
AWS S3 Outage: Lessons Learned for Cloud Foundry Users

Not your typical day of troubleshooting
Imagine an average programmer, let’s call him John, entering his office in San Francisco at 9 a.m. in the morning on February the 28th. He starts his daily routine reviewing tasks in Trello, checking out code from GitHub, and running his favorite code editor.
9:58 a.m. Having implemented a number of small features, John checks Trello again. Trello is annoyingly slow, so John decides to reach his colleague by Slack. Slack shows a spinning loading circle for longer than expected.
10:05 a.m. Worn out of patience, John leaves his desk to see his Product Manager, Bill. John finds Bill staring at his monitor, taken aback by the avalanche of e-mails, notifying that their service is down. The bill the company will have to pay to compensate this outage is going to be a disaster!
10:08 a.m. Searching for the root of the problem, Bill checks the AWS status page, but it returns a green status, indicating that everything is okay.
10:30 a.m. Bill checks the AWS status page once again and sees a red banner notifying that Amazon has identified an issue with its S3 US-EAST-1 and is actively working upon it. Interestingly, the status label is still green, since the status page itself relies on S3.
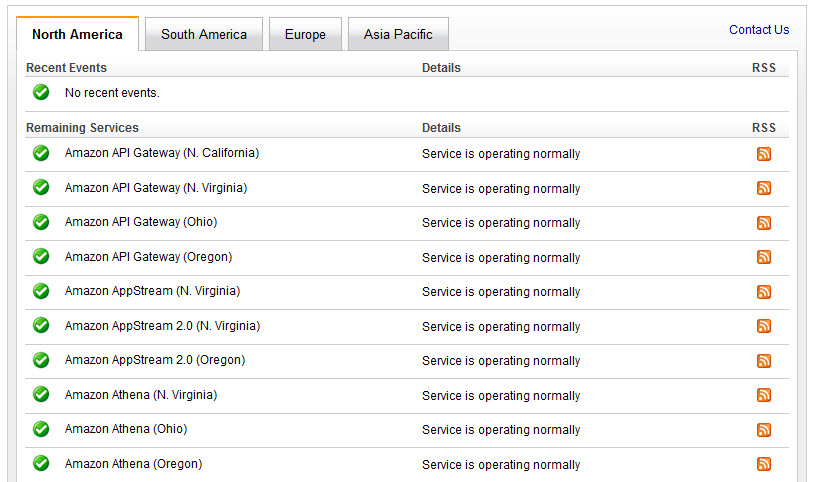 Image credit: Amazon
Image credit: Amazon10:42 a.m. Bill gets an idea of re-deploying their services to other regions and begs John to spin new instances of their service in other AWS regions as soon as possible.
10:45 a.m. John realizes that, since the company is using a private Docker registry with a S3 storage driver, he can not get and spin up containers from pre-baked Docker images in this registry.
11:02 a.m. The only solution John comes up with is to try building new images from Dockerfiles from their projects, but the GitHub repositories the company uses are not available.
12:10 p.m. Somehow, John manages to collect all necessary Dockerfiles and process image building, but soon he understands that the packages these Docker images require are fetched so slowly that it will take at least 12 hours to build them all.
2:10 p.m. John and Bill have nothing to do but sit waiting for S3 to get recovered. All development activities are blocked, all services are down. Bill submits a complaint to AWS Support, and John posts funny jokes on Twitter, which happens to be available.
Sadly, John’s company is not the one that fell on its feet when confronted with the Amazon S3 Service Disruption incident.
What caused the outage?
The incident alerts us to the occasional fragility of Internet services, picturing how much loss a company can suffer when the single service it relies upon is being disrupted. We’ve seen it before with the DynDNS attack in 2016, but this very outage has a different origin. According to Amazon’s post-mortem, the issue was caused by a chain of events triggered by a human error.
Amazon claimed that the issue resulted from an engineer misspelling a command argument, which lead to removal of a larger chunk of servers for one of the S3 subsystems. As soon as the engineers at Amazon detected the problem, they restarted the systems. It took much longer than expected, since this scenario had never been tested out in the wild.
 Image credit: Data Center Dynamics
Image credit: Data Center DynamicsIt turned out that other AWS services—including the S3 console, Amazon Elastic Compute Cloud (EC2) new instance launches, Amazon Elastic Block Store (EBS) volumes (when data was needed from a S3 snapshot), and AWS Lambda—rely on S3 for storage. All of them were also impacted while the S3 APIs were unavailable.
What services got disrupted?
With the disruption, over 70 services were affected including, but not limited to: Adobe’s services, Airbnb, Amazon’s Twitch, Atlassian’s Bitbucket and HipChat, Autodesk Live and Cloud Rendering, Business Insider, Chef, Citrix, Codecademy, Coindesk, Coursera, Docker, Down Detector, Elastic, Expedia, Giphy, GitHub, GitLab, Google-owned Fabric, Greenhouse, Heroku, Imgur, Ionic, isitdownrightnow.com, JSTOR, Kickstarter, Lonely Planet, Mailchimp, Medium, Microsoft’s HockeyApp, the MIT Technology Review, New Relic, News Corp, Pinterest, Quora, SendGrid, Signal, Slack, Snapchat’s Bitmoji, Travis CI, Time Inc., Trello, Twilio, the U.S. Securities and Exchange Commission (SEC), The Verge, Vermont Public Radio, VSCO, Wix, and Zendesk.
This list can by no means be considered exhaustive.
 Image credit: BleepingComputer
Image credit: BleepingComputerInterestingly enough, a number of services were built by developers for developers. Failure of these services prevented operators from reacting to the warning messages and taking actions to recover.
Similarly, the Amazon status page showed a green label throughout all the time AWS was down, indicating deceptively that everything was okay.
Learning through forced downtime
The only service that relied on AWS S3, but survived the big blackout, was Netflix. And surviving such an outage did not come by chance. For a very long time, Netflix has been basing its software building process on the assumption that there is no 100% reliable part of infrastructure. The company tested its services rigorously by imitating failure. The idea was to use a tool that systematically brings destruction to the underlying infrastructure by killing VMs, emulating a network split and so on. This most widely known tool is named Chaos Monkey.
Netflix is a good example of how crashing your systems on purpose can prevent them from crashing your business in case of an unexpected disruption.
 Image credit: Netflix
Image credit: NetflixThe company taught us that using some resilience testing tool or technique is not enough per se. To survive such a big outage as AWS S3 has just had, you need to base your infrastructure building process on a well-defined, systematic approach tying the development and deployment processes in one. You need to have reliable monitoring and notification systems in place, run load and resilience testing, and integrate a number of independent tools enabling repeatable and stable deployments.
To be aware of all possible losses, you need to better understand dependencies behind your services. And predicting behaviour of a complex heavily distributed system that is built upon several independent layers is extremely hard!
Reducing the risk of disruption in Cloud Foundry
If you are dealing with Cloud Foundry community services, you have a number of options to run resilience tests. The two most powerful options are Turbulence and Chaos Loris.
Turbulence is a BOSH-deployed service that uses BOSH itself to simulate different types of outages, from termination of VMs to complex scenarios involving network partitioning, packet loss and delay, CPU or Memory load on VMs. When used together with Concourse CI, Turbulence emerges as a very powerful solution to detect problems on early stages.
Chaos Loris works in a similar manner, but only with applications deployed to Cloud Foundry. You can bind your app with the Chaos Loris Cloud Foundry Service using a single command and this test will provide you with understanding your application behaviour in extreme situations.
The whole story proves that one is better not rely only on the providers’ SLA, but develop a set of measures that would ensure one’s service is up and running in case of a disaster or outage infrastructure points fail. BOSH—supporting a variety of clouds and facilitating migration between them—coupled with Turbulence and Chaos Loris allows for enabling reliable and repeatable deployment across multiple clouds with no vendor lock-in.




