Metadata and Data Virtualization Explained

Why metadata?
Metadata unfolds the definitions, meaning, origin, and rules of the information used in a data warehouse. When talking about metadata, it is important to keep in mind that there are two types of metadata involved in the data integration process: business and technical ones. These two types illustrate both business and technical approaches to data integration.
The first type of metadata stores business-critical definitions of information. It contains high-level definitions of all the fields present in a data warehouse. Business metadata is mainly used by report authors, data managers, testers, and analysts.
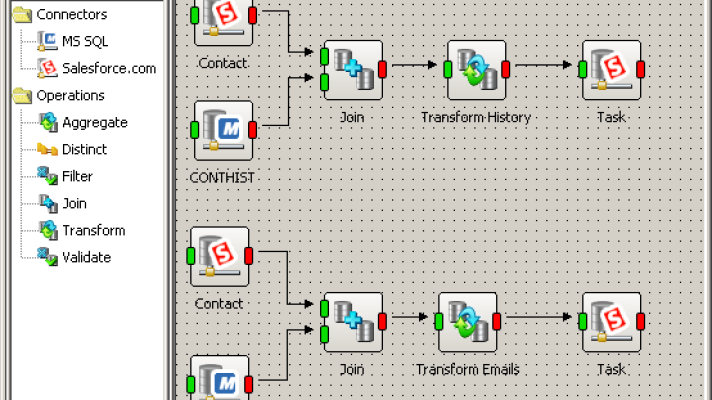
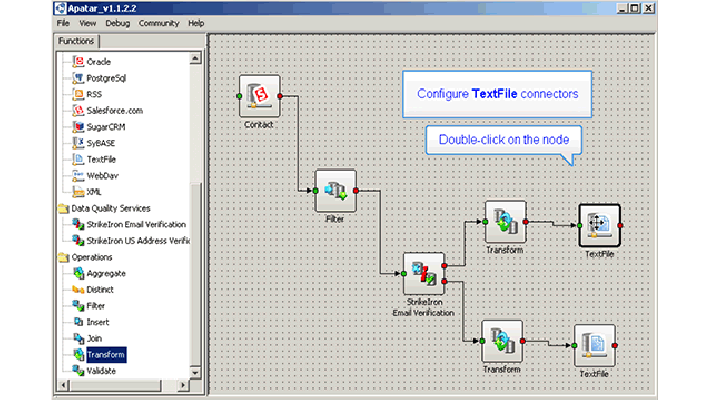
Technical metadata is a representation of the ETL process. It stores data mapping and transformations from source systems to the target and is mostly used by data integration experts and ETL developers.
There is also operational metadata, which describes information from operational systems and runtime environments (read more about all the three categories in this book).
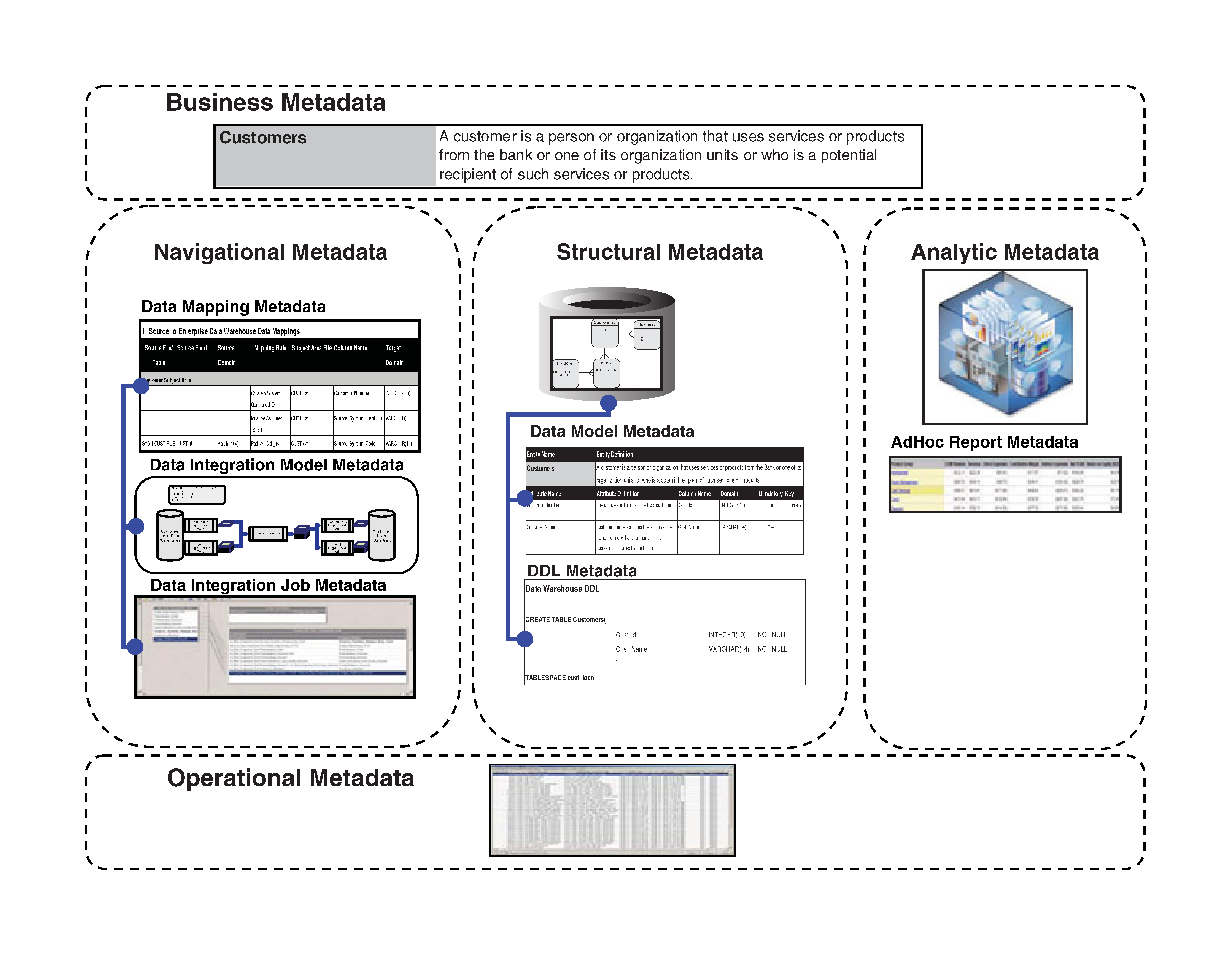 The relationships in the categories of metadata (image credit)
The relationships in the categories of metadata (image credit)Metadata management projects require a certain amount of customization. So, some of the ETL tools take that need into consideration, offering means to extend functionality and provide metadata integration. Still, the metadata needs of enterprises are so diverse that trying to create a one-size-fits-all solution is kind of impossible.
From metadata to data virtualization
Data virtualization is a method of data integration that enables to consolidate information—contained within a variety of databases—in a single virtual warehouse. The process of data virtualization is tightly coupled with metadata and includes four major steps:
- Organizing software interfaces to understand the structure of data sources and their level of security.
- Bringing these data structures to a single data integration solution for viewing and administration.
- Establishing a true metadata abstraction layer, which can be used for data organization, data management, data quality control, etc.
- Synchronize the data across the various sources.
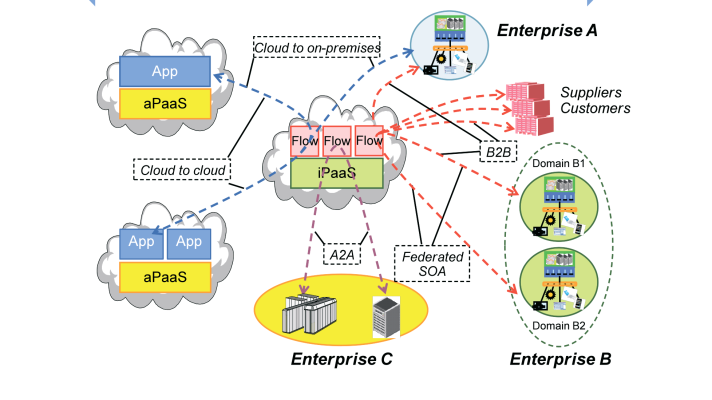
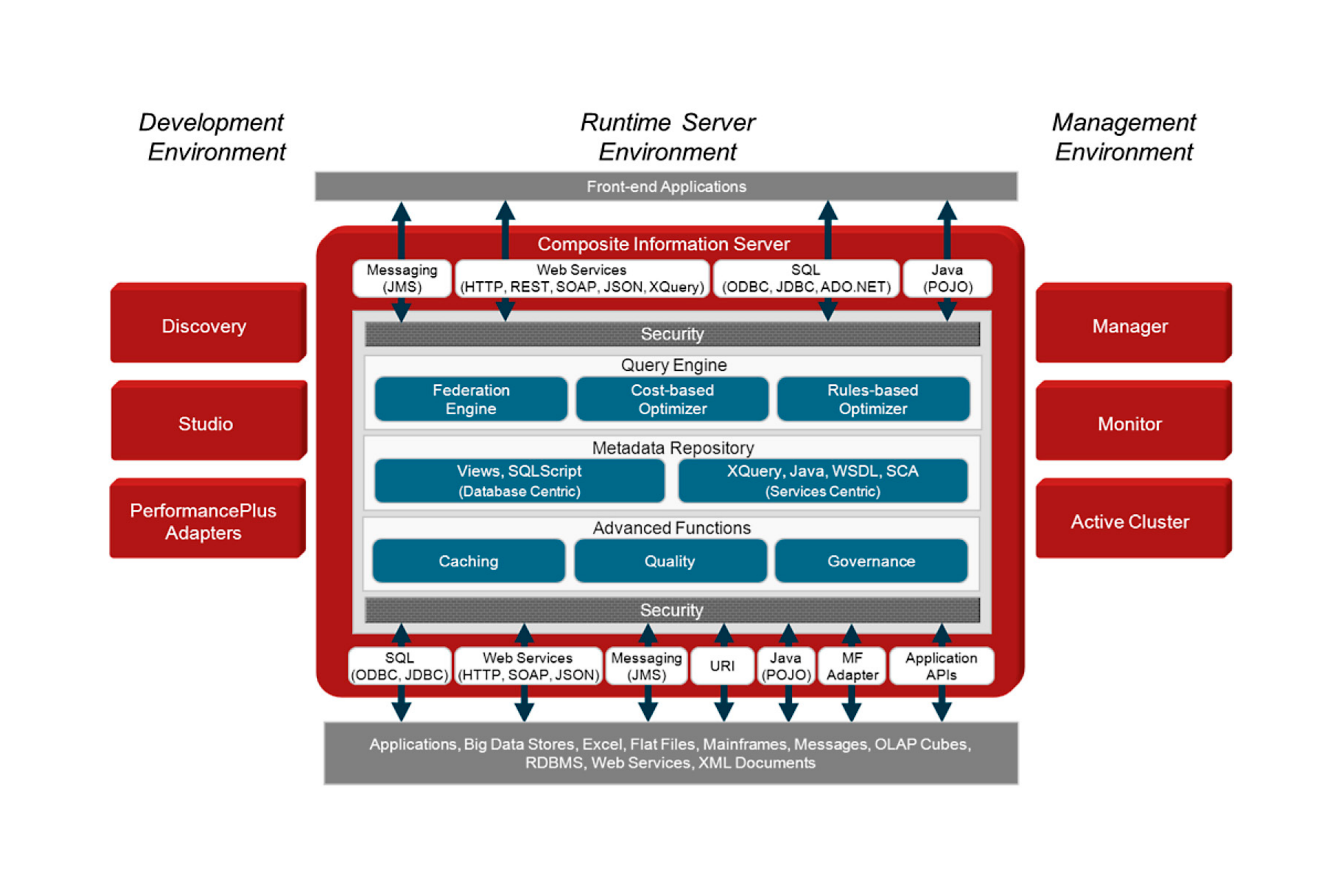 An architecture of a composite data virtualization platform (image credit)
An architecture of a composite data virtualization platform (image credit)This approach enables to combine and uniform various data sources without actually migrating the physical information. This also provides many other business benefits, including:
- Lower costs for physical and virtual data integration.
- Maximized agility by avoiding data movement, promoting reuse and ensuring data quality.
- Improved security by utilizing an abstraction layer to minimize the impact of change.
- Making the data available to various consuming applications: CRM, ERP, cloud computing platforms, etc.
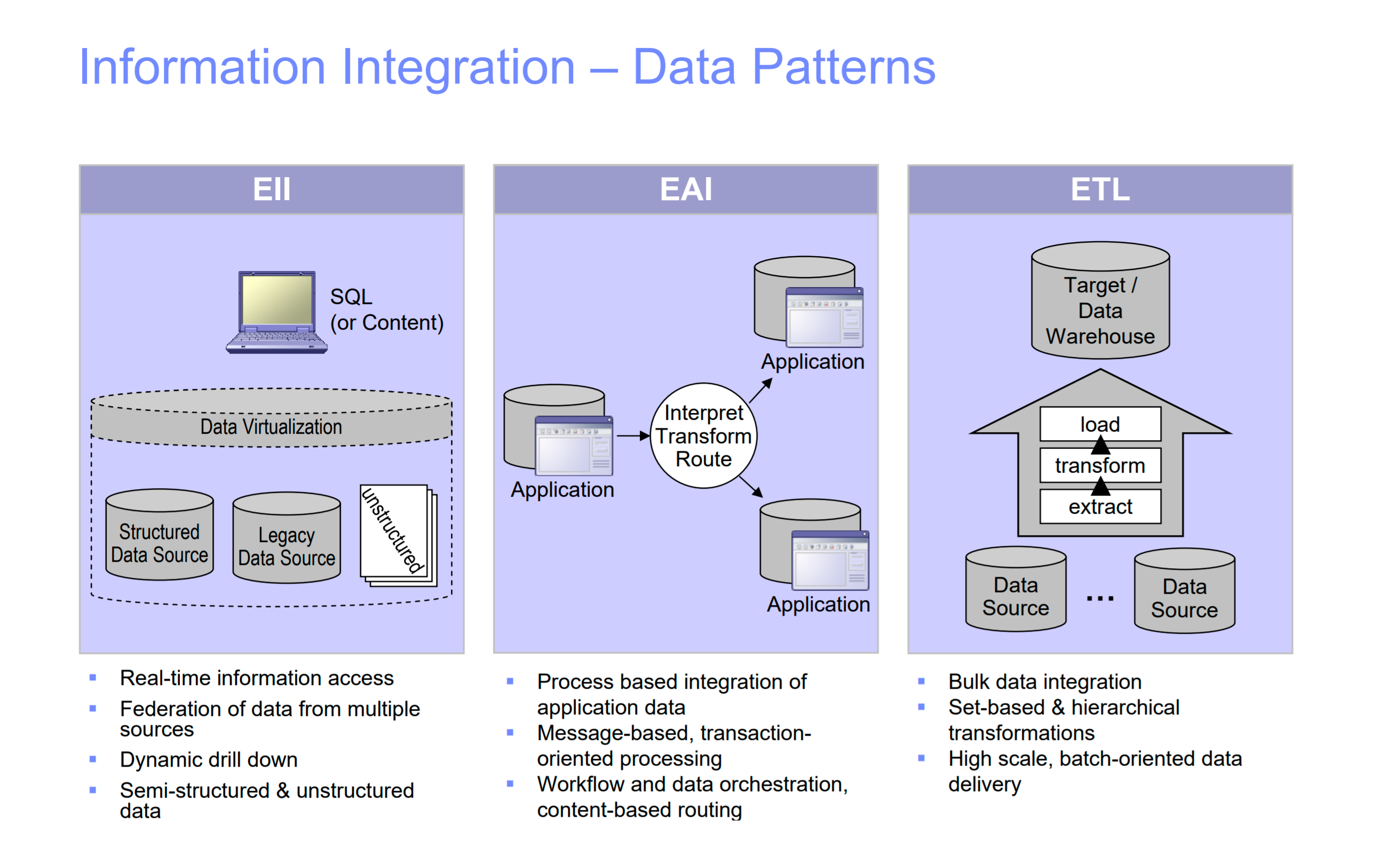 Image credit: IBM
Image credit: IBMThis positions data virtualization as a powerful method of information integration, which helps to seamlessly blend on-premises applications and various cloud architectures without the need to rewrite or migrate legacy systems. This tremendously simplifies the issues associated with data integration and ongoing data management.
Further reading
- 5 Things to Watch Out for in Data Warehousing
- Open-Source Data Warehousing: Pros and Cons
- Data Federation vs. Data Warehousing vs. Data Integration