
NoSQL Comparison 2021: Couchbase Server, MongoDB, and Cassandra (DataStax)
")
What was compared?
Today, we are announcing the results of our latest research paper that compares the performance of three NoSQL databases: Couchbase Server v6.60, MongoDB v4.2.11, and DataStax Enterprise v6.8.3 (Cassandra). The evaluation was conducted on three different cluster configurations—4, 10, and 20 nodes—as well as under four different workloads.
![]()
Couchbase Server is both a document-oriented and a key-value distributed NoSQL database. It guarantees high performance with a built-in object-level cache, a SQL-like query language, asynchronous replication, ACID transactions, and data persistence. The database is designed to automatically scale resources such as CPU and RAM depending on the workload.
![]()
MongoDB is a document-oriented NoSQL database. It has extensive support for a variety of secondary indexes and API-based ad-hoc queries, as well as strong features for manipulating JSON documents. The database uses a separate and incremental approach to data replication and partitioning that occur as completely independent processes.
![]()
DataStax Enterprise (Cassandra) is a wide-column store designed to handle large amounts of data across multiple commodity servers, providing high availability with no single point of failure.
In this blog post, we share the performance results of the databases under a short-range workload.
Workload with 95% scans and 5% updates
A short-range scan workload simulates threaded conversations typical in an e-commerce application, where each scan goes through the posts in a given thread. The workload was executed with the following settings:
- The scan/update ratio was 95%–5%.
- The size of a data set was scaled in accordance with the cluster size: 50 million records on a 4-node cluster, 100 million records on a 10-node cluster, and 250 million records on a 20-node cluster. Each record is 1 KB in size, consisting of 10 fields and a key.
- The maximum scan length reached 100 records.
- The Zipfian request distribution was used.
- Uniform was used as a scan length distribution.
In real-world situations, an example of a scan operation in an e-commerce app is viewing a product catalog. In its turn, an update operation can be manipulating an existing product in the catalog—adding a model in a new color or changing the price, for instance.
The size of the data sets in our tests for the 4-node, 10-node, and 20-node clusters were 50 GB, 100 GB, and 250 GB, respectively. Our findings may prove useful to organizations that are evaluating a NoSQL system for an existing data set or optimizing a data array size to fit the database in use.
The following queries were used to perform the short-range scan workload.
Short-range scan performance results
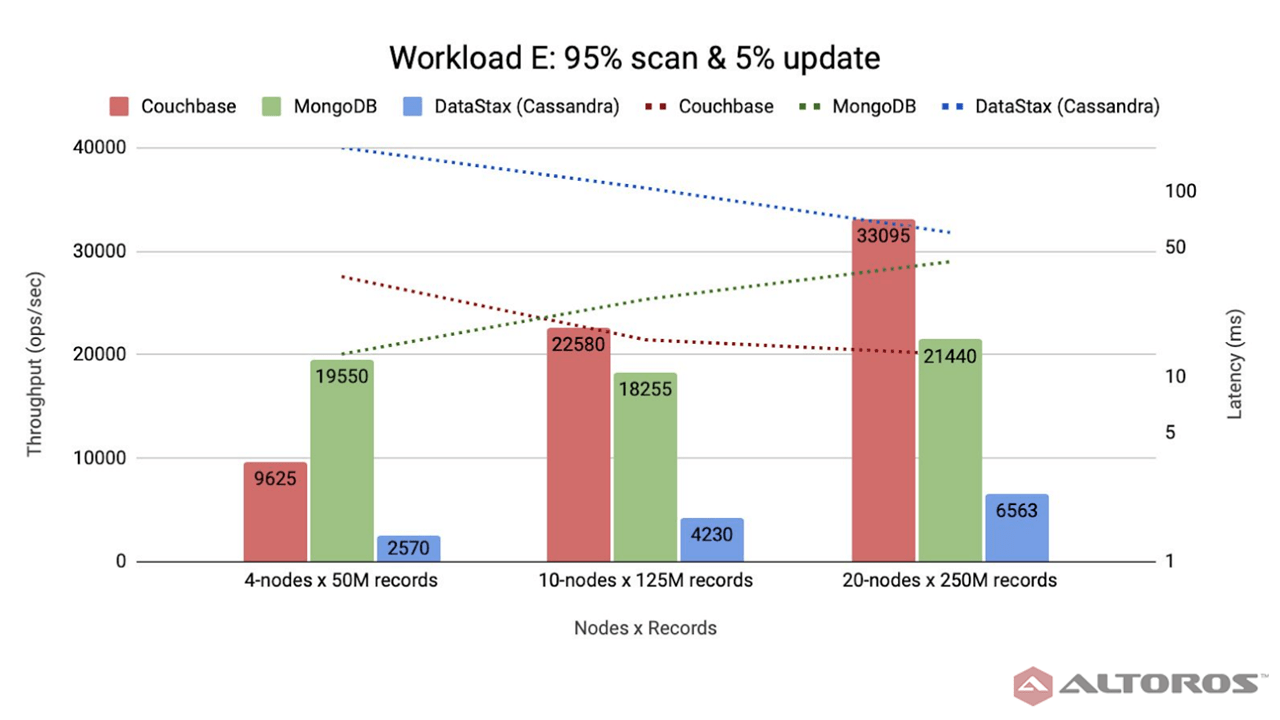
Couchbase demonstrated great scalability with the linear growth of throughput that was proportional to the number of cluster nodes: from 9,625 ops/sec on a 4-node cluster to 22,580 ops/sec on a 10-node cluster. On a 20-node cluster, the throughput reached 33,095 ops/sec, which is about 46% more than on a 10-node cluster, with the request latency decreasing from 34 ms to about 13 ms, due to the usage of a primary index and replication of the Index Service. Request latency refers to the real-time delay in viewing a catalog or updating a product.
 Throughput and latency for the short-range scan workload
Throughput and latency for the short-range scan workloadMongoDB similarly scaled from 18,255 ops/sec to 21,440 ops/sec. The results were comparatively the same regardless of cluster and data set sizes. MongoDB performed better than Couchbase on a 4-node cluster, but lower on 10- and 20-node clusters.
“Based on our tests, Couchbase scales better than MongoDB on larger clusters. Couchbase uses a peer-to-peer structure, enabling direct access to nodes. Meanwhile, MongoDB has master-slave relationships, where certain operations have to call Mongoose, an Object Document Mapper, and a configuration server to access a node, creating a queue.” —Artsiom Yudovin, Altoros
Cassandra did not perform so well with 2,570 ops/sec on a 4-node cluster, 4,230 ops/sec on a 10-node cluster, and 6,563 ops/sec on a 20-node cluster. However, Cassandra achieved a linear performance increase across all clusters and data sets. This can be explained by the fact that coordinator nodes send scan requests to other nodes in the cluster responsible for specific token ranges. The more nodes a cluster has, the less data falls in the target range on each node, thus the less data each node has to return. This resulted in reduced per-node request processing time. As the coordinator sends the requests in parallel, the overall request processing time depends on each cluster node request latency which decreases with cluster growth. This is proven by the gradual decrease of request latencies from 173 ms on a 4-node cluster to 104 ms on a 10-node cluster and 63 ms on a 20-node cluster.
To sum up, MongoDB performed better than Couchbase on relatively small-sized clusters and data sets, but remained flat irrespective of the cluster size. On the other hand, Couchbase outscaled and outperformed MongoDB on 10- and 20-node clusters showing linear throughput growth across data sets of 125 and 250 million records. MongoDB showed the ability to handle the increasing amount of data with the throughput remaining the same. Cassandra had linear performance growth, but is lagging behind Couchbase and MongoDB in terms of performance on scan and update operations.
Unlike MondoDB and Couchbase, which are document-oriented databases, Cassandra is a wide-column store. Its structure and architecture design are better suited for write and read operations that in a real-life scenario correspond to creating a new product or viewing a particular product out of the whole catalogue.
To learn more about how each database was configured, as well as how each performed in the evaluation, check out our full report. In addition to a short-range scan, the databases were tested across the update-heavy (50% reads and 50% updates), pagination (a query with a single filtering option to which an offset and a limit are applied), and JOIN (with grouping and ordering applied) workloads.
Download the full report here.
Further reading
- Performance Evaluation of NoSQL Databases 2021: Couchbase Server, DataStax Enterprise (Cassandra), and MongoDB
- Performance Evaluation of NoSQL Databases as a Service: Couchbase Capella, MongoDB Atlas, and Amazon DynamoDB
- Comparing Database Query Languages in MySQL, Couchbase, and MongoDB
edited by Sophia Turol and Alex Khizhniak.

")
")
