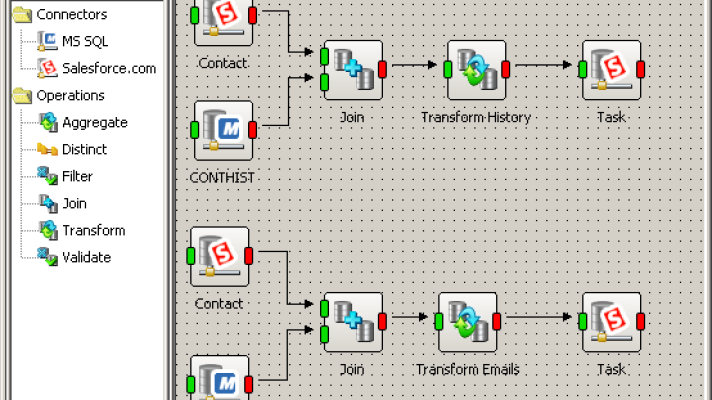
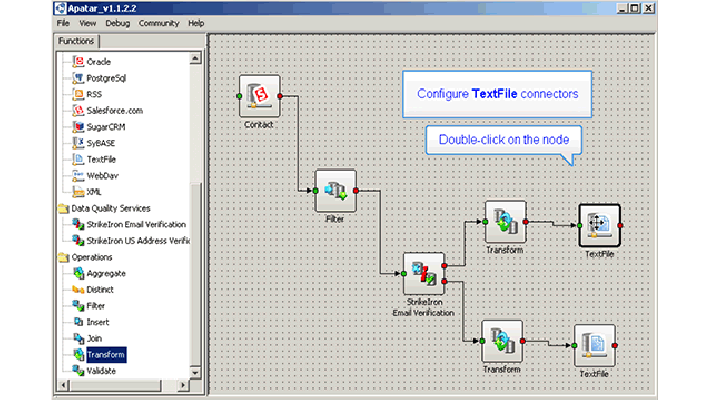
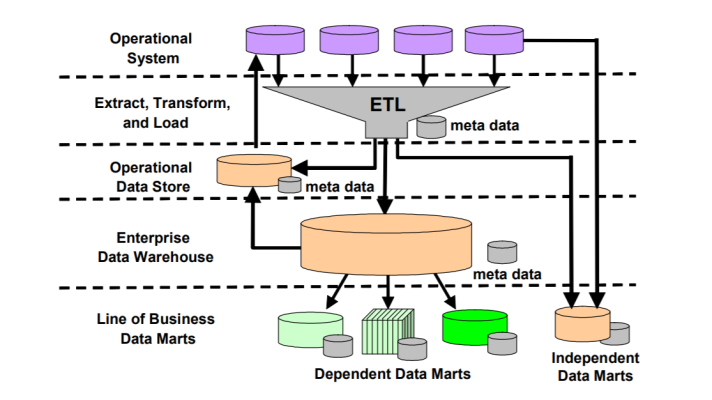
Data Federation vs. Data Warehousing vs. Data Integration

A single view of data without moving it
Data federation can be understood as an approach to joining information from different sources—distributed around the company—without actually moving it from the original source. That is to say, data federation software creates a single repository that doesn’t contain the data itself, rather its metadata (information about the actual data/its location). This technology allows users to have a single standardized view of data displayed in a single data layer without having to deal with the variety of original data sources.
Simply said, it enables a single virtual view of enterprise information across multiple data repositories, without the need to move or copy data. While an ETL tool moves data into a single repository, the virtual database created by a data federation technology doesn’t contain the data itself. Instead, it contains information about the actual data and its location. When a user wants to access the data, he or she sends a query specifying the needed information, and the federation server immediately delivers it as a virtual, integrated view.
This approach to integration is especially useful if company’s data is stored by a third-party cloud service provider. It allows business analysts to aggregate and organize data quickly without having to synchronize or to copy it. As an ETL alternative, data federation is also helpful when a user needs quick reporting. Additionally, data federation technology can be used to save the cost of creating a permanent, physical relational database.
The disadvantage of data federation, however, is actually one of its strengths: it prevents data from being changed. This feature is great for retaining historical accuracy, but awkward for companies looking to continually update their data.
Enterprise data warehousing

James Kobielus
James Kobielus in his ZDNet article explores the core difference between the enterprise data warehousing (EDW) and data federation. To some extent, data federation may generally seem outdated, compared to data warehousing, which at first looks like a more reasonable approach:
Federated environments are not optimized for heavy-hitting data matching, merging, transformation, and cleansing, all of which are essential functions to deliver a “single version of the truth” for business intelligence (BI).
However, James also lists the benefits data federation may deliver in the company’s overall business intelligence strategy:
Data federation is an umbrella term for a wide range of operational BI topologies that provide decentralized, on-demand alternatives to the centralized, batch-oriented architectures characteristic of traditional EDW environments.
In the real world, data federation and EDW are not that mutually exclusive, and may very well target different markets, as data federation is better suited to near-real-time BI requirements than the batch-oriented EDWs deployed in many organizations.
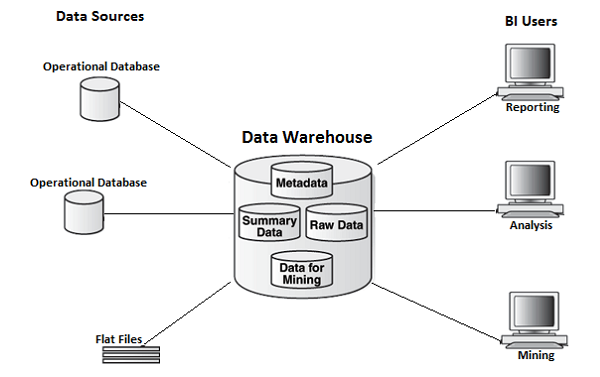 An example of a data warehouse (Image credit)
An example of a data warehouse (Image credit)
Data migration and synchronization
So, where do data integration activities, such as migration or synchronization, fit in the picture? Certain aspects of data integration intersect with both of the approaches discussed above. On the one hand, copying and moving data is an integral part of data warehousing. On the other hand, for data federation, you still apply some (smaller) data integration efforts to aggregate/unify metadata (for federated DBs) or combine reports (for federated BI).
By the way, last week, Gartner issued its Magic Quadrant for Data Integration Tools, which you can preview over here.
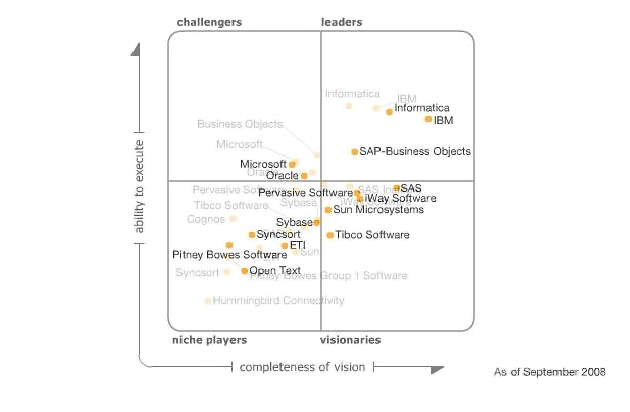 Gartner Magic Quadrant for Data Integration Tools, 2008 (Image credit)
Gartner Magic Quadrant for Data Integration Tools, 2008 (Image credit)We’re glad to see Apatar mentioned in the report (“focused on ETL and data federation scenarios“), although we wouldn’t quite call it a data federation tool. Actually, it can be used for all of the three scenarios described in this article. First, its ETL engine can serve as a basis for the migration or synchronization of data; second, one can utilize the product to improve the quality of information before it enters a data warehouse; and, third, you can use this tool as a query engine to filter and extract source data for reporting. However, you will still need a BI platform for your “federated” scenario.
Updated. A year after this article was published, in September 2009, CRM MVP David Jennaway published a great post on MSDN exploring these three concepts for Microsoft Dynamics CRM reporting.

David Jennaway
In his article, David mentions pros and cons of moving data against creating a federated view. For instance, according to David, it is easier/faster/cheaper to implement a federated report, rather then integrate all the data together and unify it. At the same time, when you move data, you gain more control over it—e.g., having an option to edit the information, if necessary. Hovewer, this increases the complexity and cost of your data integration. Besides, security is ensured better when managed in each source system separately, yet this requires granting access to more users.
“Designing a report is normally significantly less effort than building a robust process to copy data. The data displayed is always up to date, as it comes directly from the source system. Most data duplication processes have some latency within them, which may or may not be significant.” —David Jennaway
Nevertheless, these advantages are mostly relevant to BI/reporting, while in many cases you will still need a robust data warehouse with a single version of data (or master data) vital for your business operations. So, the evaluation of data federation vs. warehousing vs. migration should be based on a particular business scenario or requirement.
Further reading
- Top Data Integration Challenges: Meet DQ, CDI, EAI, DW, and BI
- Moving Apps to the Cloud: Solving Data Integration Issues
- What’s the Difference Between Data Conversion and Data Migration?
with contributions from Katherine Vasilega and Olga Belokurskaya.