The Apriori Algorithm vs. k-means Clustering for a Recommendation Engine

Association rules or other options?
Data analytics for a large online store involves a number of challenges. Product data may be complex by nature and reach terabytes in size, your data stores may be (geo-)distributed, association algorithms may require significant memory resources, etc.
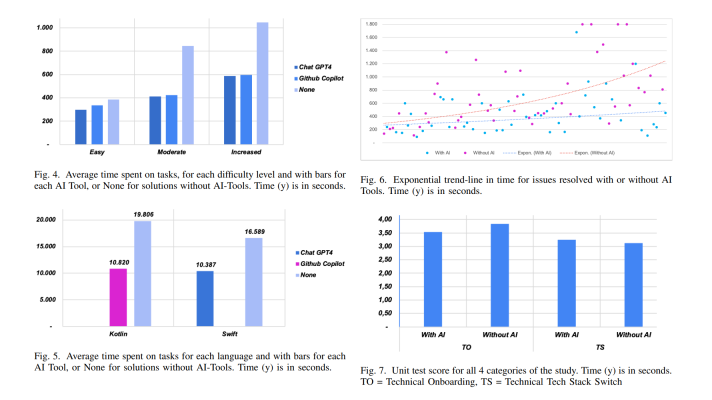
One of our customers needed a recommendation engine for a media streaming service to increase sales. The task was to develop a model that would provide relevant movie suggestions to users. Due to the extremely large size of data, the customer wanted to avoid using clustering, which groups data based on purchasing history.
Initially, the decision was to go with the Apriori algorithm that builds association rules based on frequent sequences found in transactions. However, when working with real data, we stumbled upon certain limitations and therefore looked for other options. As a result, using k-means clustering succeeded in building more relevant recommendations and providing more options for visitors.
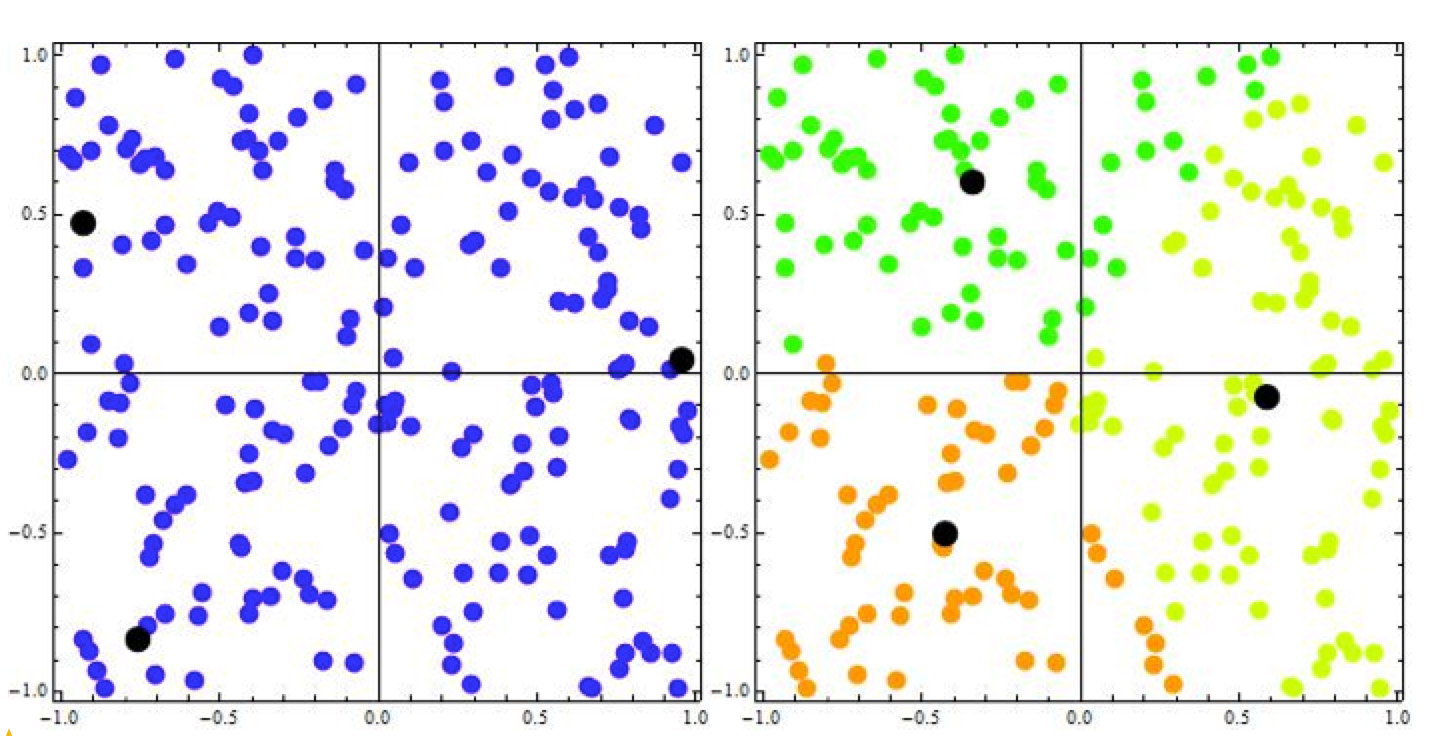 An example of clustering
An example of clustering
Findings
Today, we present our findings in a detailed research paper, “A Comparison of the Apriori Algorithm vs. k-means Clustering for a Movie Recommendation Engine.” The document contains:
- a brief overview of 4 popular algorithms for building recommendations
- tips on efficient data preprocessing to reduce computational resources used
- 3 methods that can improve the quality of search recommendations
- a comparative table with results of using Apriori vs. k-means
- 12 diagrams that feature recommendations based on real-life data
Download the study and feel free to send us your feedback.
Want details? See the slides!