
Using IBM Analytics for Apache Spark in Java/Scala Apps on Bluemix

spark-submit.sh script.Description of the Bluemix Spark starter

When exploring Bluemix data and analytics services, I didn’t find any starters or examples for how to use the IBM Apache Spark service. So, I decided to implement a simple starter on Scala and show how to work with the IBM service in Java/Scala applications.
My sample Bluemix Spark starter provides a simple solution for calculating the word count in a file. This file is stored in Swift Object Storage.
At first, I wanted to deploy the starter in a Cloud Foundry container and have access to the Spark cluster from this starter, but the API usage of the Spark cluster in the IBM Analytics for Apache Spark service is not supported yet. For now, you can only use it through the Notebook UI interactively or the spark-submit.sh script.
Preparing the starter for Bluemix
For running the Bluemix Spark starter, you need to create a new instance of the Apache Spark service from the Bluemix console. When setting up your Spark service instance, you can either create an Object Storage instance or connect to an existing Object Storage instance.
If you haven’t already, sign up for Bluemix. In the Bluemix console, launch the IBM Analytics for Apache Spark service. For doing this, find Apache Spark in the Data and Analytics section of the Bluemix catalog, open the service, and then click Create.
Next, you need to clone my repository and change the following properties for Swift Object Storage:
auth.url(is equal to theauth_urlproperty from the Swift Object Storage service credentials)username(is equal to theusernameproperty from the Swift Object Storage service credentials)passwordandapikey(both are equal to thepasswordproperty from the Swift Object Storage service credentials)region(is equal to theregionproperty from the Swift Object Storage service credentials)tenant(is equal to thetenant_idproperty from the Apache Spark service credentials)
To build an executable JAR file for bluemix-spark-starter, install Apache Maven and run the following command from the starter root:
1 | mvn clean, package |
After that, you can find the executable JAR file with the Spark job in the bluemix-spark-starter/target folder.
To run analytics with IBM Analytics for Apache Spark, you can use Jupyter notebooks or the spark-submit.sh script.
Using notebooks
From the bluemix.net website:
“Jupyter Notebooks are a web-based environment for interactive computing. You can run small pieces of code that process your data and immediately view the results of your computation. Notebooks record how you worked with data, so you can understand exactly what was done with the data, even if time has passed since the notebooks were created. This enables you to reproduce computations reliably and share your findings with others.”
To run your analytics application using notebooks, create a new Scala notebook in your existing Bluemix Apache Spark service instance.
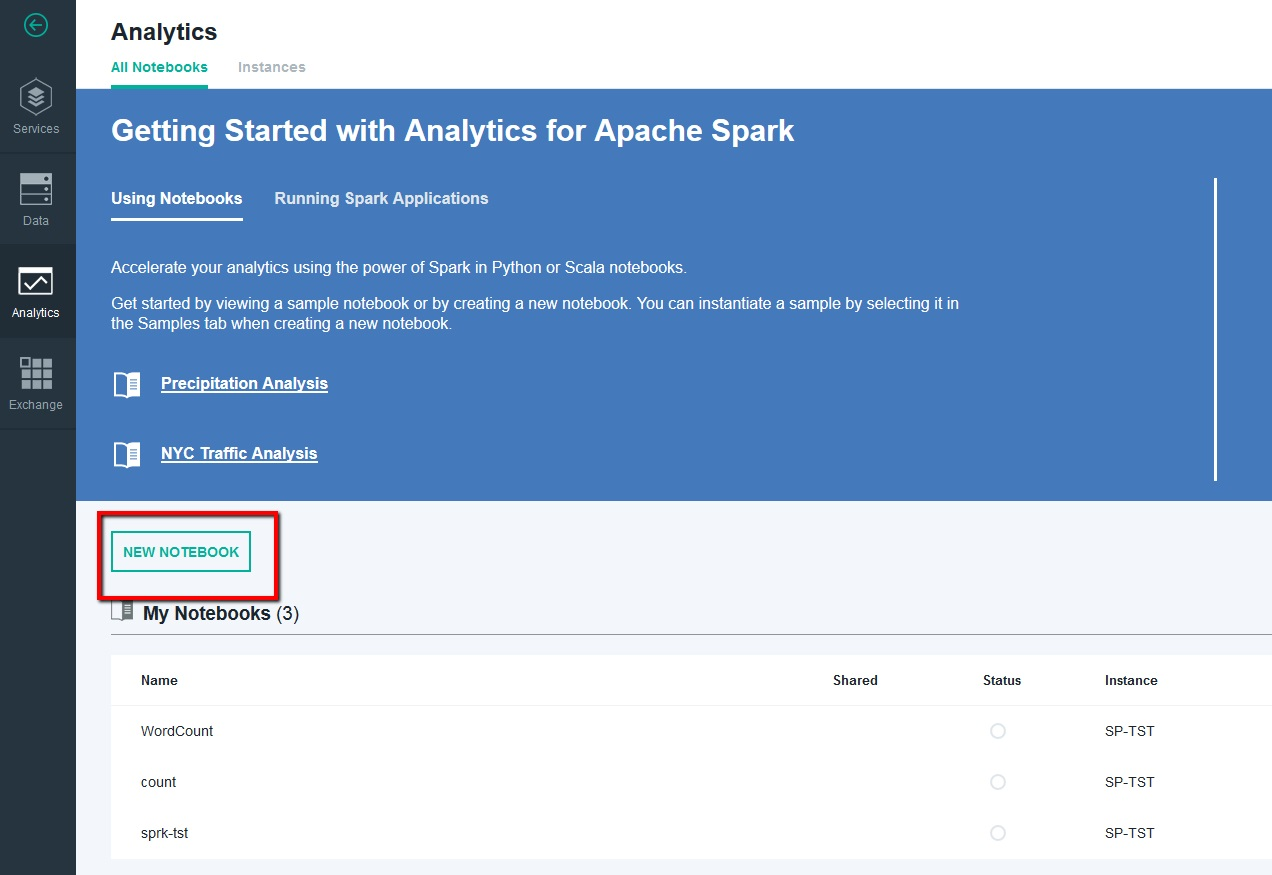
Run the AddJar command to upload the executable JAR file to the IBM Analytics for Spark service in the first cell.
For example:
1 | %AddJar https://github.com/SergeiSidorov/bluemix-spark-shell/raw/master/com.altoros.bluemix.spark-1.0-SNAPSHOT.jar -f |
As mentioned in this IBM article, the % sign before AddJar is a special command that is currently available but may be deprecated in an upcoming release. The -f flag forces the download even if the file is already in the cache.
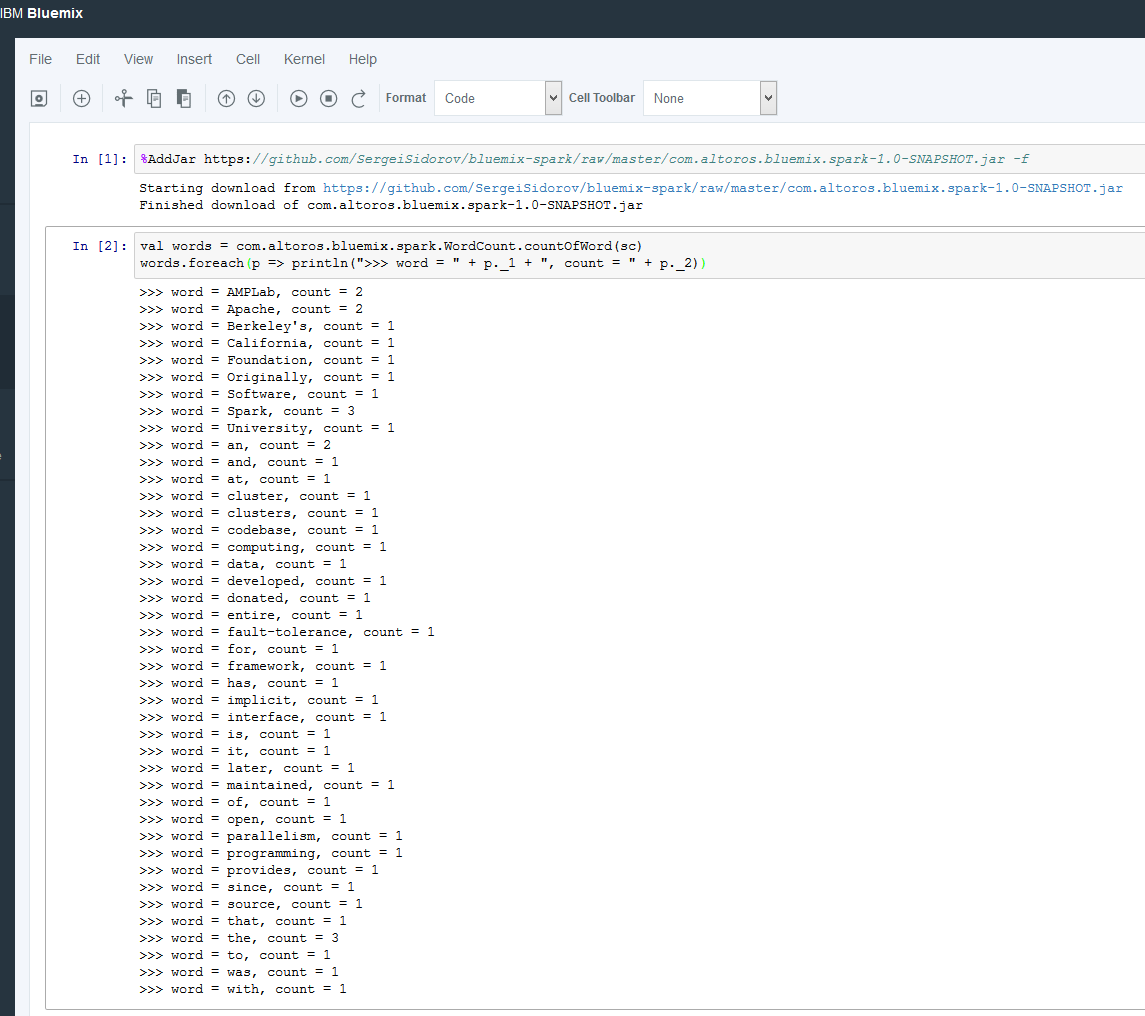
After you deploy the JAR file, you can call APIs from within the notebook.
For example, call functions from a notebook cell:
1 2 | val words = com.altoros.bluemix.spark.WordCount.countOfWord(sc) words.foreach(p => println(">>> word = " + p._1 + ", count = " + p._2)) |
Final results in your Bluemix Jupyter Notebook look similar to this:
Using the spark-submit.sh script
Description of spark-submit.sh from bluemix.net:
“—Runs the Apache Spark spark-submit command with the provided parameters.
—Uploads JAR files and the application JAR file to the Spark cluster.
—Submits a POST REST call to the Spark master with the path to the application file.
—Periodically checks the Spark master for job status.
—Downloads the job stdout and stderr files to your local file system.Restriction: Running the spark-submit.sh script is supported on Linux only.”
To use the spark-submit.sh script for running your Spark application, do the following:
- Create a folder where you plan to run the application and put the executable JAR file into this folder.
- Launch an instance of the IBM Analytics for Apache Spark service and use the credentials from the Service Credentials page.
Insert the Spark service credentials to the
vcap.jsonfile in the directory where you plan to run thespark-submit.shscript.Here is an example from Bluemix documentation:
12345678910{"credentials": {"tenant_id": "s1a9-7f40d9344b951f-42a9cf195d79","tenant_id_full": "b404510b-d17a-43d2-b1a9-7f40d9344b95_9c09a3cb-7178-43f9-9e1f-42a9cf195d79","cluster_master_url": "https://169.54.219.20:8443/","instance_id": "b404510b-d17a-43d2-b1a9-7f40d9344b95","tenant_secret": "8b2d72ad-8ac5-4927-a90c-9ca9edfad124","plan":"ibm.SparkService.PayGoPersonal"}}- Download the
spark-submit.shscript from this GitHub repository. Run the script.
For example:
123456./spark-submit.sh \--vcap ./vcap.json \--deploy-mode cluster \--class com.altoros.bluemix.spark.WordCount \--master https://169.54.219.20:8443 \com.altoros.bluemix.spark-1.0-SNAPSHOT.jar
Log files stdout and stderr are saved to your local file system. For more information about IBM Analytics for Apache Spark, see the service documentation.




