A common problem for researchers who work on genome analysis is the need to store and process terabytes of data fast. Deployed on Amazon public cloud, the system was powered by Amazon Web Services and Amazon EMR. With this optimal solution our customer was able to process 150 GB of genome sequencing data within 24 hours and in the most cost-efficient manner.
Apart from building an algorithm for detecting SNP, we were to determine what hardware configuration could provide the required data processing speed.
The customer helps scientists and laboratories to conduct research and experiments in the field of life sciences. Their key services include next-generation sequencing, bioanalytical and mass spectrometry, as well as DNA sequencing. The customer turned to Altoros to develop a solution that would detect SNP in digitized DNA sequences saved in the FASTA/FASTQ format easier and less time-consuming.
The team completed the following tasks for this project:
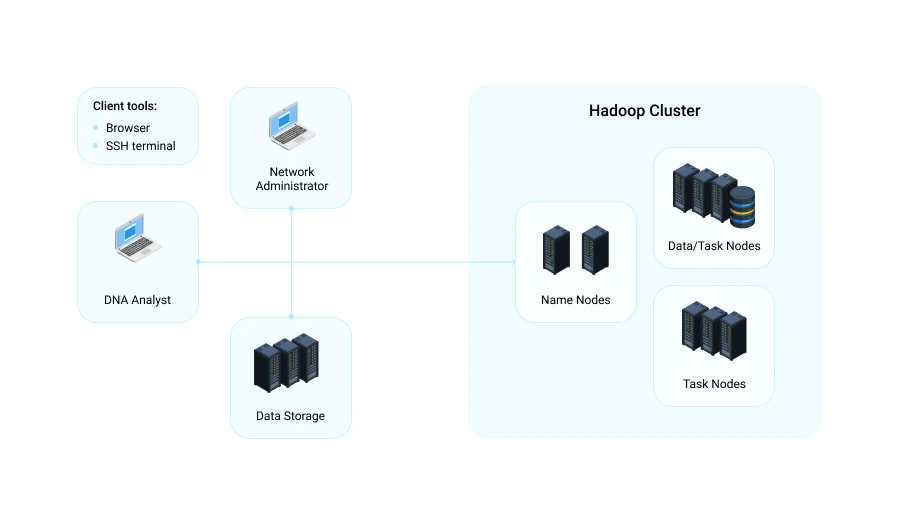
With the help of the automated SNP detection system, the biological laboratory of our customer managed to process 150 GB of genome sequence data within 24 hours at minimum cost. We started with development of a prototype to test the possible deployment options and make sure the functionality works correctly. The system for SNP detection was later installed on the customer’s private distributed infrastructure and data processing was performed with Apache Hadoop.
Server platforms
Linux, Amazon Web Services
Client platform/Application server
Internet Explorer, Firefox, Safari, Chrome
Programming languages
Perl, Java, Bash
Technologies
Map / Reduce, Java, HTML, Apache Hadoop, Amazon EMR
Databases
HDFS
Altoros is committed to protecting the privacy rights of data subjects.
“Altoros”, “we,” and “us” refer to Altoros Americas LLC, Altoros Norge AS, Altoros Finland OY, Altoros A.S., and Altoros Poland (Check out our contact information.) We offer a wide range of software development services. We refer to all of these products, together with our other services and websites as "Services" in this policy.
This policy refers to the data we collect when you use our services or communicate with us. Examples include visiting our website, downloading our white papers and other materials, responding to our e-mails, and attending our events. This policy also explains your rights with respect to data we collect about you. Data privacy of our employees is regulated in separate local act and is not regulated by this policy.
Your information is controlled by Altoros. If you have any questions or concerns about how your information is handled, please direct an inquiry to us at dpo@altoros.com. Aleksey Lekontsev is our Data Protection Officer (DPO), with overall responsibility for the day-to-day implementation of this policy.
If you do not agree with this policy, please do not access or use our services, or interact with any other aspect of our business.
When you visit our website, we collect usage statistics and other data, which helps us to estimate the efficiency of the content delivered. Processing data gathered from our website also helps us to provide better user experience and improve the products and services we offer. We collect information through the use of “cookies,” scripts, tags, Local Shared Objects (Flash cookies), web beacons, and other related methods.
HTTP cookie is a small piece of data that we send to your browser when you visit our website. After your computer accepts it or “takes the cookie” it is stored on your computer as an identification tag. Cookies are generally employed to measure website usage (e.g., a number of visitors and the duration of a visit) and efficiency (e.g., topics of interest to our visitors). Cookied can also used to personalize a user experience on our website. If necessary, users can turn off cookies via browser settings
Altoros and third-party providers we partner with (e.g., our advertising and analytics partners) use cookies and other tracking tools to identify users across different services and devices and ensure better user experience. Please see the list of them below.
The services outlined below help us to monitor and analyze both web traffic and user behavior.
User data may be employed to customize advertising deliverables, such as banners and any other types of advertisements to promote our services. Sometimes, these marketing deliverables are developed based on user preferences. However, not all personal data is used for this purpose. Some of the services provided by Altoros may use cookies to identify users. The behavioral retargeting technique may also be used to display advertisements tailored to user preferences and online behavior, including outside Altoros websites. For more information, please check the privacy policies of the relevant services.
In addition to advertising partners and analytics partners mentioned above, we are using widgets, which act as an intermediary between third-party websites (Facebook, Twitter, LinkedIn, etc.) and our website and allow us to provide additional information about us or our services or authorize you as our website user to share content on third-party websites.
Altoros is gathering data via this service with a view to improve the development of our products or services. Data gathering is conducted on the basis of our or third party’s legitimate interests, or with your consent.
User data collected allow Altoros to provide our Services and is employed in a variety of our activities which correspond our legitimate interest, including:
We set a retention period for your data—collected from our websites—to 6 years. We gather data to improve our services and the products we deliver. The retention period from our partners is set forth by them in their privacy policies.
We do not transfer the gathered data to third parties, apart from the cases described in General data processing section or in this Section, as well as cases stipulated in our third partners privacy policies.
When you fill out any of the forms located at our websites, you share the following information with us:
The information about the request is transferred to our CRM or Hubspot. Later, it may be used to contact you with something relevant to your initial request, provide further information related to the topic you requested, and deliver quality service.
By sharing personal information with us, you are giving consent for us to rightfully use your data for the following business purposes:
All the information gathered via contact forms is processed by the following services:
If you fill out a contact form to get an expert’s take on your project or to get familiar with the services our company delivers, we process your data in order to enter into a contract and to comply with our contractual obligations (to render Services), or answer to your request. This way, we may use your personal information to provide services to you, as well as process transactions related to the services you inquired from us. For example, we may use your name or an e-mail address to send an invoice or to establish communication throughout the whole service delivery life cycle. We may also use your personal information you shared with us to connect you with other of our team members seeking your subject matter expertise. In case you use multiple services offered by our company, we may analyze your personal information and your online behavior on our resources to deliver an integrated experience. For example, to simplify your search across a variety of our services to find a particular one or to suggest relevant product information as you navigate across our websites.
With an aim to enhance our productivity and improve our collaboration—under our legitimate interest—we may use your personal data (e.g., an e-mail, name, job title, or activity taken on our resources) to provide information we believe may be of interest to you. Additionally, we may store the history of our communication for the legitimate purposes of maintaining customer relations and/or service delivery, as well as we may maintain and support the system, in which we store collected data.
If you fill out contact forms for any other purpose, including the download of white papers or to request a demo, we process data with a legitimate interest to prevent spam and restrict direct marketing of third-party companies. Our interactions are aimed at driving engagement and maximizing value you get through our services.These interactions may include information about our new commercial offers, white papers, newsletters, content, and events we believe may be relevant to you.
We set a retention period for your data collected from contact forms on our websites to 6 years. This data may be further used to contact you if we want to send you anything relevant to your initial request (e.g., updated information on the white papers you downloaded from our websites).
We do not transfer data to third parties, apart from the cases described in the General data processing section and this section.
When you answer a question and/or providing information via chatbot, you share the following information with us:
The information gathered is transferred to our CRM or Hubspot. Later, it may be used to contact you with something relevant to your initial request, provide further information related to the topic you requested, and deliver quality service.
By sharing personal information with us, you are giving consent for us to rightfully use and process in any way your data, including for the following business purposes:
All the information gathered via chatbot is processed by the following services:
If you share personal data via chatbot to get an expert’s take on your project or to get familiar with the services our company delivers, we process your data in order to enter into a contract and to comply with our contractual obligations (to render Services), or answer to your request. This way, we may use your personal information to provide services to you, as well as process transactions related to the services you inquired from us. For example, we may use your name or an e-mail address to send an invoice or to establish communication throughout the whole service delivery life cycle. We may also use your personal information you shared with us to connect you with other of our team members seeking your subject matter expertise. In case you use multiple services offered by our company, we may analyze your personal information and your online behavior on our resources to deliver an integrated experience. For example, to simplify your search across a variety of our services to find a particular one or to suggest relevant product information as you navigate across our websites.
With an aim to enhance our productivity and improve our collaboration—under our legitimate interest—we may use your personal data (e.g., an e-mail, name, job title, or activity taken on our resources) to provide information we believe may be of interest to you. Additionally, we may store the history of our communication for the legitimate purposes of maintaining customer relations and/or service delivery, as well as we may maintain and support the system, in which we store collected data.
If you share personal data via chatbot for any other purpose we process data with a legitimate interest to prevent spam and restrict direct marketing of third-party companies. Our interactions are aimed at driving engagement and maximizing value you get through our services.These interactions may include information about our new commercial offers, white papers, newsletters, content, and events we believe may be relevant to you.
We set a retention period for your data collected from communication with us via chatbot to 6 years. This data may be further used to contact you if we want to send you anything relevant to your initial request (e.g., updated information on your initial request, etc).
We do not transfer data to third parties, apart from the cases described in the General data processing section and this section.
When you interact with us via any other means and tools, we gather the following information about you:
The information about a customer call is stored in our internal system and includes a full call recording (starting the moment a connection was established), a voice recording if any available, a phone number, and a call duration.
All the requests acquired via e-mail are stored within a business Gmail account of Altoros located at the Google’s server. The information about the request is further transferred and stored in internal CRM either by employees of Altoros manually or automatically for further processing according to our purposes. We may maintain and support the system, in which we store collected data.
When you contact us via any other means to get an expert’s take on your project / our services or to make any kind of a request, we process your data in order to enter into a contract, to comply with our contractual obligations (to render Services), or answer to your request.
This way, we may use your personal information to provide services to you, as well as process transactions related to the services you inquired from us. For example, we may use your name or an e-mail address to send an invoice or to establish communication throughout the whole service delivery life cycle. We may also use your personal information you shared with us to connect you with other of our team members seeking your subject matter expertise. In case you use multiple services offered by our company, we may analyze your personal information and your online behavior on our resources to deliver an integrated experience. For example, to simplify your search across a variety of our services to find a particular one or to suggest relevant product information as you navigate across our websites. With an aim to enhance our productivity and improve our collaboration, what is our legitimate interest, we may use your personal data—such as an an e-mail, name, job title, or activity taken on our resources—to provide information we believe may be of interest to you. Additionally, we may store the history of our communication for the legitimate purposes of maintaining customer relations and/or service delivery.
If you communicate with us for any other purpose we process data with a legitimate interest to prevent spam and restrict direct marketing of third-party companies. Our interactions are aimed at driving engagement and maximizing value you get through our services.These interactions may include information about our new commercial offers, white papers, newsletters, content, and events we believe may be relevant to you or your initial request.
We set a retention period the data collected to 6 years. This data may be further used to contact you if we we want to send you anything relevant to your initial request.
We do not share data with third parties, apart from the cases described in the General data processing section and cases stipulated in our third partners privacy policies.
If you are our customer, you have already shared the following information with us to process:
We use personal data submitted for the following purposes:
To fulfill / comply with our contractual obligations or answer to your request. For example, we use your name or an e-mail in contact to send invoice or communicate with you at any stage of the service delivery life cycle. This way, we may use your personal information to provide services to you, as well as process transactions related to the services you inquired from us. For example, we may use your name or an e-mail address to send an invoice or to establish communication throughout the whole service delivery life cycle. We may also use your personal information you shared with us to connect you with other of our team members seeking your subject matter expertise. In case you use multiple services offered by our company, we may analyze your personal information and your online behavior on our resources to deliver an integrated experience. For example, to simplify your search across a variety of our services to find a particular one or to suggest relevant product information as you navigate across our websites.
With an aim to enhance our productivity and improve our collaboration, what is our legitimate interest , we may use your personal data—such as an an e-mail, name, job title, or activity taken on our resources — to provide information we believe may be of interest to you and communicate with you in order to get your consent for a possibility to contact you regarding any other services you might be interested in. Additionally, we may store the history of our communication for the legitimate purposes of maintaining customer relations and/or service delivery as well as to maintain and support our CRM system and related activities.
We set retention period for your data about our customer to 6 years from last Service delivery. We keep it to be able to reach you when we have something relevant to your initial request (for example, updated information on related services, news, events, updates, etc).
We do not share data with third parties, apart from the cases described in the General data processing section or in this section.
When you register or attend an event organized by Altoros, you share the following information with us:
Data about users who filled out a contact form is stored in our internal CRM, which shall be maintained and supported, and Hubspot (HubSpot, Inc. Privacy Policy) — by our employees manually or automatically on receiving a contact form — for further processing a customer request and providing relevant services, as well as developing recommendations on improving the services we deliver.
To share contact information, as well as information related to the events and services that may be of interest to a customer, Altoros may use the following:
To provide users with a possibility to register to an event organized by Altoros and acquire tickets, we use Eventbrite (Privacy Policy).
To store and share information about attendees of the events organized by Altoros, as well as to improve all the online activities related to such events, Altoros makes use of the services by Google (Privacy Policy) and Microsoft (Privacy Policy)
To enable marketing activities and share information about relevant services provided by our company, we use remarketing and advertising instruments available through Google Adwords (Privacy Policy).
To build a strong community around the events organized by Altoros and to interact with those interested in our services, we use Meetup.com (Privacy Policy).
To optimize internal processes and improve a communication channels, we may use Atlassian (Privacy Policy) and Trello (Privacy Policy).
To establish efficient communication with customers about our services, we may use the following data:
We set retention period for your data about our customer to 6 years from last event you have been registered. We keep it to be able to reach you when we have something relevant to your initial request (for example, updated information on calls, e-mail, etc.).
We do not share personal data with third parties, apart from the cases, which imply Altoros is to provide a list of registrars to the organizer of the event with a view to ensure an acceptable level of organization and security.
Our processing means any operation or set of operations which is performed on personal data or on sets of personal data, such as collection, recording, organisation, structuring, storage, adaptation or alteration, retrieval, consultation, use, disclosure by transmission, dissemination or otherwise making available, alignment or combination, restriction, erasure or destruction, support, maintenance, etc.
The retention period of storing data varies on its type. As the retention period expires, we either delete or anonymize personal data collected. In case data was transferred to a backup storage and, therefore, cannot be deleted, we continue to store it in a secure fashion, but do not use it for any purpose. In all the other cases, we proceed with the deletion of data.
The information available through our websites that was collected by third parties is subject to the privacy policies of these third parties. In this case, the retention period of storing data is also subject to the privacy policies of these third parties.
To prevent spam, we keep track of spam and swindler accounts, which may be blocked through filtering at the server level.
Request containing words, which may be treated as spam-related or which may promote the distribution of misleading information, are filtered at the server level, as well as by company employees manually.
Data storage on our servers, as well as on cloud services provided by Google, Amazon, Hubspot and on other services, inter alia Drift.com or other stipulated in this policy.
We do not make automated decisions, including profiling.
Below, you will find a list of the rights you are subject to. Please note that some of the enlisted rights may be limited for the requests, which expose personal information of another individual who is subject to the very same rights for privacy. In such a case, we will not be able to satisfy your request for data deletion if it contains information we are eligible to keep by law.
The right to be informed and to access information. You have legal rights to access your personal data, as well as request if we use this data for any purpose. Complying with our general policy, we will provide you with a free copy of your personal information in use within a month after we receive your request. We will send your information in use via a password-protected PDF file. For excessive or repeated requests, we are eligible to charge a fee. In case of numerous or complex requests, we are eligible to prolong our response time by as much as two additional months. Under such circumstances, you will be informed about the reasons of these extensions. In case, we refuse to address a particular request, we will explain why it happens and provide you with a list of further actions you are eligible to proceed. If shall you wish to take further action, we will require two trusted IDs from you to prove your identity. You may forward your requests to our Data Protection Officer (dpo@altoros.com). Please provide information about the nature of your request to help us process your enquiry.
The right for rectification. In case you believe, we store any of your personal data, which is incorrect or incomplete, you may request us to correct or supplement it. You also have the right to introduce changes to your information by logging into your account with us.
The right to erase, or "the right to be forgotten". Under this principle, you may request us to delete or remove your personal data if there is no solid reason for your data continued processing. If you would like us to remove you from our database, please e-mail dpo@altoros.com. The right to be forgotten may be brought into force under the following reasons:
The right to restrict processing. Under this right, you may request us to limit processing your personal data. In this regard, we are eligible to store information that is sufficient to identify which data you want to be blocked, but cannot process it further. The right to restrict processing applies to the following cases:
If we have disclosed your personal data in question to third parties, we will inform them about the restriction on data processing, unless it is impossible or involves disproportionate effort to do so. We will inform you if we decide to lift a restriction on data processing.
The right to object. You are eligible to object to processing your personal data based on legitimate interests (including profiling) and direct marketing (including profiling). The objection must be on “grounds relating to his or her particular situation.” We will inform you of your right to object in the first communication you receive from us. We will stop processing your personal data for direct marketing purposes, as soon as we receive an objection.
The right to data portability. You are eligible to obtain your personal data, which is processed by Altoros, to use it for your own purposes. It means you have the right to receive your personal data—that you have shared with us—in a structured machine readable format, so you can further to transfer the data to a different data controller. This right applies in the following circumstances:
Withdrawal of consent. If we process your personal data based on your consent (as indicated at the time of collection of such data), you have the right to withdraw your consent at any point in time. Please note, that if you exercise this right, you may have to then provide your consent on a case-by-case basis for the use or disclosure of certain personal data, if such use or disclosure is necessary to enable you to utilize some or all of our services.
Right to file a complaint. You have the right to file a complaint about manipulations applied to your data by Altoros with the supervisory authority of your country or a European Union Member State.
We use data hosting service providers in the United States and Ireland to store the information we collect, and we do use extra technical measures to secure your data.
These measures include without limitation: data encryption, password-protected access to personal information, limited access to sensitive data, encrypted transfer of sensitive data (HTTPS, IPSec, TLS, PPTP, and SSH) firewalls and VPN, intrusion detection, and antivirus on all the production servers.
The data collected by third party providers is protected by them and is subject to their terms and privacy policies.
The data collected on our websites by Altoros, as well as the data, which you entrust us under NDAs and contracts, is protected by us. We follow the technical requirements of GDPR and ensure security standards are met without exception.
Though we implement safeguards designed to protect your information, no security system is impenetrable and due to the inherent nature of the Internet, we cannot guarantee that data is absolutely safe from intrusion by others during transmission through the Internet, or while stored on our systems, or otherwise in our care.
We collect information worldwide and primarily store this information in the United States and Ireland. We transfer, process, and store your information outside of your country of residence across regions wherever we or our third-party service providers operate for the purpose of delivering our services to you and for maintenance and support purposes. Whenever we transfer your information, we take precaution measures to protect it. Thus, the data by third party providers may be transferred to different countries globally for processing. These data transfers fall under the terms and privacy policies of these providers and (or) under standart data protection clauses.
The data collected by Altoros may be transferred across our offices. Headquartered in the USA, Altoros is an international company with offices in Norway, Finland, Argentina (there is adequacy decision of the European Commission), and Poland. Some countries may not have equivalent privacy and data protection laws as the laws of many of the countries where our customers and users are based. When we share information about you within and among Altoros branches, we make use of standard contractual data protection clauses.
We may supplement or amend this policy by additional policies and guidelines from time to time. We will post any privacy policy changes on this page. We encourage you to review our privacy policy whenever you use our services to stay informed about our data practices and the ways you can help to protect your privacy.
Our services are not directed to individuals under 16. We do not knowingly collect personal information from individuals under 16. If we become aware that an individual under 16 has provided us with personal information, we will take measures to delete such information.
If you disagree with any changes to this privacy policy, you will need to stop using our services.
Your information is controlled by Altoros Americas LLC and Altoros Norge AS. If you have questions or concerns about how your information is handled, please direct your inquiry to Altoros Norge AS, which we have appointed as responsible for facilitating such inquiries or, if you are a resident of the European Economic Area, please contact our EU Representative.
EEA Representative:
Altoros Norge AS.
Kongens gate 3
0153 Oslo, Norway
Phone: +47 21 92 93 00
Org. num.: 894 684 992
E-Mail: dpo@altoros.com