5 Steps to Integrate SugarCRM with Third-Party Systems and Avoid Mistakes

Numerous sources to get data from
Companies of all sizes are challenged to deliver their products and services to market faster—to manage more complex sales and marketing programs with limited budgets and decreasing time frames—in order to accelerate revenue generation.

SugarCRM represents a tremendous opportunity for companies to solve these challenges by using its proven, non-intrusive, and scalable on-demand platform. To fully leverage the benefits of SugarCRM, companies must realize the need to integrate customer-facing business processes with the rest of the enterprise.
Today, when hosted CRM software is becoming mainstream, a typical company using SugarCRM has to figure out how to connect the information residing in the system with third-party software—such as ERP, accounting and CRM packages, custom applications, and databases. Having the right data integration and data quality model is critical.
At some point, SugarCRM users realize the need to integrate their customer information between the system and third-party apps. What steps should be taken to get your customer and enterprise information (currently residing in SugarCRM) integrated, replicated, or migrated to your new software-as-a-service package?
This article will guide you through the process of integrating SugarCRM data with third-party applications and databases by using the freely available, open-source Apatar Data Integration tool as an example. The post will also provide a set of best practices and tips on how to solve typical challenges, as well as avoid the most common mistakes.
Step #1. Preparation and planning
Prior to any data migration, ask yourself some questions to clarify the goals of the oncoming integration process. For data integration specialists, it is critical to know:
- What data (tables/fields/rows) should be extracted?
- What data (tables/fields/rows) should be considered as targets?
- Do I need to integrate SugarCRM with a single database or multiple data sources?
- Is it enough to perform a one-time migration, or do I need an ongoing synchronization?
- Do I need to have SugarCRM data backed up?
- Do I have enough experience to do manual coding, or would the use of visual data integration tools be the best decision?
In case you are still considering manual coding, take into account the time and effort required to learn APIs, provide connectivity to both the source and the target, write transformation logic, and, most importantly, the tasks related to debugging, reporting, and future maintenance of the integration and the related metadata.
The more clearly you set the goals, the more accurate your SugarCRM integration will be. Sometimes, you may need to join data; sometimes, it’s all about eliminating duplications. In some cases, the data should be validated or filtered first.
Possible mistakes:
- No strategic vision.
- Lack of evaluation criteria.
Possible solution:
- Try to set your objectives and goals properly.
Step #2. Data source connection maintenance
To start reading source data, you need to establish connections to the source databases. In other words, you need to gain access to data tables, structures, and entries. This is where data integration actually starts. With visual tools such as Apatar, for instance, you can do it without having to write a single line of a code. Just open the “drag-and-drop” job designer, choose the necessary data connectors, enter SugarCRM authorization details, and provide the paths to the database servers or storage files. The application is ready to operate the data.
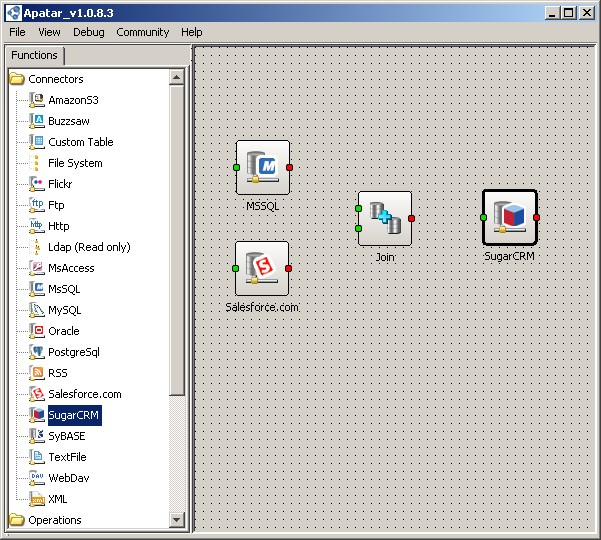
Data source connections
Possible mistakes:
- Company’s data integration map is not comprehensive and lacks a number of data sources being used during decision-making.
Possible solution:
- Explore the needs and communications between the company’s departments to identify the most critical data flows.
- Structure your in-house data and join it with the integration map.
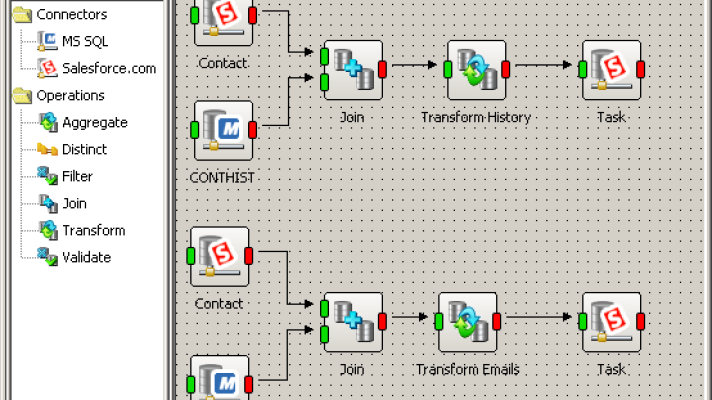
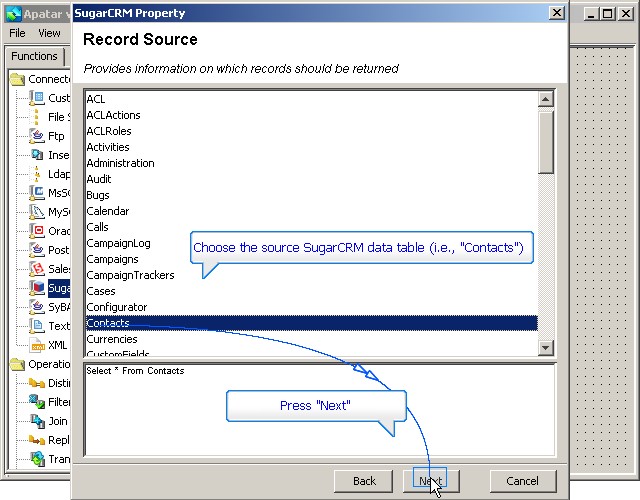 Choosing SugarCRM source data tables
Choosing SugarCRM source data tables
Step #3. Using a staging database
You may also want to mashup data from multiple sources. For instance, take news from an RSS feed, extract customer information from GoldMine CRM, standardize and cleanse data, verify e-mails, names, and addresses, and then mix it all up and throw it across your SugarCRM tables. Consider this step if you have multiple data targets from which to aggregate information, or if you have to apply complex data cleansing or enrichment rules to the data on its way between the source and the target. This step is optional, but sometimes it’s worth considering.
In this example, we will use MySQL to host staging data. To connect to the MySQL database, you may use Apatar’s embedded MySQL connector. The process of establishing the connection is identical to the one described in the previous step. Just drag-and-drop the connector to Apatar’s work panel, enter database authentication details, and provide the paths to MySQL.
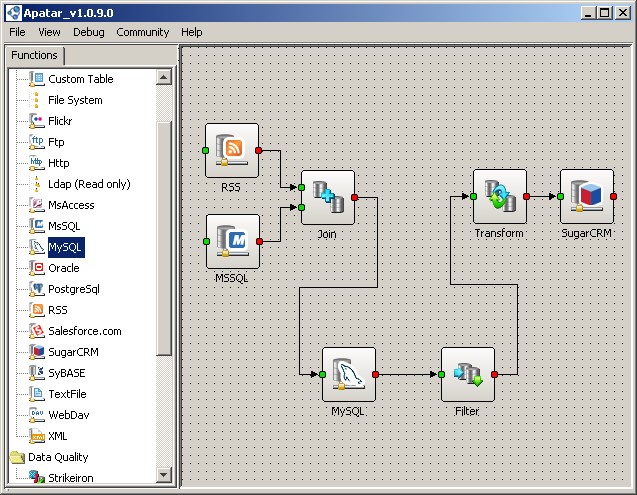 Staging MySQL database usage
Staging MySQL database usagePossible mistakes:
- Wrong validation or enrichment rules.
- Data duplications.
Possible solution:
- Set the filtration criteria, avoid loading odd information, and define data enrichment rules.
- If necessary, consult with a data warehousing specialist.
Step #4. Map the source with the destination
According to The Gartner Group, corporate developers spend approximately 65% of their effort building bridges between applications. Luckily, today’s data integration tools allow even non-technical users to integrate data between systems, databases, and applications. Imagine you could visually design (“drag and drop”) a workflow to exchange data between files (Microsoft Excel spreadsheets, CSV/TXT files), databases (such as MySQL, MS SQL, Oracle), applications (Salesforce.com, SugarCRM), and the top Web 2.0 destinations (Flickr, RSS feeds, Amazon S3, etc.), all without coding.
As an example of such visual tools, Apatar embeds a visual job designer to enable users to create integration jobs called DataMaps, link data between the source(s) and the target(s), and schedule one-time or recurring data transformations. These data “mashups” can be saved for future reuse, or sharing, or even redistribution. In other words, now you have all the integration settings saved and will not have to waste your time again and again if you want to perform a similar task or repeat exactly the same transformations.
With installation taking 60 seconds or less, users connect to data destinations and then match appropriate source (e.g., legacy CRM) and target (SugarCRM) fields to accomplish the data integration job.
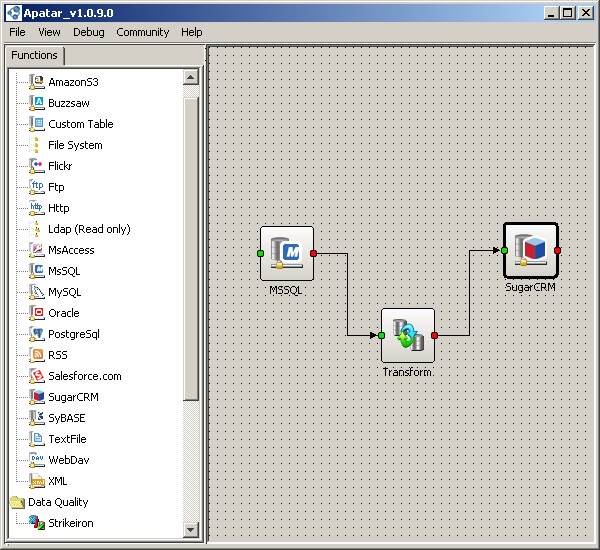
Visual mapping
To do this, simply open the Apatar desktop client application, connect to data destinations, map the connectors together, and then match appropriate source (e.g., GoldMine CRM) and target (SugarCRM) fields to start populating the tables.
To match the fields, double-click on the Transform node and drag-and-drop into its work panel all the input and output fields you want to transfer from GoldMine to SugarCRM. Map the fields together.
Why is the mapping so critical? First, you need to point out where the source of data is, and where the target is. Second, sometimes you need to transform third-party database table formats to SugarCRM table formats. For instance, if you have the Time or Binary objects at the source and need to save them as text at the target.
Using mapping, you tell your data integration tool what transformations you want to do, and where exactly you want them to be done.
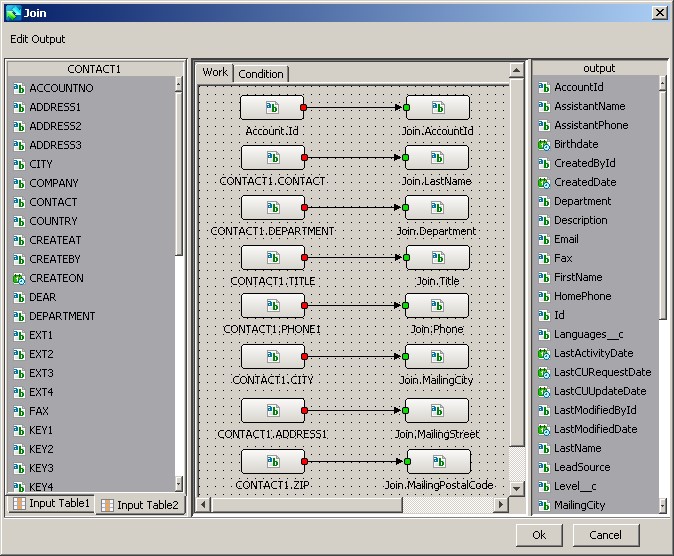
Fields mapping
Possible mistakes:
- Input and output data types are contradictory.
- Overlying complex data maps and relevance models.
- The wrong table structure vision.
Possible solution:
- Perform necessary data type transformations.
- The simplier your models, the more stable they are.
- If necessary, request support from SugarCRM team to clarify data table structures and relations.
Step #5. Run the transformation
Now the integration job is almost complete. Run the transformation and let your SugarCRM accounts be populated. If all initial settings and mappings were accomplished accurately, you may now just sit back and relax. The data integration tool will do the integration.
Possible mistakes:
- The integration scheme is not saved.
Possible solution:
- Save your mappings into a single DataMap to avoid odd actions and losses (see the next section for details).
Recurring, automated integration
Scheduled synchronization
Business data is never consistent; real-time updates, new data entries, and other changes require maintenance. If you need recurring integration jobs, you may also use the scheduling function to automate the data integration process. Tools such as Apatar enable you to configure automated scheduling by entering the frequency of transformations and specifying the lifetime of a scheduled job. For example, you can set data migrations to launch at midnight daily and last until the end of this year. Each morning, you will find the entire set of customer data synchronized.
Ensuring the recovery of CRM data
In particular, to have your customer data backed up to a secure remote location, you may want to explore Amazon Simple Storage Service (Amazon S3), which lets you easily store and retrieve virtually any amount of files anytime, anywhere. Amazon S3 deploys the same highly scalable, reliable, fast, and inexpensive data storage infrastructure that Amazon.com uses to run its own global network of websites. Apatar’s Amazon S3 connector brings the power of Amazon S3 to SugarCRM users who may want to store or back up SugarCRM customer data and documents.
For instance, if a company’s executive wants to have his or her company’s most significant customer information backed up every day (e.g., extracted into flat files, and saved to Amazon S3), the Apatar tool allows for this data to be backed up and then uploaded to web storage at a specified time. All you need to do is configure the Amazon S3 connector and enter the frequency and the moments of SugarCRM data backups in Apatar’s Scheduling module. The ETL engine will do the rest automatically.
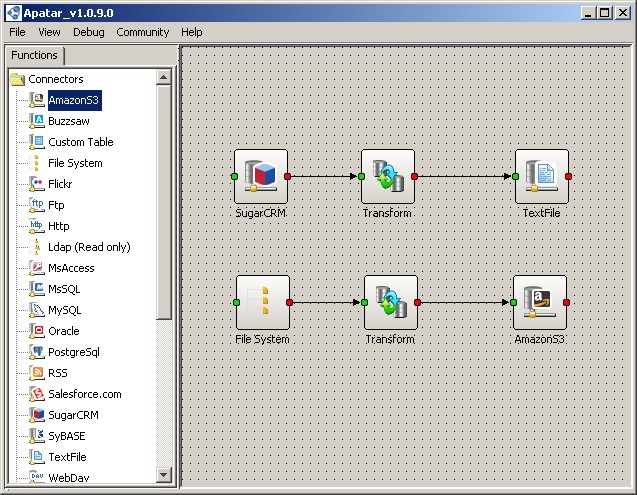 Backing up SugarCRM data to Amazon S3
Backing up SugarCRM data to Amazon S3
Creating reusable integrations
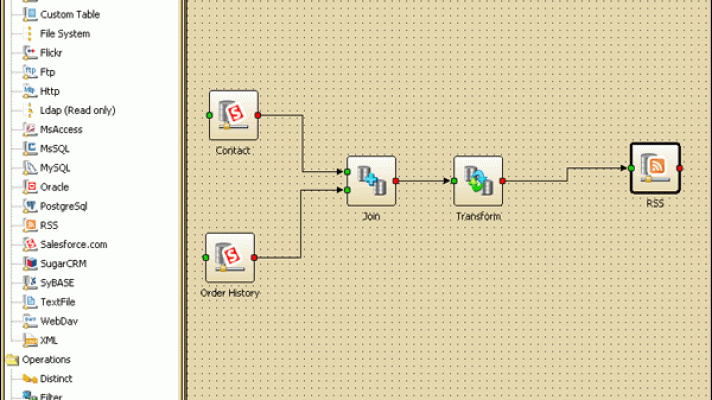
In many cases, you need to repeat the migration later or redo it from the start. You may also want to mashup data from multiple sources. For instance, take news from an RSS feed, filter news related to SugarCRM accounts, and throw it across your SugarCRM contacts/leads. With Apatar, developers can create integration jobs called “DataMaps” to store the data links between sources and targets. Creating reusable data mappings and scheduling synchronization jobs for them can help you to save time on data extractions/integrations needed on a regular basis.
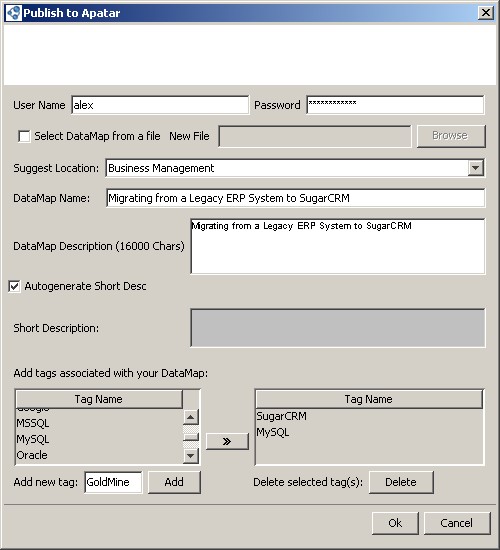 Publishing your DataMap to Apatar’s repository
Publishing your DataMap to Apatar’s repository
Integration best practices
So, what can be done to solve the most common integration challenges and avoid typical mistakes?
1. Formalize data schemas
Custom objects, data fields, and tables created by individuals should be documented and align with all applications and processes within the integration environment, as well as be visible to other users. To enforce data standardization, it is recommended to start with defining initial data schemas and setting how the processes of subsequent changes to the data schemas will be made in the future.
2. Update the information
Information should be updated on a regular basis or, if possible, in real time. Out-of-date views are useless, so keep an eye on this.
3. Maintain the integration
Even the most defined integration process requires maintenance. New tables may be added, data structures may change, and so on. If there’s no one to take responsibility for the long-term success of the integration initiative, the process may fail sooner or later. Having no plan or budget for an ongoing integration is a mistake, which may become expensive to fix.
4. Go open source
The truth is that most data integration projects in today’s enterprises never get built. The return on investment on these small projects is simply too low to justify bringing in expensive middleware. That’s why you may consider using commercially supported open-source tools for your integration projects. You may want to consider Apatar’s application to design and orchestrate data integration processes, as well as MySQL database to host data warehouse and staging tables.
5. Verify and clean up the data
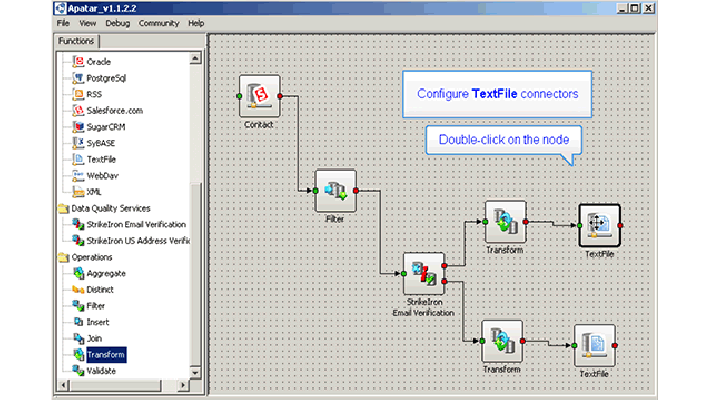
You also need to perform data cleansing and verification required by your business and industry. For instance, it is critical to check the names, addresses, and e-mail details of your prospects and customers. Each industry will have its own baseline, inputs/outputs, and best practices for such data quality management. Mature data integration tools provide data cleansing capabilities. Consider the Name and Address Verification, as well as the E-mail Verification features embedded into the Apatar Data Integration application.
6. Transform raw data into business information
Business users are typically looking for useful information that can be applied across the enterprise and provide business decision-making. That’s why raw data needs to be aggregated, filtered, enriched, and summarized. In order to enable business analytics, executives must be involved in designing the schemes of raw data transformations, as well as creating appropriate business data models and views.
7. Keep to consistency to provide valuable data
Make sure that the output data is consistent and reliable. For example, a company may need a single view of customers, products, employees, or boards of directors. Sometimes it becomes a challenge to obtain an agreement on the criteria of these views.
8. Stick to business value
Finally, don’t forget that the integration processes should bring value and align with your business processes. There’s no use creating even a complex integration model, if it doesn’t increase your revenue or, at least, save you money and time.
Integration with SugarCRM may be easier than you think. With tools like Apatar, users can accelerate data integration by using a visual interface and mapping capabilities, which provide even a non-programmer with all of the means to plan, design, and execute various integration, migration, and replication jobs. On top of that, scheduling capabilities enable one-time or recurring transformation of information between SugarCRM and third-party systems. Many integration tools like this provide additional data quality features, as well—helping to filter data, deduplicate it, enhance missing fields/records, etc.
With a variety of today’s data management solutions, the business user has a powerful toolset not only to manage data streams within the enterprise, but to join data with the web, keep it safely in SugarCRM, and exchange information with partners globally.
Further reading
- What Is Apatar Open Source Data Integration?
- Reducing ETL and Data Integration Costs by 80% with Open Source
- Apatar Data Integration Web Demos