Identifying Cancer Faster with Distributed TensorFlow on OpenPOWER

Medical analysis with deep learning and HPC
At IBM Edge 2016 in Las Vegas, a use case featured possible cancer detection with a machine learning solution analysing images of lymph nodes. Relying on a distributed model of TensorFlow and high-performing nature of the OpenPOWER infrastructure, the demonstrated system could accelerate medical data analysis.

Andrei Yurkevich
The particular subjects of the research were how training time decreases when the cluster grows and whether the accuracy of the results is affected by the distributed nature of TensorFlow computations.
Andrei Yurkevich of Altoros and Indrajit Poddar of IBM led this study, investigating the possibility of image analysis acceleration by using high-performance computing (HPC) and varying the number of GPUs and nodes in a cluster.

Indrajit Poddar
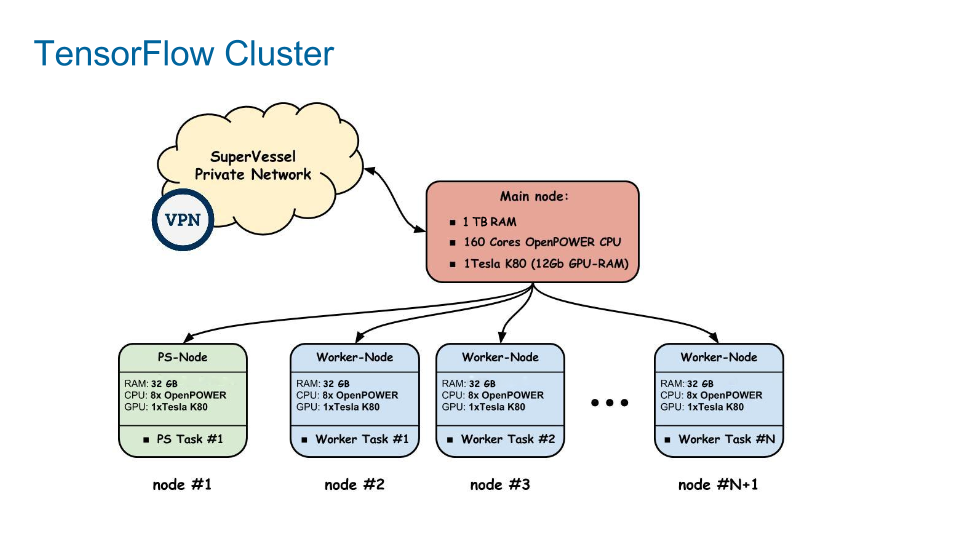
The model was trained on multiple Docker nodes running on OpenPOWER servers equipped with GPUs.
The study used 100,000 images to train the model and test its accuracy. In particular, it researched how scaling out the cluster increases the speed of training and how the accuracy of the results is affected depending on the number of cluster nodes. Training iterations resulted in degradation of typically less than 0.5%.
How it works
TensorFlow is an open-source library for machine and deep learning that was originally developed by Google. It incorporates data flow graphs, with nodes in the graphs representing mathematical operations, and the edges of the graphs representing multi-dimensional data arrays (i.e., tensors).
TensorFlow has a low-level API written in Python and C++, notebooks and examples to learn from, and “the ability to customize neural network layers…which gives us great flexibility,” according to Andrei.
Andrei’s and Indrajit’s use of GPUs follows recommendations from the TensorFlow community, which encourages this as a way to meet the heavy processing demands of high-load projects.
In their presentation, they briefly discussed the use of machine learning to identify individual faces and objects such as automobiles. They then showed a medical data analysis example, noting they were inspired by the Camelyon16 Grand Challenge, which addressed the issue of automating the detection of metastases of lymph node sections.
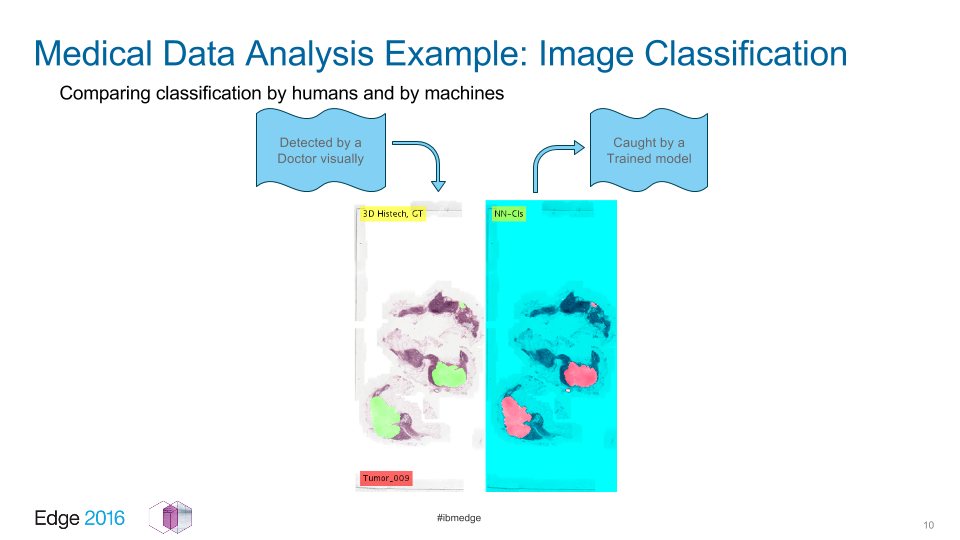
“We decided to try the new possibilities given by distributed TensorFlow and see if we could speed up the whole training using distribution and the OpenPOWER ppc64le architecture,” said Indrajit. “The (slide above) demonstrates a tumor marked by a researcher, manually at the left side and a tumor detected by an algorithm at the right side.”
“As you can see, the machine is able to catch everything, plus some points missed by human doctors.” —Indrajit Poddar, IBM
TensorFlow cluster: details
The computer science aspect of the study involved the use of clusters to distribute intensive tasks among nodes.
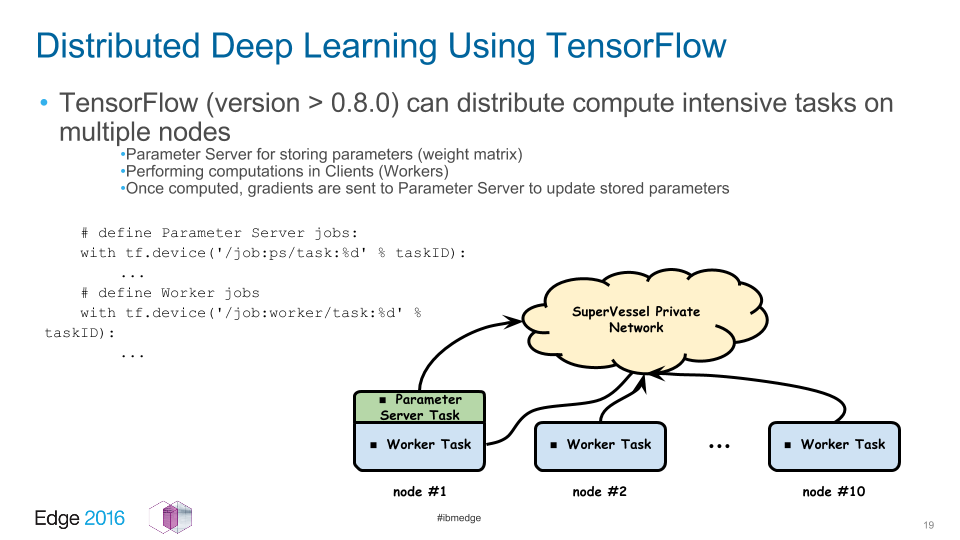
The study used 1–8 nodes as it scaled up to measure performance and accuracy.
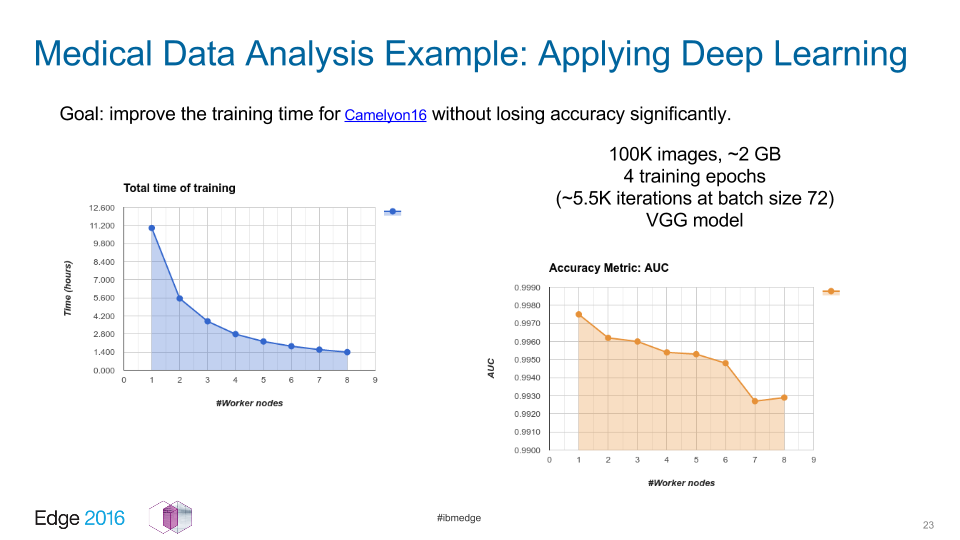
One of the goals was to improve the training time of the Camelyon16 data set without losing any significant accuracy, as illustrated in the slide below. Andrei and Indrajit found that the total time requirement dropped from about 11 hours with one node to about 1.4 hours with an 8-node cluster. The accuracy degraded only from 0.25% and 0.71% as shown in the slide below, “this method looks promising,” according to Indrajit.
As also mentioned above, this study employed the use of Dockerfiles. Andrei provided a code example used to create deep learning images.

How to optimize?
Andrei and Indrajit concluded their presentation with a discussion of some challenges and future goals. These included adding advanced resource scheduling with Platform Conductor and Kubernetes or Mesos couple of infrastructure issues, and adding more GPUs per system (up to 4–16 cards) for improved power consumption and better density. A distributed file system (such as HDFS) integrated with TensorFlow could also enhance the solution.
They also wish to fine-tune the use of TensorFlow, try synchronous training of the system in addition to the asynchronous approach they used in this test, increase the data set to 300,000, and increase the number of iterations.
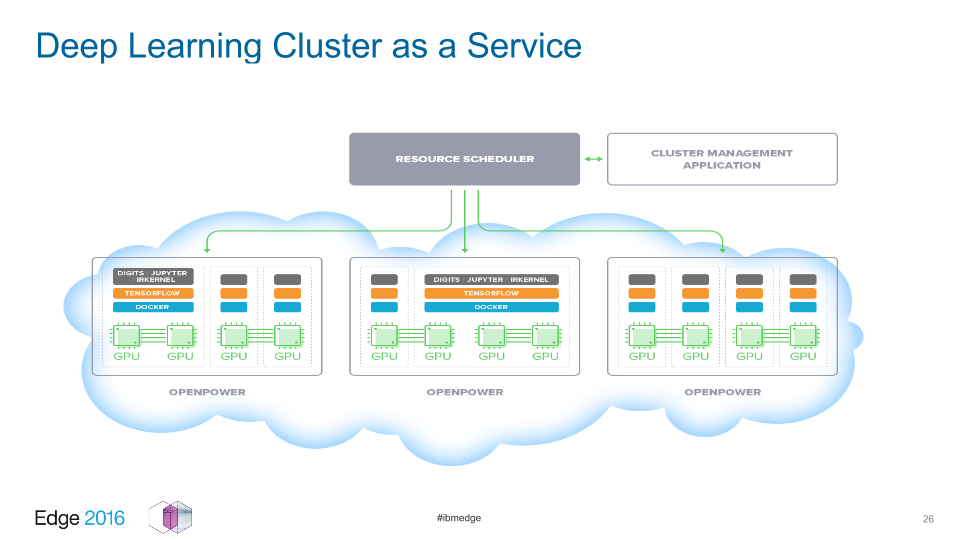 TensorFlow cluster as a service
TensorFlow cluster as a serviceThe promise of performance like this and a flexible container model could lead to the idea of Deep Learning as a Service. (Earlier, we covered the work on this concept.)
Want details? View the slides!
Further reading
- Prototype: TensorFlow as a Service on OpenPOWER Machines
- Cross-Modal Machine Learning as a Way to Prevent Improper Pathology Diagnostics
- Experimenting with Deep Neural Networks for X-ray Image Segmentation
About the experts
Indrajit Poddar is a software engineer with 17 years of experience in product development, technical strategy, incubation, and customer support. He has developed scalable distributed software and cloud services, transaction processing, and system management components—delivered through virtualized and cloud environments. Indrajit has expertise in Apache Spark analytics, deep learning, machine learning, and Cloud Foundry/Docker PaaS cloud services on OpenPOWER systems. He is an IBM Master Inventor with three IBM Outstanding Technical Achievement awards.
Andrei Yurkevich serves as President and Chief Technology Officer at Altoros. Under his supervision, the engineering team has grown from zero to 250+ specialists across seven global locations. Currently, he is responsible for technology alliances in big data and PaaS. Andrei has successfully implemented strategies for software product development, marketing, motivation systems, personnel performance management, and team building.