of configuration options means that even a large enterprise with substantial process and standard requirements can leverage buildpacks successfully.
Now, let’s move on to the key features of buildpacks.
- A buildpack can automatically detect if it applies to the source. For example, a Maven buildpack will look for a pom.xml or a built .jar file. If the detection fails, the pack won’t run. This means that running an invalid buildpack against a repository can be treated as a no-op.
- A single builder can contain multiple stacks and buildpacks. It also can be configured with a particular order of operations for applying buildpacks. This means a single builder can service all types of deliverables for an entire organization, and that all the deliverables can be based on the same underlying image.
- Building an image automatically creates a detailed Bill-of-Materials that specifies its metadata, buildpacks used, and the processes it will run. Combined with the robust logs produced at build time, debugging and security auditing greatly improve.
- All three components are themselves Docker images. This means that the operations team can manage and serve both the build infrastructure and production deliverables with the same process.
- All three components offer highly granular configuration options, and the ability to control each layer of the resulting image. Combined with robust caching and rebasing, this means a common, customized image can be reused for multiple apps, and each layer updated in isolation as necessary.
- The framework is not coupled to any particular type of infrastructure other than images (it is both Docker- and OCI-compliant). This means both it and the output images are infrastructure-agnostic.
- Support for building containers inside a Kubernetes environment via kpack. Docker in Docker can be frustrating at times, but hosting your CI environment on Kubernetes is no problem for the framework.
Sounds complicated? It can be, given the depth of the framework. However, because Cloud Native Buildpacks represent a high level of abstraction, complexity isn’t a requirement. For those who want an easy, off-the-shelf solution, Paketo maintains a set of buildpacks and builders for public use, covering major ecosystems. As the framework components are themselves images, this means adoption can be as easy as a single extra line of CI code.
The process ownership
The critical question around adopting buildpacks as a process is, who owns it? Meaning, which team is responsible for defining the buildpack components involved and ensuring generation of the final application executes successfully? There are two potential choices: development and operations ownership.
The development team owns building and maintaining app images. This is how many organizations operate today, so the buildpack framework can simply be dropped in as a replacement for Dockerfiles. While doing so represents the least disruptive change, or a good first step, many of the benefits of the buildpack framework are still missing.
Here, we see that the development team still must understand working with images, and manually ensure compliance with standards, such as using the correct stack or builder.
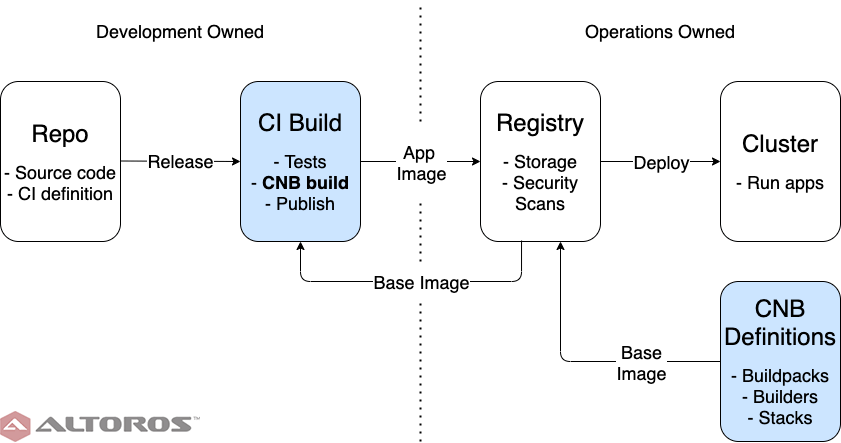 The image-building process owned by the development team
The image-building process owned by the development teamAdditionally, because operations is downstream from development, this introduces a cycle in the process. A change in, say, the base image for apps requires running development pipelines even if no source code has changed. Moreover, this will need to be a manual process, as the pipelines have no way of knowing an external dependency needs updating.
Moving the responsibility for constructing images under operations eliminates the dependency cycle from the process. It may seem that development concerns are now leaking into the operations realm, but the ability of the framework to automatically detect and apply the correct buildpacks means that the entire image-building process is application-agnostic. While a new base image will always necessitate rebuilding app images, now this process can be handled entirely by a single team, with no interruption to development. Separating app deliverables from the final images also allows for finer grained security analysis and debugging: if a new vulnerability or bug appears in the image registry, but not the app artifact registry, then it must come from the image-building process.
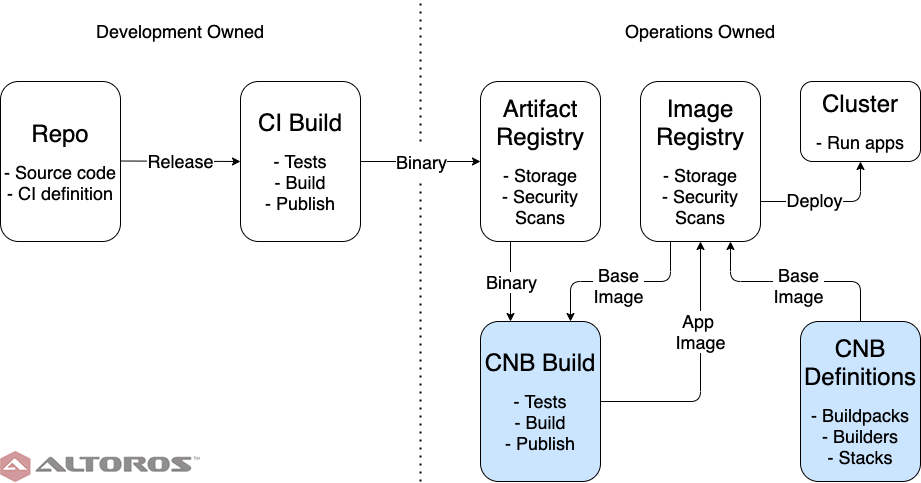 The image-building process owned by the operations team
The image-building process owned by the operations team
An end-to-end example
Try it out! In this GitHub repo, we have a fully functional demo, containing a “Hello, World!” Java API, built by the Spring Boot Guides and using GitHub Actions CI to build and publish an image. Start the repo to trigger the CI pipeline, which publishes to Docker Hub. Start the app with docker run -d -p 8080:8080 altorosdev/cn-buildpacks-example, then GET http://localhost:8080/ to see Greetings from Spring Boot!
The build definition in /.github/workflows/workflow.yml has two workflows designed to represent the two different ownership strategies:
dev-owned. The application and buildpack process live in the same repository and run in the same pipeline. The developers own the buildpack process. This approach may be faster to set up, but leaks operations responsibilities into development teams. The process can be broken into five steps:checkoutclones the repository into the build environment.setup-packadds the CNB CLI tool to the build environment.testruns the unit tests.loginlogs into Docker Hub.publishperforms a build and pushes the app image to Docker Hub. This command builds the image directly from the source code.
ops-owned. The app and buildpack logic are cleanly separated. Development CI pushes app binaries to an artifact storage layer owned by operations. Operations CI performs the build. This requires an additional layer, but cleanly separates responsibilities. Development CI has the same steps asdev-ownedfor building and testing the code. However, theupload-artifactcommand is used to publish the .jar file to the artifact storage layer. Operations CI has the following steps:setup-packadds the CNB CLI tool to the build environment.download-artifactpulls the app’s .jar from the artifact storage layer.loginlogs in to Docker Hub.publishperforms the build and pushes the app image to Docker Hub. This command builds the image from the .jar file.
Note that the setup-pack action is officially supported. You can see examples for the same CI processes, but on other infrastructure types in the /ci-examples folder. These run on the official pack Docker image.
There is also a bunch of other examples:
- The official Cloud Native Buildpacks template from GitLab.
- Heroku, Cloud Foundry, and Tanzu Application Service support the original PCF buildpacks concept. This is the parent of the Cloud Native Buildpacks framework, but sadly the two are not compatible, though Heroku buildpacks have a conversion utility.
- VMware’s Tanzu cloud platform boasts first-party integration with Cloud Native Buildpacks, including the Paketo builders. It also offers some nice additional syntax sugar and audit tracking for working directly from source in a Git repository, such as specifying tags and commits.
- Spring Boot offers Cloud Native Buildpacks as a first-party feature since version 2.3, configurable directly in the pom.xml file. This offers a great deal of convenience, for the tradeoff of losing the clean separation of development and operations concerns.
- Google Cloud Provider offers the comparable functionality, though as a separate product, called Jib. A great choice for those committed to the Google Cloud Platform ecosystem, but at the cost of vendor lock-in and, at the moment, only working for Java Virtual Machine apps.
Cloud Native Buildpacks represent a major step forward in modern software development. Adoption for the simple scenarios is easy, and the benefits are immediate. While large organizations will need to put effort into retooling CI/CD processes or writing custom builders, the long-term savings in time and maintenance effort are a compelling value proposition.
More in this series
- Cloud Native Buildpacks: How to Create a Custom Buildpack
- Cloud Native Buildpacks: Creating a Stack for Custom Components
- Cloud Native Buildpacks: How to Create a Custom Builder




