Logical Graphs: Native Control Flow Operations in TensorFlow

An example of control flow
Sometimes, your models need to perform different computations depending on intermediate results or random chance. However, placing this sort of logic in the Python layer adds extra complexity and overhead to your code. TensorFlow provides a number of native operations to help create graphs with built-in logical branching structure. At TensorBeat 2017, Sam Abrahams, a machine learning engineer at Metis, demonstrated how to make use of them.
In computer science, control flow defines the order in which individual statements, instructions, or function calls are executed or evaluated. Sam started his talk with highlighting the challenges of executing control flow operations on a sample graph (see the icon above).

For instance, we need to run one of the functions (B or C) based on the other function’s (A) value. Natively, this can be done simply with if/else and multiple session runs. However, there is little sense in doing so, as we simply fetch a value to feed it right back in.
Furthermore, the Python logic isn’t represented in the graph.

“If we export the graph, you are not going to actually see those ‘if/else’ statements, we will lose the structure.” —Sam Abrahams, Metis
So, what one needs is a native logic gate.
Native control flow
TensorFlow offers several operations for enabling native control flow:
- Dependencies: tf.control_dependencies, tf.group, and tf.tuple
- Conditional statements: tf.cond and tf.case
- Loops: tf.while_loop
Why would anyone even bother with enabling native control flow?
Efficiency. While passing data to/from the Python layer is somewhat slow, one would naturally want to run graph end-to-end as fast as possible, as well as take advantage of pipelining (e.g., queues). With native control flow, data transfer overhead is minimized.
Flexibility. Static graphs can be empowered with dynamic components. Better decoupling comes through storing the model logic in a single place. Changes can be introduced to the graph without any impact on a training loop. So, with native control flow, graph logic is self-contained.

“One of the things why people like using Torch over TensorFlow is that it uses dynamic graphs, so you can change the graph at a run time. TensorFlow—for its capacity, but it doesn’t mean we can’t have a dynamic graph, though it’s statically defined.” —Sam Abrahams, Metis
Compatibility. One can debug and inspect via TensorBoard. Seamless deployment is ensured with TensorFlow Serving. One can make use of auto-differentiation, queues, and pipelining.
Control dependencies
TensorFlow keeps track of each operation’s dependencies and uses them to schedule computation. What it means is that an operation can only be executed once its dependencies have completed. So, any two eligible operations with their dependencies complete can run in any order.
For instance, we have the initial nodes with no dependencies that may run in random order. It may lead to a race condition and turn into an issue as operations are executed not in the way you expected them to.

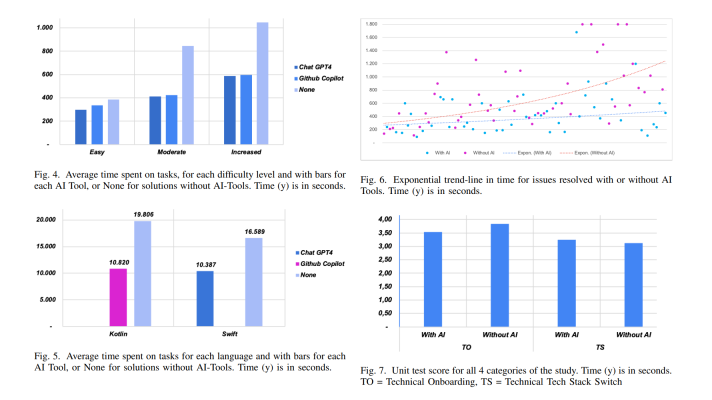
What one gets is a variable changed in the course of one operation, while the other operation reads from this very variable. The code then may look like this.
var = tf.Variable(…) top = var * 2 bot = var.assign_add(2) out = top + bot
Being non-deterministic, the execution order may lead to unexpected behavior. How to tackle the problem?
On the one hand, TensorFlow automatically determines dependencies. On the other, a user can also define additional dependencies through forcing the specified operations to complete first. A developer can control the order depending on needs.
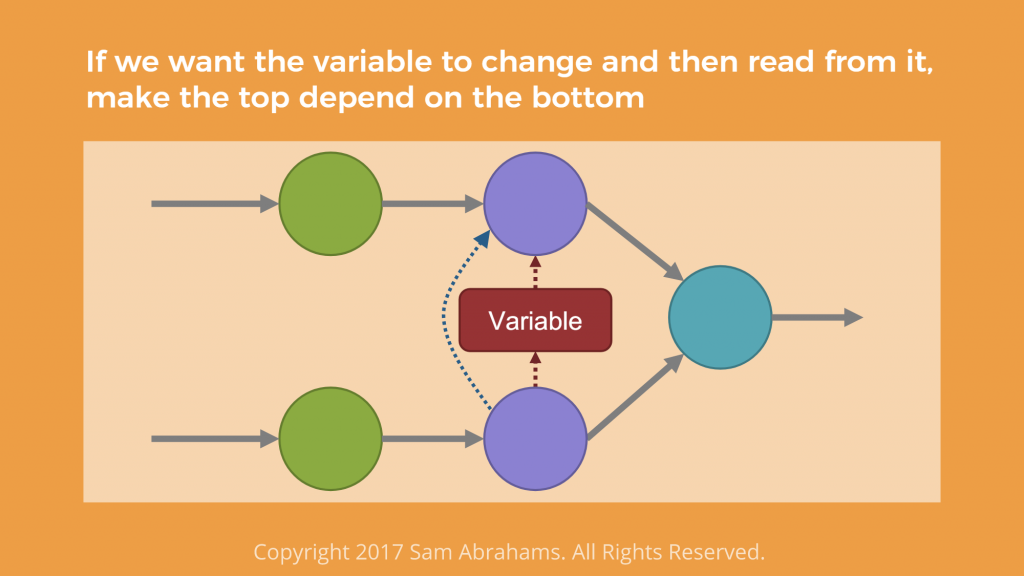
For example, if one wants to change a variable and then read from it, one has to make the top operation depend on the bottom one. In case one needs to read a variable before it is altered, one has to establish a vice versa dependency. This is done by employing tf.control_dependencies.
# Force bot to wait for top
var = tf.Variable(…)
top = var * 2
with tf.control_dependencies ([top]):
bot = var.assign_add(2)
out = top + botYou need to define a list of the necessary dependencies as control_inputs, while operations are defined as gain those dependencies in the with block.

Where can this be applied? In addition to enforcing the execution order, one may group operations (run a bunch of them in a single handle) and add assertion statement (build exceptions into a graph).
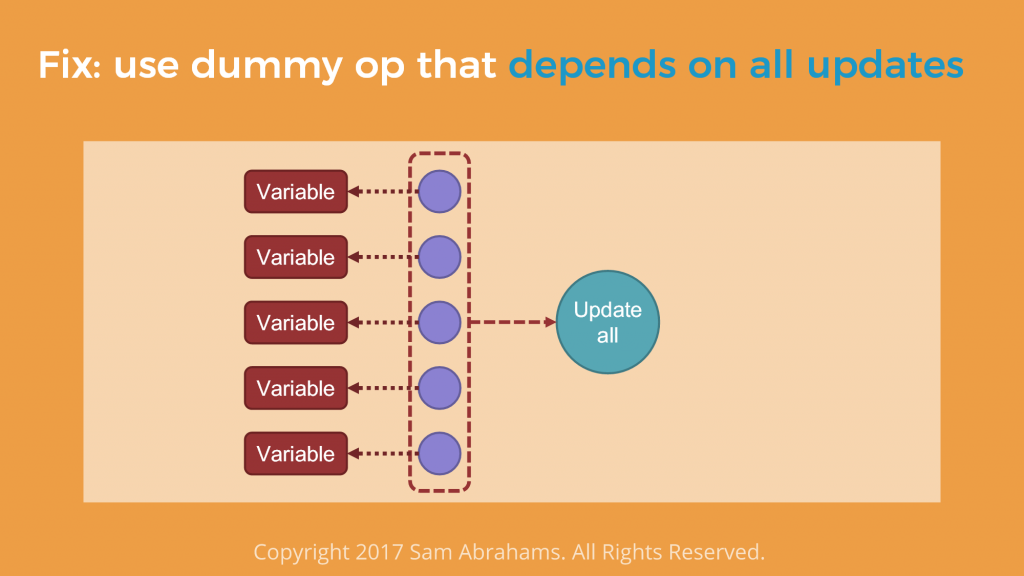
Why grouping? As many variable are updated with separate operations, “running each update operation separately is a pain,” according to Sam. One may find a operation that depends on all the updates and use _ = sess.run(update_all) to get simpler and more semantic code.
tf.group automates the process. It uses tf.control_dependencies under the hood and features a possibility to group operations by device (e.g., CPU, GPU1, GPU2, etc.).
updates = [update1, update2…] update_all = tf.group(*updates)
Sam then moved on to demonstrating assertions, conditional logic, and while loops—providing a view on various graphs and more code samples.
Here are the presentation slides and the source code used during the session.
Want details? Watch the video!
Further reading
- Visualizing TensorFlow Graphs with TensorBoard
- Monitoring and Visualizing TensorFlow Operations in Real Time with Guild AI
- Basic Concepts and Manipulations with TensorFlow
About the expert
Sam Abrahams is a machine-learning engineer and educator, specializing in deep learning implementations and deployments. He is also a long-time TensorFlow contributor and a co-author of “TensorFlow for Machine Intelligence.” As a TensorFlow expert, Sam is experienced in teaching technical concepts and communicating effectively to people of varied technical skill and knowledge. You can also check out Sam’s GitHub profile .