The Three Most Common Problems Faced During Data Migration

The data migration puzzle
According to Standish Group, 30% of data migration projects fail, while Bloor Research study found 84% of such migrations do not meet expectations. The problem often lies in making source data comply with target formats and standards, which requires a lot of time and effort on the developer’s side. Due to these and other data integration challenges, 75% of the leading companies are incapable of creating a unified view of a customer (Gartner).
As your business grows, requirements for your data storage change. At the same time, the IT market offers new, diverse software to catch up with or even get ahead of your needs. At a certain stage, you face the necessity of switching to a new system. However, migrating contact data or integrating customer history may take months of coding, lead to huge data losses, or simply fail.
What are the hidden problems related to data migration? How can you omit them and get the most out of your data integration initiative? This article explores these issues in detail, providing examples and recommendations to facilitate the migration process.
Issue #1. Understanding the new system’s capabilities
Studying the new system’s capabilities is an important step not just in preparing requirements for your data migration/integration project, but in selecting the system in the first place. You have to see that this system really does meet your requirements and will be able to satisfy your needs. You should make sure, not only that this new system has all the components and functions/capabilities you need, but also that it is convenient for you to work with these components and perform the actions you need to perform with your data.
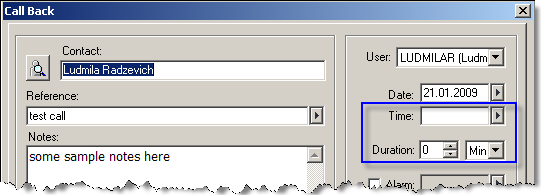
Let’s take Salesforce CRM and GoldMine, for example. Sometimes, when it comes to migrating contacts’ activity histories from GoldMine to Salesforce CRM, an important question is, which object to move data to: Events or Tasks.
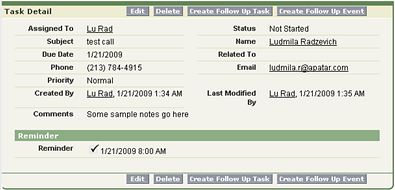 Salesforce CRM’s task detail
Salesforce CRM’s task detail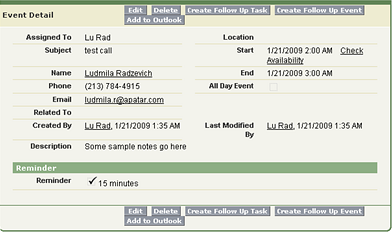 Salesforce CRM’s event detail
Salesforce CRM’s event detail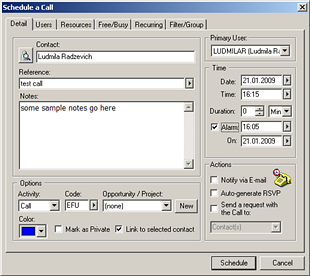 GoldMine activities
GoldMine activitiesAlso, for technical professionals it would be good to analyze how the new system communicates with other systems. A good import/export mechanism included in the new system is a useful feature, but it’s not always sufficient. So, it is important to study the system’s API or SOAP capabilities. While some such interfaces provide you with a great toolset for data integration, others have significant limitations, which means that there will be no easy way to migrate some types of information, so you will need to look for alternative integration methods, such as direct database access, if it is enabled by the system. This issue will definitely make the project more labor-intensive, time-consuming, and, as a result, more costly.
Issue #2. A clear vision of what should be moved and how
To save time when the project is started and to make sure no data is missed, it is very important to make a complete list of the data that should be migrated. You can either prepare screenshots with the fields you need highlighted in some way or you can prepare a list of fields. For the list of fields, it is important to also mention the object/table this field is related to, as there might be fields with the same name in different objects/tables. Having the complete list of fields to be migrated will actually help the service provider make their work estimates more accurate.
Example: Activities in GoldMine have fields, such as Activity (specifying the type of activity performed), Code, and Result whereas some other systems do not have such fields (though custom fields can be created to hold this data).
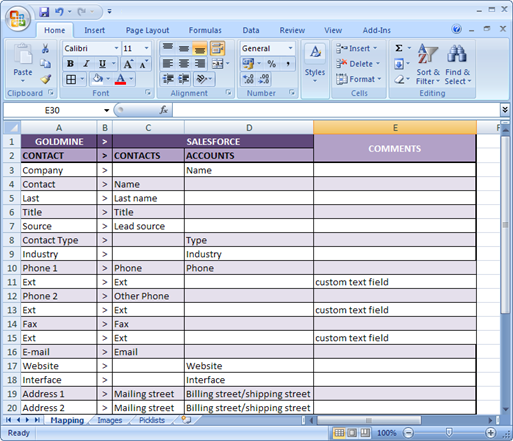 Creating a list of fields
Creating a list of fieldsThis leads us to the next point. When you have the list of fields to be migrated ready, check where they can go in your new system. And there are two aspects here:
Object-to-object relation
In your new system, there might be one or several objects that are pretty much equivalent and can hold the data you are migrating (like in the example with GoldMine activities and Salesforce CRM’s Tasks and Events above).
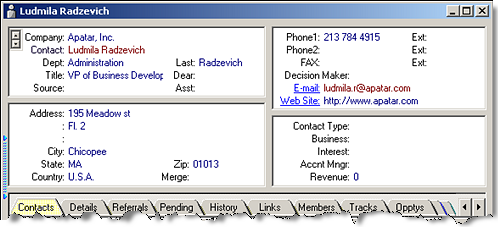 Contact detail
Contact detailAlso, there might be different objects in the new system that data from one object should be split into. For example, your current system has the Customer object that contains contact name, company, address, phone, e-mail, revenue, business type, etc. However, your new system has only two objects for this type of information: Account and Contact. You should think about which customer data goes to Accounts, which to Contact, and which can and should be presented in both objects. Here you need to remember that if you have several contacts that are related to the same company, the values in the fields that should be written to this company account may be different.
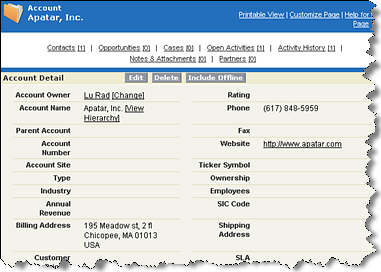 Account object
Account object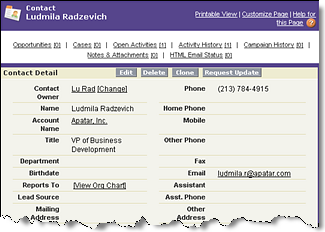 Contact object
Contact objectFor example, different customers related to the same company may have different addresses or revenues (e.g., one customer has been updated with new numbers, while another still has the old value). This means that if you take this information from customers and write it to a company’s Account, it might not be accurate.
Unless there is some business logic that can be added to the migration process that will be applicable to all customer records, options will need to be considered. One of them can be writing the company data that is 100% identical for all customers to the company’s Account and writing the rest to Contacts. Another option can be creating separate accounts based on each customer’s record. But this option will only make sense if your new system allows creating “duplicate” records (Accounts with the same account name in this case) and has a good duplicates merging mechanism, and of course, if you are sure that you only have a few customers related to the same company in your current system.
(Imagine that you have 20 contacts for some companies in your system and there are 20 accounts created for each of these companies. The effort you’d need to take to merge them wouldn’t be worth it.)
Field-to-field relation
While same type of systems (CRM or ERP, for example) offer a similar set of fields for each data object, they are never 100% the same. Compare the list of fields that you have selected for migration with the fields for related objects in your new system. Make sure that you are happy with the corresponding standard fields offered by the system. It is not just field names that you should pay attention to; field characteristics matter, as well. A field that you currently have as a picklist might be a text field, or an equivalent for a text field might be a numeric field in your new system and this might not be what you really need. Another thing to pay attention to is the field size. Your current system might allow a greater number of characters for a certain field compared to the new system, which means a workaround will need to be found so that you do not lose data when cropping it to match the size of the new field.
The best method is to go back to field types and define the names and types for the custom fields that need to be created to hold data from your current system. This way, you will not get into a situation where the processes or triggers that these custom fields are involved in—and that have already been set up—do not work; this will also prevent data loss due to poorly thought out field names or types. It is not that problems occur in 100% of the cases when you change the characteristics of a field that already has data in it, but the risk exists.
Another issue you may face is that you might need to split data currently stored in one field into a number of separate fields.
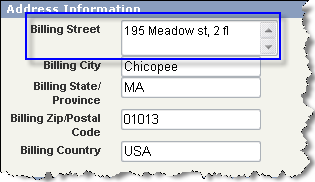 Data stored in one field
Data stored in one field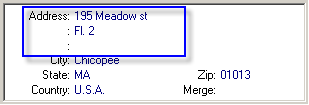 Splitting data into separate fields
Splitting data into separate fieldsLet’s take contact names, for example.
The full name is contained in one field and you need to break it down into first name, middle name, and last name. Errors are possible here during the migration because of the ways names are entered. A few sample values.
Mike M. Smith
Mike Smith
Smith, Mike
Mike Smith Jr.
Mike von Smith
For most of the options above, it is possible to set up the process to automatically split the name into several fields and in case of “Mike Smith Jr.” to write “Jr.” in the suffix field, for example. However, for the last option (Mike von Smith) there is a great chance that “von” will go to the middle name field. It might not seem to be a serious problem, however if you use some templates where you need to get the last name of a contact, you will not get the correct value.
Issue #3. The quality of data in your current system
Careful analysis of the quality of data in your current system should be done prior to migration. Good data can save quite a bit of time (and budget) during migration. In fact, this analysis and replacement set up during the migration will help you cleanse and improve your data. Outlined below are some key points to pay attention to.
Required fields
Many systems have fields that need to be filled in for records to be migrated. It is important that these key fields are filled in, such as company names for accounts, customer names for contacts, and so on.
 Key fields that should be filled in
Key fields that should be filled in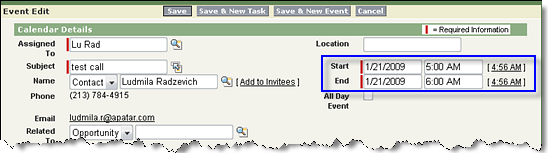 Required information is migrated
Required information is migratedIf you feel this information is missing, you need to think what values should be entered into these empty fields. It can be either one value for all empty fields or the values can be generated based on some other information. For example, you can fill in an empty contact name with something like “Company Name representative.” Or, for activities, if the activity date is empty, you can enter a specific date as a placeholder by which you can then find these activities and have your system users fill in those dates.
The key factor here is to make it convenient for you to use the data when it is migrated.
Data type transformations
Data type conversion might also be required when you migrate your data. It is important that the values entered in the fields to be converted in your current system meet the requirements of your new data type. We did mention field size issues earlier. Other examples here are: transferring text field to numeric (phone extensions, etc.); date contained in a text field to a date field; text to picklists; and others.
The issue with picklists is that they normally accept only the values that are there in the dropdown for this field in your new system. You would need to analyze the values contained in the fields that are to be transferred to picklists to make sure you have all the values in the new system and there is no conflict during the migration. The most common problem here is logical duplicates that are presented in different ways in the field. For example, you might want to have “white paper” as a value on the list, but in your current system there also are “WP,” “whitepaper,” and “white papre.” If it is not possible to replace these with “white paper” automatically in your current system, you will need to add these replacements within the data transformation to be built for the project.
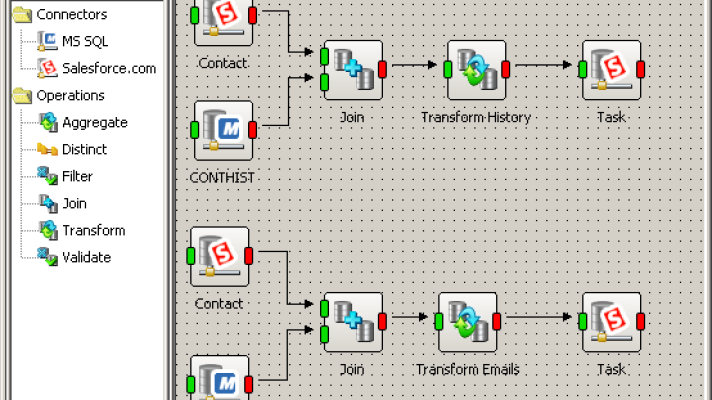
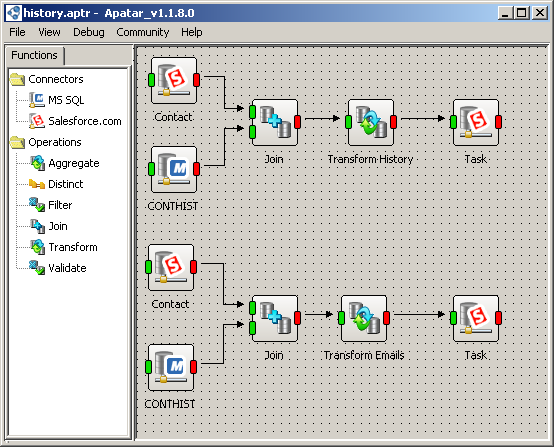 Migrating History from GoldMine to Salesforce CRM with Apatar
Migrating History from GoldMine to Salesforce CRM with Apatar
Data uniformity and typos
This aspect is important both to ensure that all the data is migrated correctly and to omit creating duplicate records. A simple example of why duplicates can be created would be a difference in the way the name of the same company is entered for different contacts. Logically, “Apatar,” “Apatar Inc.,” and “Apatar, Inc.” are the same company, but for an application these values are not the same; so after the migration you will have three different Account records instead of one.
The quality of the data is also important when you convert data types, for example, text to checkboxes or radio buttons (Booleans), joining date and time fields to a field that contains both (timestamp/date and time), etc. The latter would require both date and time fields to be filled in.
Some systems verify the data that is entered into fields. For example, Salesforce CRM checks the format of entries in the Email field. If you have values in your data source that are not properly formatted e-mails, (“info @apatar.com,” “infoapatar.com,” or “info@apatar.com, support@apatar.com.”), the Email field for the record with invalid e-mail format or the entire record will not be migrated.
Afterword
When the migration is completed, make sure to double-check the results. Select at least one record that has most of the data filled in and a few records that have some data that required some workarounds or replacements set during the migration and make sure everything has been migrated correctly.
If the data was migrated from a system that your team members have been working with while the data was being migrated, make sure that new data has also been migrated and the latest changes are also reflected in your new system.
For more, check out how Apatar Open Source Data Integration can help.