Prototype: TensorFlow-as-a-Service on OpenPOWER Machines

TensorFlow is an open-source deep learning library originally developed by Google. The solution’s flexible architecture allows for deploying computations to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API.
Altoros created a prototype of a multi-user TensorFlow service on OpenPOWER machines with NVIDIA GPUs and Docker. The prototype was demonstrated at the GPU Technology Conference in April 2016.
What’s the concept?
We demonstrated a method to create a multi-tenant, multi-user, multi-GPU TensorFlow environment that would enable teams of data scientists to collaborate on a common problem.
The prototype is a cluster, combining several OpenPOWER S822LC machines. Each machine includes:
- two GPU cards (NVIDIA Tesla K80) that are recognized within the OS as four GPU devices
- isolated Docker containers (using the NVIDIA-Docker project)
- TensorFlow (in Docker)
- customized NVIDIA Digits installed
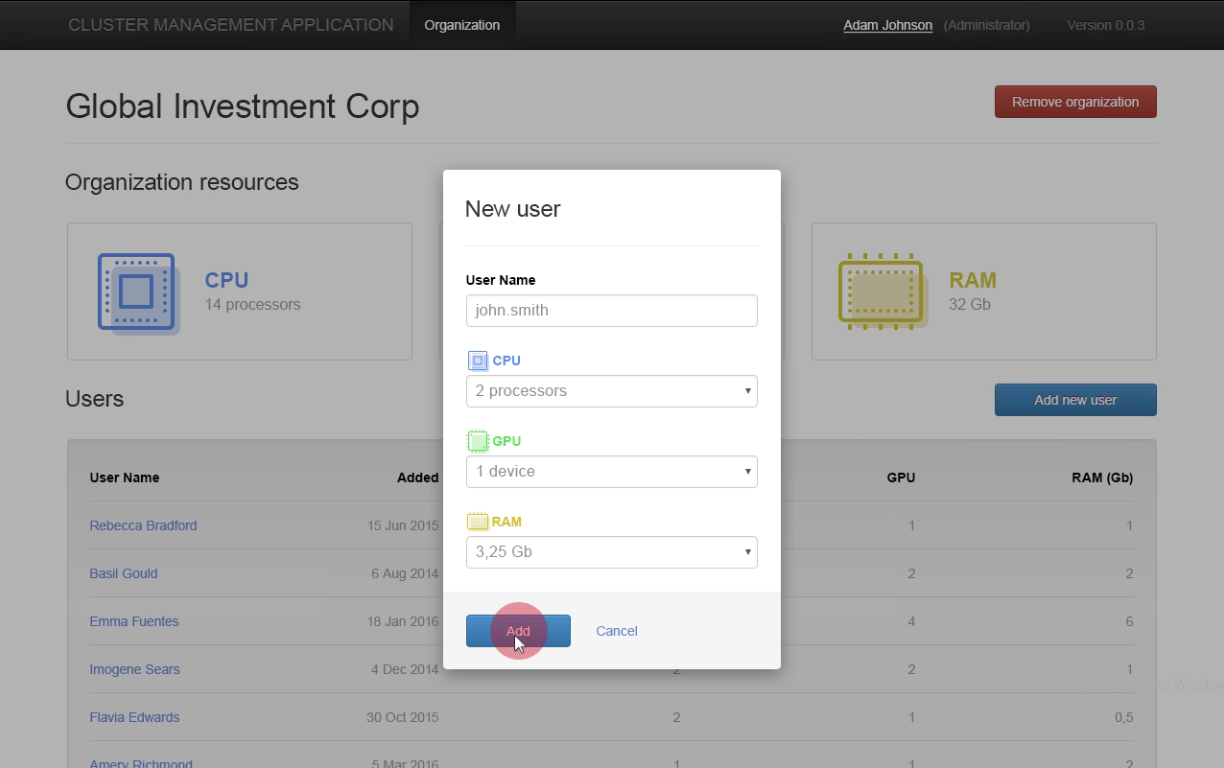
The cluster is controlled by a cluster management app. The scheduler of the management app is responsible for allocating resources to perform GPU calculations. Each Docker container can have different portions of CPU, GPU, or RAM resources; the resources are defined for each container on its creation.
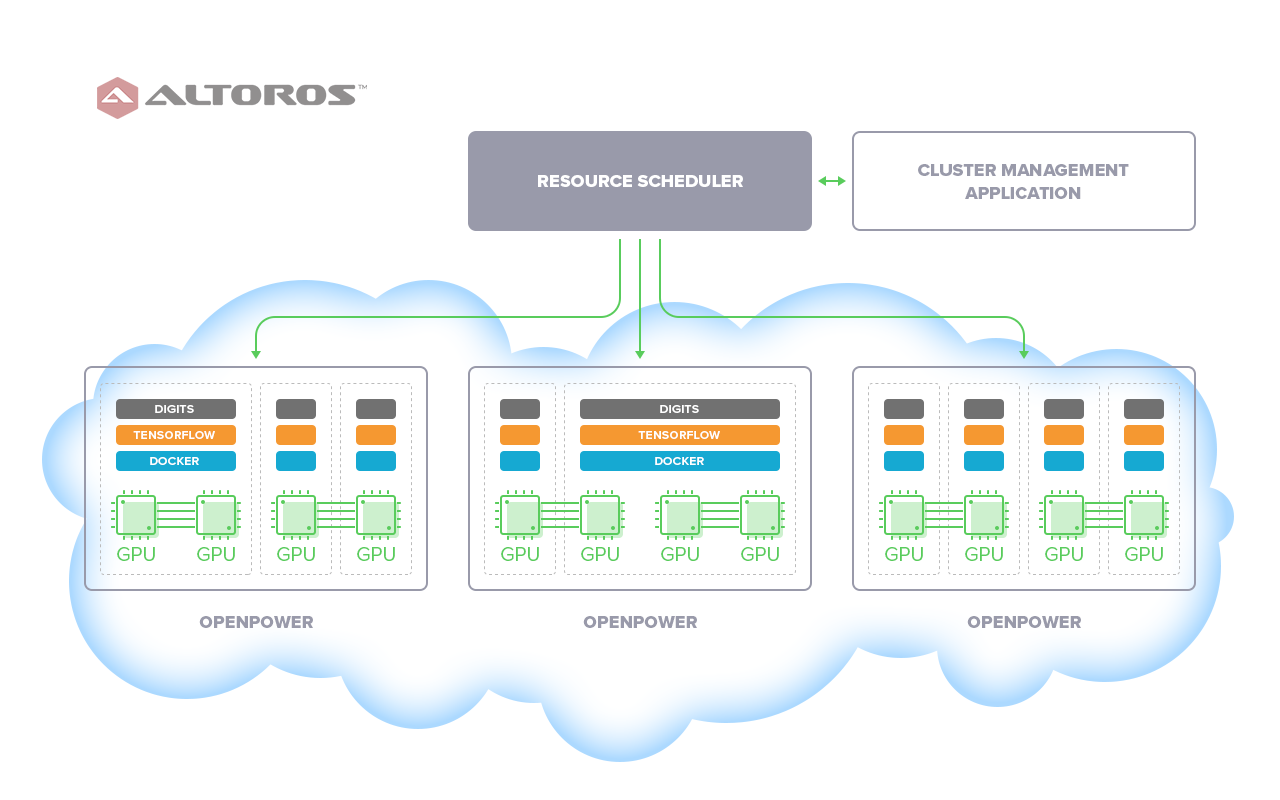
How it works
On logging into a cluster management app, an admin gets access to the resources of the cluster (CPU, GPU, RAM) and list of organizations registered within the system. The information about the number of users and resources within each organization is also available.
When you create a new user within an organization, you allocate resources for the user. A Docker container with these resources is created automatically.
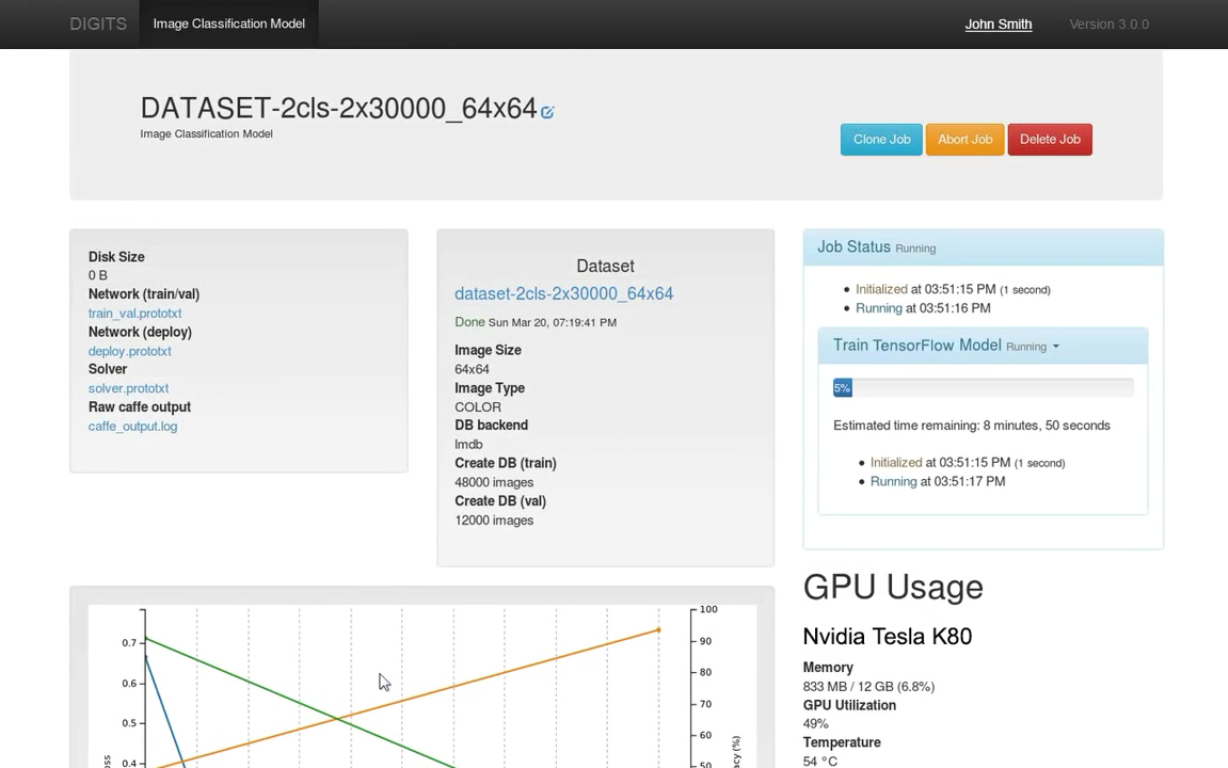
Then, a user can choose the customized Digits app running on the Docker container. The user can create a new model by selecting a data set, standard network, and saving the model.
Results
To examine how fast the solution trains a model, we carried out some experiments with CIFAR-10, a widely recognized visual data set used for object recognition. It consists of 60,000 32×32 color images across 10 categories (airplanes, cars, cats, dogs, etc.). The CIFAR-10 data set was tested with default settings:
- on OpenPOWER
- on Amazon AWS
- inside a Docker container on OpenPOWER
When training a model on bare OpenPOWER machines with the NVIDIA K80 GPUs, it took 6 hours to achieve 86% of accuracy (ratio between the number of correct predictions and the total number of predictions). Approximately the same time was needed to train a model using TensorFlow inside a Docker container on OpenPOWER. However, training the model on Amazon AWS was slower by approximately three times (i.e., training time was about 15–18 hours).
In the course of the experiment, we’ve also found out that Amazon’s GPU cards (NVIDIA GRID GK104 “Kepler”) are outdated to support TensorFlow. So, engineers at Altoros rebuilt TensorFlow to provide compatibility with the older version of GPU.
Although the work on the prototype is still in progress, we expect that a “dockerized” OpenPOWER service for TensorFlow will be a viable alternative to a multi-user/multi-tenant service, since no performance bottlenecks were detected when running tests inside a Docker container.
We would like to thank the IBM team for the OpenPOWER resources and Indrajit Poddar, Senior Technical Staff Member at IBM, for help with running TensorFlow and Docker with GPUs on OpenPOWER.
Let us know in the comments if you want to learn more about the prototype or need to develop something similar.
Further reading
- Porting Cloud Foundry to IBM POWER Processors
- TensorFlow and OpenPOWER Driving Faster Cancer Recognition and Diagnosis
About the authors
Sergey Kovalev is a senior software engineer with extensive experience in high-load application development, big data and NoSQL solutions, cloud computing, data warehousing, and machine learning. He has strong expertise in back-end engineering, applying the best approaches for development, architecture design, and scaling. He has solid background in software development practices, such as the Agile methodology, prototyping, patterns, refactoring, and code review. Now, Sergey’s main interest lies in big data distributed computing and machine learning.
Alexander Lomov is a Cloud Foundry Engineer at Altoros. With extensive Ruby experience, Alexander is a fan of the open source movement, having contributed to BOSH, Cloud Foundry, Fog, and many other projects. His professional interests include distributed computing, cloud technologies, and much more. Find him on Twitter or GitHub.