General Availability of Hyperledger Fabric v1.0: What to Expect in 2017 and When?

Launched little more than a year ago, with the consequent incubation of its Fabric, the Hyperledger Project is developing the idea of creating a private, permissioned system that does not have a cryptocurrency at its core. In this post, we’ve collected everything we could about the Fabric’s roadmap for 2017, trying to understand where it is headed.
An Alpha look

Binh Nguyen
The Alpha release, announced by Binh Nguyen on March 17, brought along a new architecture (transaction flow), multi-ledgers, a pluggable data store, and other features.
The most significant updates included:
- Docker deployment capabilities made Docker images available for all major components to run a network.
- A bootstrap network tool called the Configuration Transaction Generator (configtxgen) was introduced.
- Multiple membership services authenticate, authorize, and manage identities for a permissioned blockchain network. Issuers are also able to revoke transaction certificates or designate them to expire within a certain time frame, enabling better control within a network. TCerts allow for role-based transactions to occur.
- A Hardware Security Module (HSM) is supported to help increase safeguarding of keys.
- Support for SDKs provides a structured environment of libraries for developers to write and test chaincode applications. Node.js and Java SDKs are available now, Go and Python versions are on the schedule.
- Chaincode can be thought of as business-logic code, and runs through the SDK or CLI onto a network of the Hyperledger peer nodes.
- Consensus is defined as “the full-circle verification of the correctness of a set of transactions comprising a block.” Ordering support service includes Solo and Kafka. With Crash Fault Tolerance ordering service (i.e., Kafka), there is an ability to add and remove ordering service nodes and create channels.
- Multi channels, which can be thought of as private blockchain overlays, allow for data isolation and confidentiality. A channel-specific ledger is enacted per channel creation.
- Peers can be dynamically added to and removed from the network.
- A ledger can be created for each channel, and each peer maintains a copy of the ledger for each channel. Rich queries are supported if using CouchDB as the state database.
- Modular and pluggable components. “Clear interfaces were defined for membership services, SDK, Peer, Endorsement, the Consensus service, and the ledger,” according to the Alpha release notes. “This provides the opportunity for individuals, startups, or enterprises to plug in their own pieces for these various components. As an example, a startup may want to plug in their own authentication and authorization capabilities for membership services instead of fabric-ca, or a company may want to plug in other encryption algorithms based on the country requirements.”
- Pluggable cryptoalgorithms required by individual projects can replace a built-in cryptolibrary as needed.
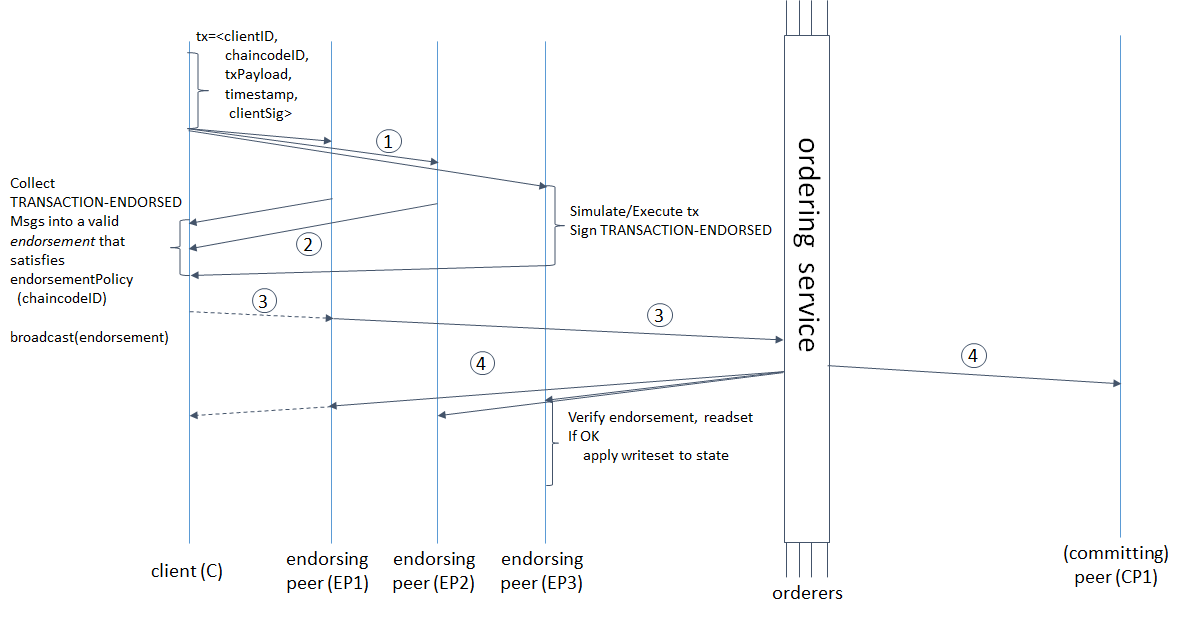 A sample transaction flow—a common-case path (Image credit)
A sample transaction flow—a common-case path (Image credit)You can check out a detailed overview of the Alpha release or download the product.
Upcoming general availability

Jonathan Levi
In a letter on collaboration, Jonathan Levi brought contributors’ attention to how Fabric’s Alpha release is progressing towards general availability (GA). The community is in the process of collecting feedback, which already allowed to detect some bottlenecks (e.g., some issues with Vagrant on Windows, static linking to a library that needs updating, etc.).
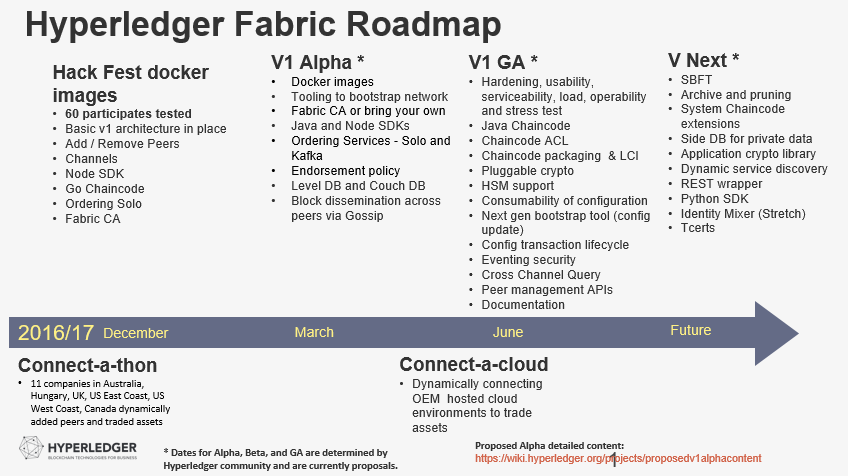
Meanwhile, the updated roadmap was submitted by Mark Parzygnat, and the JIRA task its under, as Jonathan stressed, is also waiting for feedback. According to the roadmap, Fabric’s v1.0 GA release is supposed to offer a set of the following key features by June 2017:

Mark Parzygnat
- Hardening, usability, serviceability, load, operability, and stress test
- Java chaincode
- Chaincode packaging and life cycle, TCerts in SDK / Chaincode ACL
- Pluggable cryptofunctionality
- Consumability of configuration
- Next-generation Bootstrap tool (config update)
- Configuration transaction life cycle
- Eventing security, HSM support
- Cross-channel query
- Peer management APIs
The work is also being done on documentation and release/collaboration strategy.
 Source
SourceOngoing conversations are happening in several locations, including Fabric maintainers’ chat channel, JIRA, mailing lists, etc.

Gari Singh
So, in order to facilitate the coordination processes, Jonathan created a doc, where the community members share their vision on the pros and cons of the strategies employed to deliver the upcoming GA release. For example, Gari Singh raised the question concerning how the contributors should handle versioning of the external APIs.
“As we know, Go has no concept of versioning. Our biggest problem will be with the chaincode API, since most people will access the GRPC APIs via SDK implementations.” —Gari Singh
Christopher Ferris
“We have a ton of work to do to harden. There are 298 unresolved bugs in JIRA. While many are v0.6, we still need to triage and fix those that are still relevant.” —Christopher Ferris
The issues are being processed in the Hyperledger Fabric’s tracker.
Post-v1.0 plans
Then, we will have the post-v1.0 era. According to the roadmap diagram from Mark, the key ideas to be implemented in the upcoming post-v1.0 releases are as follows:
- Simplified Byzantine Fault Tolerance (SBFT)
- Archive and pruning (see below)
- System chaincode extensions
- Side DB for private data
- An application cryptolibrary
- Dynamic service discovery
- A REST wrapper
- Python SDK
- Identity Mixer (Stretch)
The official documentation also states that the post-v1.0 functionality will also include filtering out invalid transactions with a validated ledger and peer ledger checkpointing (pruning). So, how the two features work?
A validated ledger, or VLedger, embodies a hash chain derived from the ledger by means of filtering out any invalid transactions. The process behind is targeted at maintaining a ledger abstraction that comprises only valid and committed transactions by enabling peers to maintain a validated ledger in addition to state and a ledger.
PeerLedger blocks may include invalid transactions—containing invalid endorsement / invalid version dependencies. After filtering out such transactions (every peer does it by itself), a VLedger block (vBlock) is formed. Note that vBlocks are inherently dynamic in size and may be empty.
Each vBlock contains the following elements:
- The hash of the previous vBlock
- A vBlock number
- An ordered list of valid transactions in a corresponding block
- The hash of the corresponding block (in PeerLedger), from which the current vBlock is derived
Then, vBlocks are chained together to a hash chain by every peer. As a result, a peer produces the hash of a vBlock in the validated ledger.
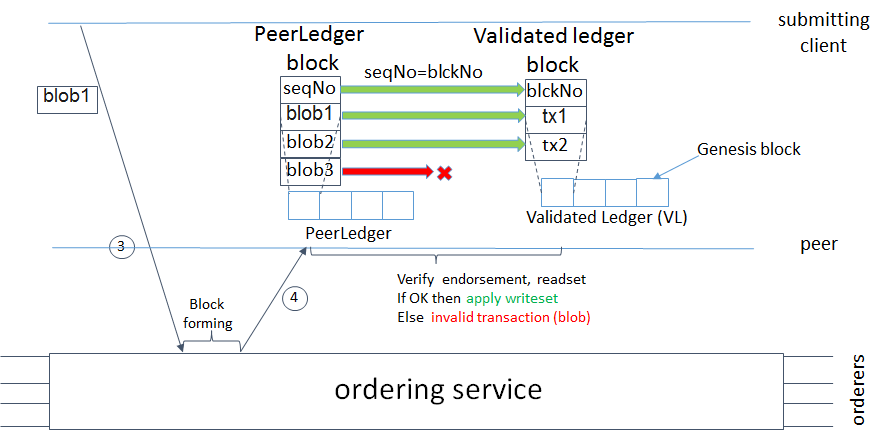 The formation of a vBlock from PeerLedger blocks (Image credit)
The formation of a vBlock from PeerLedger blocks (Image credit)On establishing vBlocks, peers are not able to just discard PeerLedger blocks and thereby prune a PeerLedger. For instance, if a new peer joins the network, other peers cannot transfer the discarded blocks (pertaining to the PeerLedger) to the joining peer or convince the new peer of the validity of their vBlocks.
To enhance the pruning process, a checkpointing mechanism is supposed to be established within the post-v1.0 releases of Hyperledger Fabric. The mechanism will ensure the validity of vBlocks across the peer network and allow the checkpointed vBlocks to replace the discarded PeerLedger blocks. It will also help to reduce both the storage space (no need to store invalid transactions any more) and efforts involved in reconstructing the state for the new peers added.
Along with the checkpointing protocol underlying the mechanism, the checkpoint validity policy is to be delivered. The policy is to comprise two approaches, which may be combined:
- Local (peer-specific) checkpoint validity policy
- Global checkpoint validity policy
The purpose of it is to define when a peer can prune its PeerLedger and how many ‘checkpoint’ messages are “sufficiently many.”
More areas to explore
We should also note that many things are happening in the Hyperledger community outside Fabric. For instance, the recent Burrow incubation integrates the Ethererum Virtual Machine into Hyperledger’s private, permissioned system. Burrow’s backers stress that the two respective blockchains, Hyperledger and Ethereum, are complementary rather than competitive with one another.
Other active Hyperledger incubations include Blockchain Explorer, Cello, Iroha, and Sawtooth Lake.
 Makoto Takemiya, the Iroha project
Makoto Takemiya, the Iroha projectThe Hyperledger Fabric community has also been working on developing use cases, although this sort of effort will always be limited by having to think about theoretical, general ideas, rather than being driven by the need to address a specific, screaming problem. That said, here are a few general notions that have been developed along the way, including general B2B contracts, a manufacturing supply-chain example, and an asset depository.
Enterprises that are now seriously considering the use of Hyperledger should feel free to work with the Alpha release, in anticipation of a strong general v1.0 in a few months. At the same time, the best way for Global 2000 enterprises to keep pace with Hyperledger in general and Fabric in particular is to participate in its development, thereby obviating some of the advantages of the disruptive startups that will be deploying it.
Disrupt the disrupters, in other words, and blockchain technology seems to be a powerful way to do this.
Related reading
- Hyperledger Fabric v1.0: Multi-Ledgers, Multi-Channels, and Node.js SDK
- Hyperledger Fabric’s Chaincode, Practical Byzantine Fault Tolerance, and v1.0
- Hyperledger Fabric Approaches v1.0 with Better Scalability and Security
- Hyperledger Fabric v1.0 to Bring Improved Transactions and a Pluggable Data Store