
Automating Event-Based Continuous Delivery on Kubernetes with keptn

Issues with manually built pipelines
Delivery pipelines are designed to automate the roll out of new features and updates. In theory, such pipelines are useful in minimizing the amount of manual work needed to release or maintain software. However, in practice, there are multiple problems associated with delivery pipelines, as most companies build them manually and ad hoc:

Jürgen Etzlstorfer
- Over time, pipelines become complicated because of mixed information about processes, target platforms, environments, tools, etc.
- Due to code being spread across different tools, low maintainability occurs.
- There is no clear separation of concerns, as users with various roles (such as developers, DevOps experts, and site reliability engineers) employ the pipeline for different purposes.
During a Kubernetes meetup last December, Jürgen Etzlstorfer of Dynatrace highlighted the above-mentioned issues and explained how keptn can help. In addition, he focused on the importance of smooth integration of components for CI/CD.
Building stable event-based pipelines
“When building a pipeline, we often can come up with a smartphone that’s not very smart,” said Jürgen. “It can do everything that you want to do, but you have very fragile integrations, and, at the very end, you do not want to touch it anymore.” Therefore, to improve the stability of the whole pipeline, it is critical to provide stability on the integration points.
“We want to have all the functionality, but we want to have it on this very stable platform. We want to have nice integration points, where it is easier to manage the delivery of great software.” —Jürgen Etzlstorfer, Dynatrace
Jürgen then introduced the keptn project aimed to help with automating CI/CD in Kubernetes deployments. It is an open-source event-based control plane for continuous delivery and automated operations across cloud-native applications.
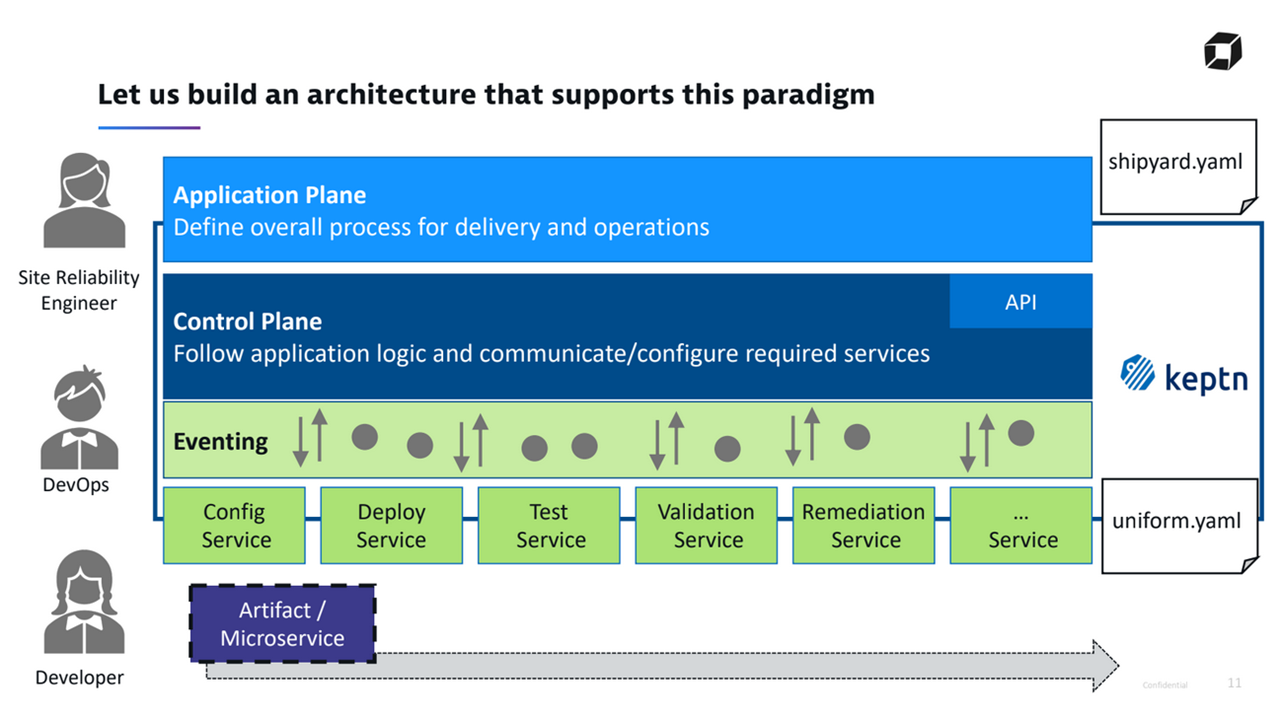 The keptn architecture (Image credit)
The keptn architecture (Image credit)In a nutshell, keptn enables users to:
- define app delivery and operations processes declaratively
- integrate and switch between different tools
- separate processes from the tools by using predefined
CloudEvents
How it works
According to Jürgen, keptn relies on specification (.yaml) files in order to determine how software is deployed. Shipyard.yaml specifies the stages and what happens in each of the stages. For instance, development, hardening, and production stages are described here. Uniform.yaml designates which services react to certain events. For example, the deploy-svc and performance-test services, as well as the events they listen to are described here.
 Examples of keptn specification files (Image credit)
Examples of keptn specification files (Image credit)By splitting the specifications, keptn provides a clear separation of concerns. Site reliability engineers can add new stages, while DevOps engineers can define the tools to be used for each new stage.
“There is a very clear separation, and everything can be updated individually. It is not so tightly coupled, so that you do not run into problems.” —Jürgen Etzlstorfer, Dynatrace
Additionally, keptn makes use of “quality gates.” According to Jürgen, these are executed after the testing phase. In his example, Jürgen explained how the Service Level Objective (SLO) qualifies the criteria for passing a service or issuing warnings to users.
 An example of an SLO configuration (Image credit)
An example of an SLO configuration (Image credit)The ketpn’s bridge provides an interface to browse all the events sent within the solution, as well as to filter events based on context. This bridge also monitors all the events and the resulting actions in order to provide real-time information tracing.
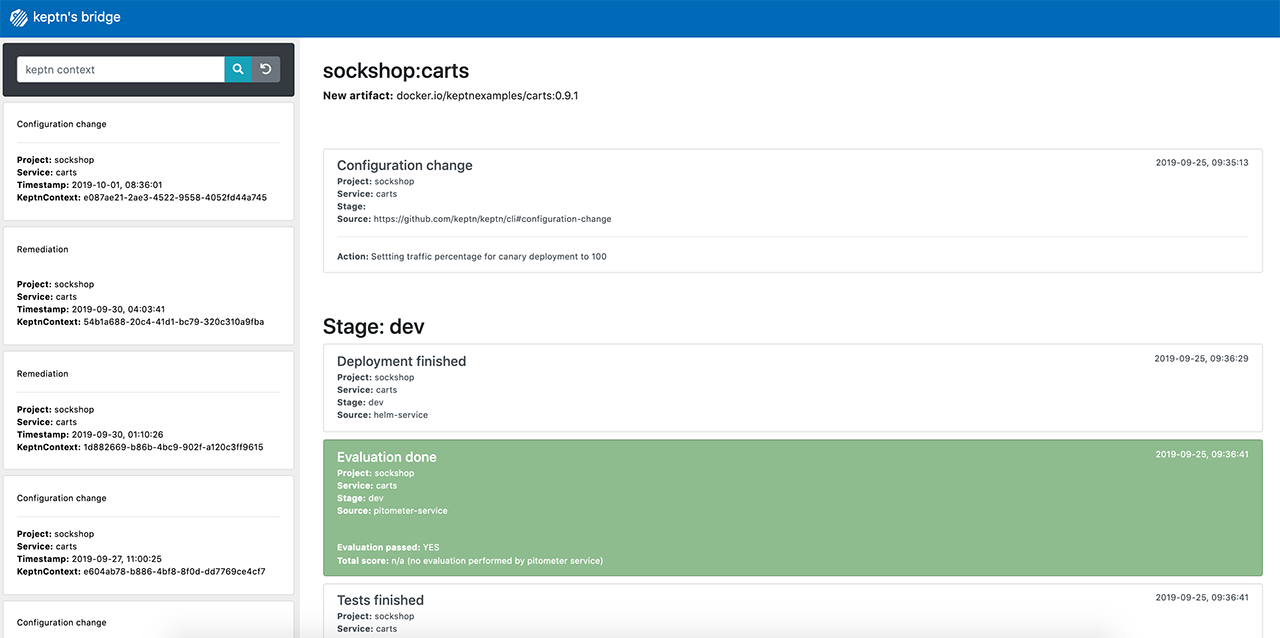 kept’s bridge enables browsing through events (Image credit)
kept’s bridge enables browsing through events (Image credit)
Sample workflow
To further understand keptn, Jürgen explained its workflow in order. The workflows begin once when the new-artifact event is sent either through the keptn’s API or CLI with the command below.
keptn send event new-artifact --project=sockshop --service=carts-db --image=mongo
The solution will then update its internal configuration, deploy the artifact, and update the environment. Following that, keptn will run tests and will validate each test with the quality gates. Based on the results from validation, the artifact will roll back or be kept for the next stage.
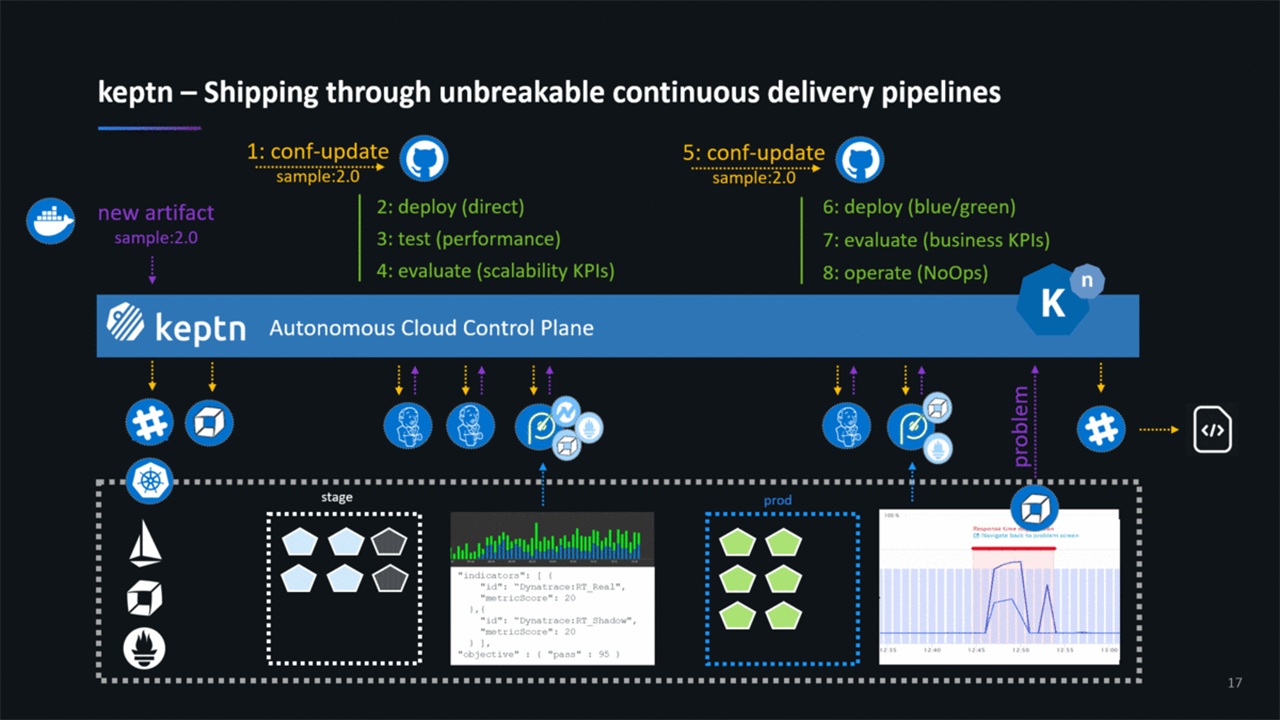 The keptn workflow (Image credit)
The keptn workflow (Image credit)In a scenario where a user needs to onboard or roll out a new artifact, one would push the image to a container registry, and this will inform keptn to start a new deployment. In response, the solution will update the internal Git repository and will begin deployment and testing in the user’s cluster. After that, keptn will reach out and fetch all the metrics from a monitoring provider.
Next, the system will update all the branches and move on to the next stage with a blue-green deployment. Once again, keptn will fetch metrics from a monitoring provider. Depending on the results, it will either pass or roll back, then notify a user.
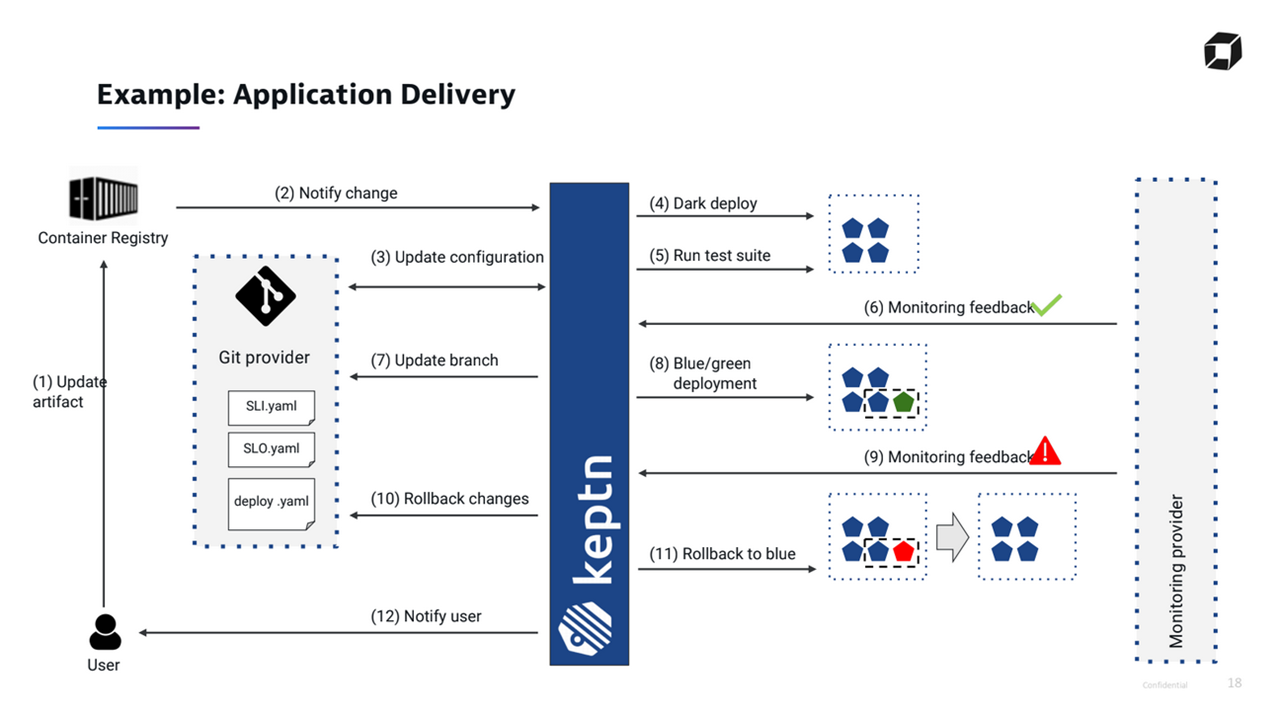 An example of application delivery using keptn (Image credit)
An example of application delivery using keptn (Image credit)Currently, keptn v0.6.0 is available, providing basic services needed for deploying an artifact to a Kubernetes cluster. These include configuration, deployment, testing, validation, and remediation services. keptn is also proposed as a CNCF (the Cloud Native Computing Foundation) sandbox project.
“You can always exchange the services in keptn. If you want to use a different tool for testing, you can unplug the existing service and plug in a different one. You do not need to change the whole process or the pipeline. You just have to change the service, and the rest stays the same.” —Jürgen Etzlstorfer, Dynatrace
keptn can be installed on top of the following Kubernetes distributions:
- Azure Kubernetes Engine
- Amazon Elastic Kubernetes Service
- Google Kuberentes Engine
- Red Hat OpenShift
- Pivotal Container Service
You can track the project’s development in its GitHub repository. Additional information, as well as tutorials are available at the keptn’s website.
Want details? Watch the videos!
In this video from the Kubernetes meetup (December 2019), Jürgen Etzlstorfer introduces keptn.
Below, you will find the slides presented by Jürgen.
In this video, Andreas Grabner and Dirk Wallerstorfer of Dynatrace overview keptn and explain how to get started with it.
Further reading
- Kubernetes Cluster Ops: Options for Configuration Management
- Rule-Driven Automation on Kubernetes with Autopilot Monitoring
- A Comparison of Kubernetes Сluster Monitoring Tools: Kube-prometheus, Elastic, and Zabbix
- A Comparative Analysis of Kubernetes Deployment Tools: Kubespray, kops, and conjure-up
About the expert





